 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Continuous Dynamic Multi-Objective Optimization: Survey and Generalized Test Suite
Jan 04, 2026Dynamic multi-objective optimization (DMOO) has recently attracted increasing interest from both academic researchers and engineering practitioners, as numerous real-world applications that evolve over time can be naturally formulated as dynamic multi-objective optimization problems (DMOPs). This growing trend necessitates advanced benchmarks for the rigorous evaluation of optimization algorithms under realistic conditions. This paper introduces a comprehensive and principled framework for constructing highly realistic and challenging DMOO benchmarks. The proposed framework features several novel components: a generalized formulation that allows the Pareto-optimal Set (PS) to change on hypersurfaces, a mechanism for creating controlled variable contribution imbalances to generate heterogeneous landscapes, and dynamic rotation matrices for inducing time-varying variable interactions and non-separability. Furthermore, we incorporate a temporal perturbation mechanism to simulate irregular environmental changes and propose a generalized time-linkage mechanism that systematically embeds historical solution quality into future problems, thereby capturing critical real-world phenomena such as error accumulation and time-deception. Extensive experimental results validate the effectiveness of the proposed framework, demonstrating its superiority over conventional benchmarks in terms of realism, complexity, and its capability for discriminating state-of-the-art algorithmic performance. This work establishes a new standard for dynamic multi-objective optimization benchmarking, providing a powerful tool for the development and evaluation of next-generation algorithms capable of addressing the complexities of real-world dynamic systems.
HI-TransPA: Hearing Impairments Translation Personal Assistant
Nov 14, 2025Hearing-impaired individuals often face significant barriers in daily communication due to the inherent challenges of producing clear speech. To address this, we introduce the Omni-Model paradigm into assistive technology and present HI-TransPA, an instruction-driven audio-visual personal assistant. The model fuses indistinct speech with lip dynamics, enabling both translation and dialogue within a single multimodal framework. To address the distinctive pronunciation patterns of hearing-impaired speech and the limited adaptability of existing models, we develop a multimodal preprocessing and curation pipeline that detects facial landmarks, stabilizes the lip region, and quantitatively evaluates sample quality. These quality scores guide a curriculum learning strategy that first trains on clean, high-confidence samples and progressively incorporates harder cases to strengthen model robustness. Architecturally, we employs a novel unified 3D-Resampler to efficiently encode the lip dynamics, which is critical for accurate interpretation. Experiments on purpose-built HI-Dialogue dataset show that HI-TransPA achieves state-of-the-art performance in both literal accuracy and semantic fidelity. Our work establishes a foundation for applying Omni-Models to assistive communication technology, providing an end-to-end modeling framework and essential processing tools for future research.
An Experimental Study on Joint Modeling for Sound Event Localization and Detection with Source Distance Estimation
Jan 18, 2025



In traditional sound event localization and detection (SELD) tasks, the focus is typically on sound event detection (SED) and direction-of-arrival (DOA) estimation, but they fall short of providing full spatial information about the sound source. The 3D SELD task addresses this limitation by integrating source distance estimation (SDE), allowing for complete spatial localization. We propose three approaches to tackle this challenge: a novel method with independent training and joint prediction, which firstly treats DOA and distance estimation as separate tasks and then combines them to solve 3D SELD; a dual-branch representation with source Cartesian coordinate used for simultaneous DOA and distance estimation; and a three-branch structure that jointly models SED, DOA, and SDE within a unified framework. Our proposed method ranked first in the DCASE 2024 Challenge Task 3, demonstrating the effectiveness of joint modeling for addressing the 3D SELD task. The relevant code for this paper will be open-sourced in the future.
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Jun 21, 2024This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Hierarchical Audio-Visual Information Fusion with Multi-label Joint Decoding for MER 2023
Sep 11, 2023



In this paper, we propose a novel framework for recognizing both discrete and dimensional emotions. In our framework, deep features extracted from foundation models are used as robust acoustic and visual representations of raw video. Three different structures based on attention-guided feature gathering (AFG) are designed for deep feature fusion. Then, we introduce a joint decoding structure for emotion classification and valence regression in the decoding stage. A multi-task loss based on uncertainty is also designed to optimize the whole process. Finally, by combining three different structures on the posterior probability level, we obtain the final predictions of discrete and dimensional emotions. When tested on the dataset of multimodal emotion recognition challenge (MER 2023), the proposed framework yields consistent improvements in both emotion classification and valence regression. Our final system achieves state-of-the-art performance and ranks third on the leaderboard on MER-MULTI sub-challenge.
* 5 pages, 4 figures
A Survey on Automated Design of Metaheuristic Algorithms
Mar 12, 2023



Metaheuristic algorithms have attracted wide attention from academia and industry due to their capability of conducting search independent of problem structures and problem domains. Often, human experts are requested to manually tailor algorithms to fit for solving a targeted problem. The manual tailoring process may be laborious, error-prone, and require intensive specialized knowledge. This gives rise to increasing interests and demands for automated design of metaheuristic algorithms with less human intervention. The automated design could make high-performance algorithms accessible to a much broader range of researchers and practitioners; and by leveraging computing power to fully explore the potential design choices, automated design could reach or even surpass human-level design. This paper presents a broad picture of the formalization, methodologies, challenges, and research trends of automated design of metaheuristic algorithms, by conducting a survey on the common grounds and representative techniques in this field. In the survey, we first present the concept of automated design of metaheuristic algorithms and provide a taxonomy by abstracting the automated design process into four parts, i.e., design space, design strategies, performance evaluation strategies, and targeted problems. Then, we overview the techniques concerning the four parts of the taxonomy and discuss their strengths, weaknesses, challenges, and usability, respectively. Finally, we present research trends in this field.
English-to-Chinese Transliteration with Phonetic Back-transliteration
Jan 21, 2022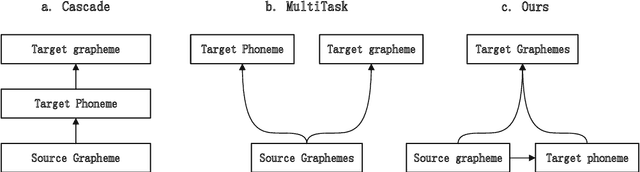
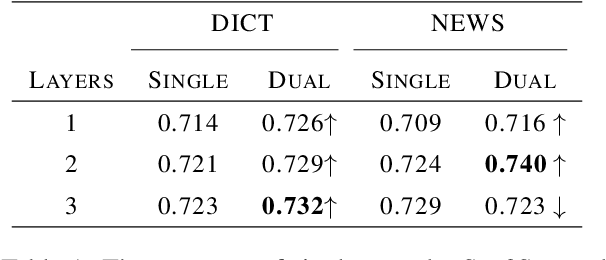
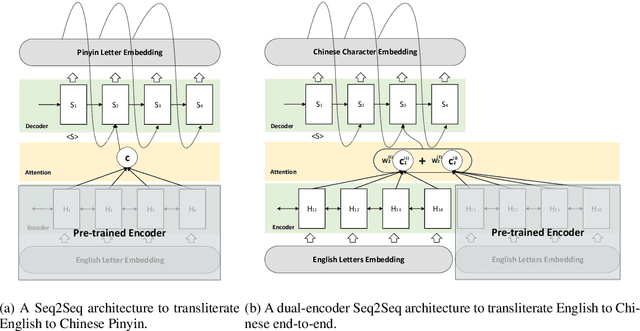
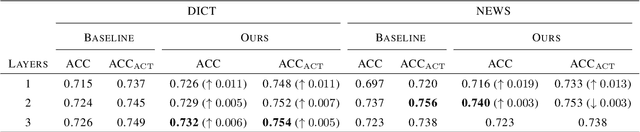
Transliteration is a task of translating named entities from a language to another, based on phonetic similarity. The task has embraced deep learning approaches in recent years, yet, most ignore the phonetic features of the involved languages. In this work, we incorporate phonetic information into neural networks in two ways: we synthesize extra data using forward and back-translation but in a phonetic manner; and we pre-train models on a phonetic task before learning transliteration. Our experiments include three language pairs and six directions, namely English to and from Chinese, Hebrew and Thai. Results indicate that our proposed approach brings benefits to the model and achieves better or similar performance when compared to state of the art.
Simplex Search Based Brain Storm Optimization
Jun 06, 2018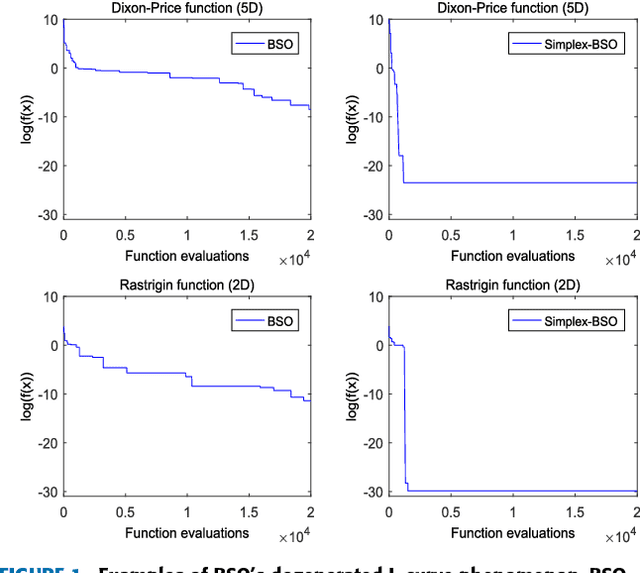
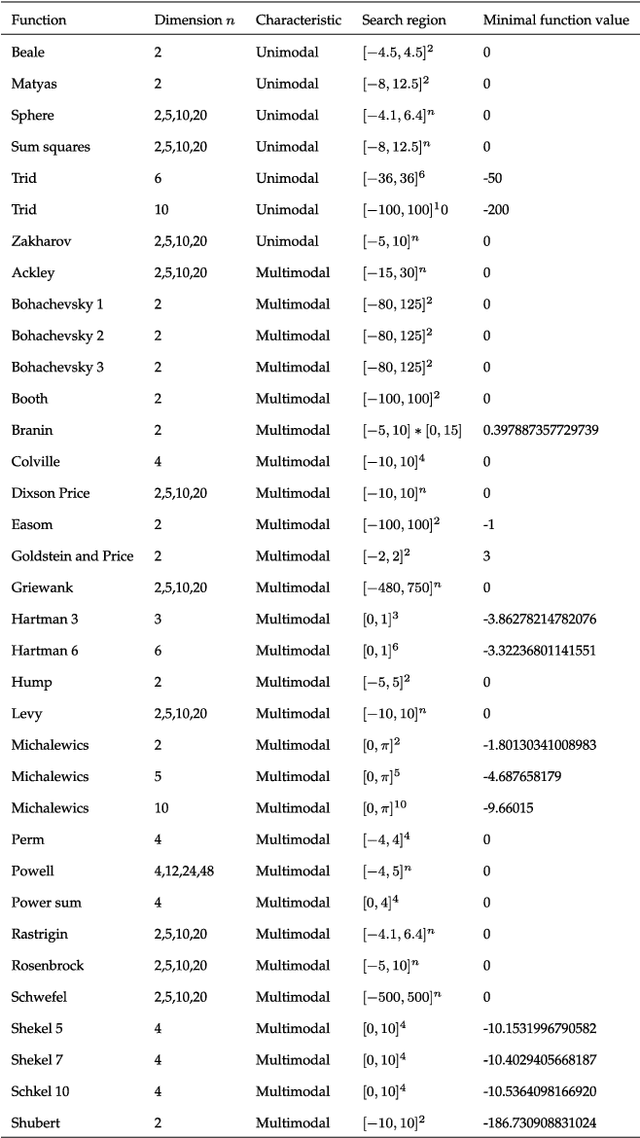
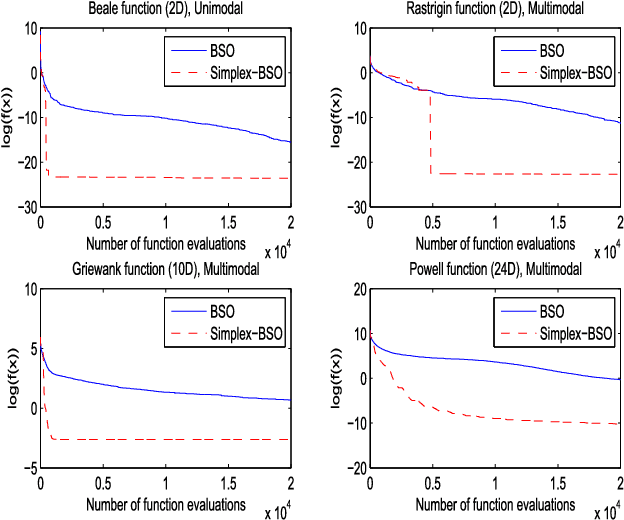
Through modeling human's brainstorming process, the brain storm optimization (BSO) algorithm has become a promising population-based evolutionary algorithm. However, BSO is pointed out that it possesses a degenerated L-curve phenomenon, i.e., it often gets near optimum quickly but needs much more cost to improve the accuracy. To overcome this question in this paper, an excellent direct search based local solver, the Nelder-Mead Simplex (NMS) method is adopted in BSO. Through combining BSO's exploration ability and NMS's exploitation ability together, a simplex search based BSO (Simplex-BSO) is developed via a better balance between global exploration and local exploitation. Simplex-BSO is shown to be able to eliminate the degenerated L-curve phenomenon on unimodal functions, and alleviate significantly this phenomenon on multimodal functions. Large number of experimental results show that Simplex-BSO is a promising algorithm for global optimization problems.
Student's t Distribution based Estimation of Distribution Algorithms for Derivative-free Global Optimization
Nov 25, 2016
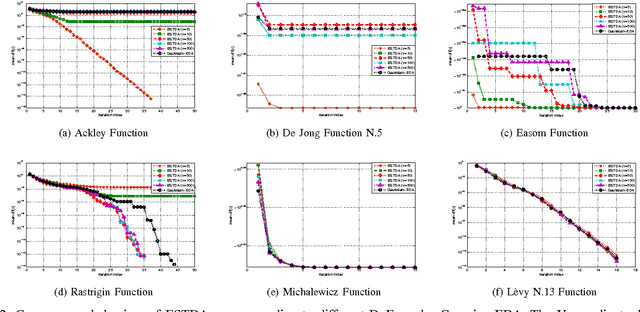


In this paper, we are concerned with a branch of evolutionary algorithms termed estimation of distribution (EDA), which has been successfully used to tackle derivative-free global optimization problems. For existent EDA algorithms, it is a common practice to use a Gaussian distribution or a mixture of Gaussian components to represent the statistical property of available promising solutions found so far. Observing that the Student's t distribution has heavier and longer tails than the Gaussian, which may be beneficial for exploring the solution space, we propose a novel EDA algorithm termed ESTDA, in which the Student's t distribution, rather than Gaussian, is employed. To address hard multimodal and deceptive problems, we extend ESTDA further by substituting a single Student's t distribution with a mixture of Student's t distributions. The resulting algorithm is named as estimation of mixture of Student's t distribution algorithm (EMSTDA). Both ESTDA and EMSTDA are evaluated through extensive and in-depth numerical experiments using over a dozen of benchmark objective functions. Empirical results demonstrate that the proposed algorithms provide remarkably better performance than their Gaussian counterparts.