 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Memory Orchestration for Personalized Persistent Agents
Apr 02, 2026While long-term memory is essential for intelligent agents to maintain consistent historical awareness, the accumulation of extensive interaction data often leads to performance bottlenecks. Naive storage expansion increases retrieval noise and computational latency, overwhelming the reasoning capacity of models deployed on constrained personal devices. To address this, we propose Hierarchical Memory Orchestration (HMO), a framework that organizes interaction history into a three-tiered directory driven by user-centric contextual relevance. Our system maintains a compact primary cache, coupling recent and pivotal memories with an evolving user profile to ensure agent reasoning remains aligned with individual behavioral traits. This primary cache is complemented by a high-priority secondary layer, both of which are managed within a global archive of the full interaction history. Crucially, the user persona dictates memory redistribution across this hierarchy, promoting records mapped to long-term patterns toward more active tiers while relegating less relevant information. This targeted orchestration surfaces historical knowledge precisely when needed while maintaining a lean and efficient active search space. Evaluations on multiple benchmarks achieve state-of-the-art performance. Real-world deployments in ecosystems like OpenClaw demonstrate that HMO significantly enhances agent fluidity and personalization.
Can we generate portable representations for clinical time series data using LLMs?
Mar 25, 2026Deploying clinical ML is slow and brittle: models that work at one hospital often degrade under distribution shifts at the next. In this work, we study a simple question -- can large language models (LLMs) create portable patient embeddings i.e. representations of patients enable a downstream predictor built on one hospital to be used elsewhere with minimal-to-no retraining and fine-tuning. To do so, we map from irregular ICU time series onto concise natural language summaries using a frozen LLM, then embed each summary with a frozen text embedding model to obtain a fixed length vector capable of serving as input to a variety of downstream predictors. Across three cohorts (MIMIC-IV, HIRID, PPICU), on multiple clinically grounded forecasting and classification tasks, we find that our approach is simple, easy to use and competitive with in-distribution with grid imputation, self-supervised representation learning, and time series foundation models, while exhibiting smaller relative performance drops when transferring to new hospitals. We study the variation in performance across prompt design, with structured prompts being crucial to reducing the variance of the predictive models without altering mean accuracy. We find that using these portable representations improves few-shot learning and does not increase demographic recoverability of age or sex relative to baselines, suggesting little additional privacy risk. Our work points to the potential that LLMs hold as tools to enable the scalable deployment of production grade predictive models by reducing the engineering overhead.
An Experimental Study on Fine-Grained Bistatic Sensing of UAV Trajectory via Cellular Downlink Signals
Feb 09, 2026In this letter, a dual-bistatic unmanned aerial vehicles (UAVs) tracking system utilizing downlink Long-Term Evolution (LTE) signals is proposed and demonstrated. Particularly, two LTE base stations (BSs) are exploited as illumination sources. Two passive sensing receivers are deployed at different locations to detect the bistatic Doppler frequencies of the target UAV at different directions according to downlink signals transmitted from their corresponding BSs, such that the velocities of the UAV versus time can be estimated. Hence, the trajectories of the target UAV can be reconstructed. Although both the target UAV and the sensing receivers are around 200 meters away from the illuminating BSs, it is demonstrated by experiments that the tracking errors are below 50 centimeters for 90% of the complicated trajectories, when the distances between the UAV and sensing receivers are less than 30 meters. Note this accuracy is significantly better than the ranging resolution of LTE signals, high-accuracy trajectory tracking for UAV might be feasible via multi-angle bistatic Doppler measurements if the receivers are deployed with a sufficient density.
A self-evolving multi-role collaborative framework with fine-grained difficulty guidance for innovative mathematical problem generation
Jan 16, 2026Mathematical problem generation (MPG) is a significant research direction in the field of intelligent education. In recent years, the rapid development of large language models (LLMs) has enabled new technological approaches to problem-generation tasks. Although existing LLMs can achieve high correctness rates, they generally lack innovation and exhibit poor discrimination. In this paper, we propose the task of innovative math problem generation (IMPG). To solve the IMPG task, this paper proposes a self-evolving, multi-role collaborative framework with fine-grained difficulty guidance. First, a multi-role collaborative mechanism comprising a sampler, generator, evaluator, state machine, and memory is constructed, ensuring the correctness of generated problems through iterative optimization informed by self-assessment and external feedback. Second, we introduce an improved difficulty model to quantify difficulty and provide fine-grained guidance. We adopt the data-driven association-guided path sampling (DAPS) algorithm to enhance the semantic rationality of sampled encodings. Third, we construct the HSM3K-CN dataset, which comprises high-quality high school math problems. A multi-stage training pipeline is adopted, incorporating continual pre-training (CPT), supervised fine-tuning (SFT), and group relative policy optimization (GRPO), to enhance the generation and evaluation capabilities of the base model. Finally, system self-evolution is achieved by transferring evaluation capabilities from the expert model to the apprentice model via distillation. Experiments show that, compared to baseline models, our proposed method significantly improves the innovation of the generated problems while maintaining a high correctness rate.
WDT-MD: Wavelet Diffusion Transformers for Microaneurysm Detection in Fundus Images
Nov 16, 2025Microaneurysms (MAs), the earliest pathognomonic signs of Diabetic Retinopathy (DR), present as sub-60 $μm$ lesions in fundus images with highly variable photometric and morphological characteristics, rendering manual screening not only labor-intensive but inherently error-prone. While diffusion-based anomaly detection has emerged as a promising approach for automated MA screening, its clinical application is hindered by three fundamental limitations. First, these models often fall prey to "identity mapping", where they inadvertently replicate the input image. Second, they struggle to distinguish MAs from other anomalies, leading to high false positives. Third, their suboptimal reconstruction of normal features hampers overall performance. To address these challenges, we propose a Wavelet Diffusion Transformer framework for MA Detection (WDT-MD), which features three key innovations: a noise-encoded image conditioning mechanism to avoid "identity mapping" by perturbing image conditions during training; pseudo-normal pattern synthesis via inpainting to introduce pixel-level supervision, enabling discrimination between MAs and other anomalies; and a wavelet diffusion Transformer architecture that combines the global modeling capability of diffusion Transformers with multi-scale wavelet analysis to enhance reconstruction of normal retinal features. Comprehensive experiments on the IDRiD and e-ophtha MA datasets demonstrate that WDT-MD outperforms state-of-the-art methods in both pixel-level and image-level MA detection. This advancement holds significant promise for improving early DR screening.
Towards Universal Solvers: Using PGD Attack in Active Learning to Increase Generalizability of Neural Operators as Knowledge Distillation from Numerical PDE Solvers
Oct 21, 2025Nonlinear PDE solvers require fine space-time discretizations and local linearizations, leading to high memory cost and slow runtimes. Neural operators such as FNOs and DeepONets offer fast single-shot inference by learning function-to-function mappings and truncating high-frequency components, but they suffer from poor out-of-distribution (OOD) generalization, often failing on inputs outside the training distribution. We propose an adversarial teacher-student distillation framework in which a differentiable numerical solver supervises a compact neural operator while a PGD-style active sampling loop searches for worst-case inputs under smoothness and energy constraints to expand the training set. Using differentiable spectral solvers enables gradient-based adversarial search and stabilizes sample mining. Experiments on Burgers and Navier-Stokes systems demonstrate that adversarial distillation substantially improves OOD robustness while preserving the low parameter cost and fast inference of neural operators.
Brain-HGCN: A Hyperbolic Graph Convolutional Network for Brain Functional Network Analysis
Sep 18, 2025Functional magnetic resonance imaging (fMRI) provides a powerful non-invasive window into the brain's functional organization by generating complex functional networks, typically modeled as graphs. These brain networks exhibit a hierarchical topology that is crucial for cognitive processing. However, due to inherent spatial constraints, standard Euclidean GNNs struggle to represent these hierarchical structures without high distortion, limiting their clinical performance. To address this limitation, we propose Brain-HGCN, a geometric deep learning framework based on hyperbolic geometry, which leverages the intrinsic property of negatively curved space to model the brain's network hierarchy with high fidelity. Grounded in the Lorentz model, our model employs a novel hyperbolic graph attention layer with a signed aggregation mechanism to distinctly process excitatory and inhibitory connections, ultimately learning robust graph-level representations via a geometrically sound Fr\'echet mean for graph readout. Experiments on two large-scale fMRI datasets for psychiatric disorder classification demonstrate that our approach significantly outperforms a wide range of state-of-the-art Euclidean baselines. This work pioneers a new geometric deep learning paradigm for fMRI analysis, highlighting the immense potential of hyperbolic GNNs in the field of computational psychiatry.
Age Sensitive Hippocampal Functional Connectivity: New Insights from 3D CNNs and Saliency Mapping
Jul 02, 2025Grey matter loss in the hippocampus is a hallmark of neurobiological aging, yet understanding the corresponding changes in its functional connectivity remains limited. Seed-based functional connectivity (FC) analysis enables voxel-wise mapping of the hippocampus's synchronous activity with cortical regions, offering a window into functional reorganization during aging. In this study, we develop an interpretable deep learning framework to predict brain age from hippocampal FC using a three-dimensional convolutional neural network (3D CNN) combined with LayerCAM saliency mapping. This approach maps key hippocampal-cortical connections, particularly with the precuneus, cuneus, posterior cingulate cortex, parahippocampal cortex, left superior parietal lobule, and right superior temporal sulcus, that are highly sensitive to age. Critically, disaggregating anterior and posterior hippocampal FC reveals distinct mapping aligned with their known functional specializations. These findings provide new insights into the functional mechanisms of hippocampal aging and demonstrate the power of explainable deep learning to uncover biologically meaningful patterns in neuroimaging data.
Voxel-Level Brain States Prediction Using Swin Transformer
Jun 13, 2025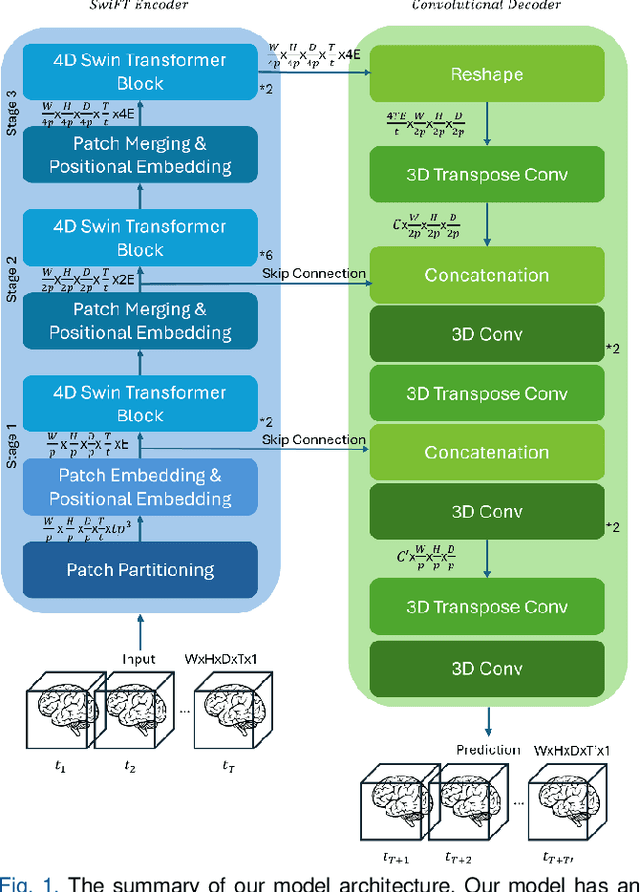
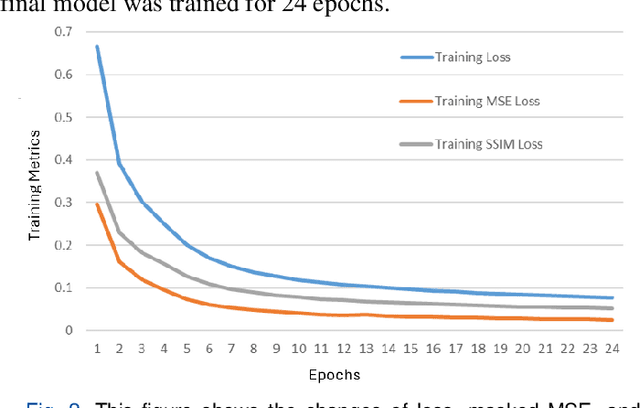
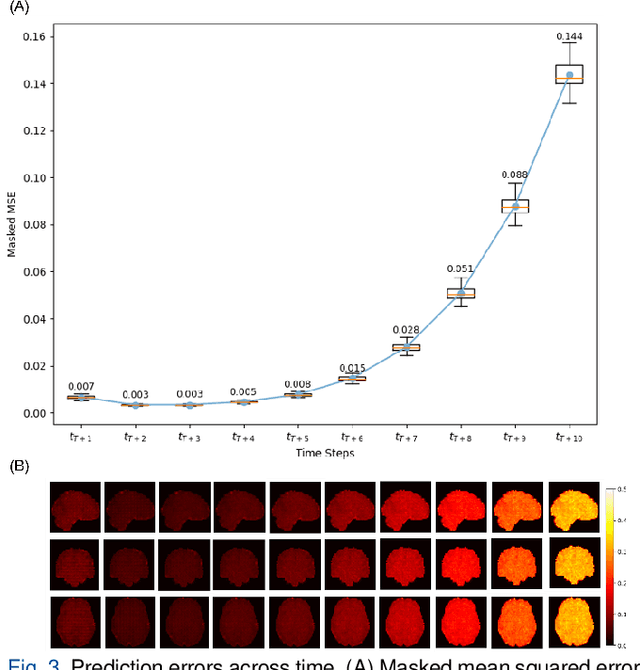
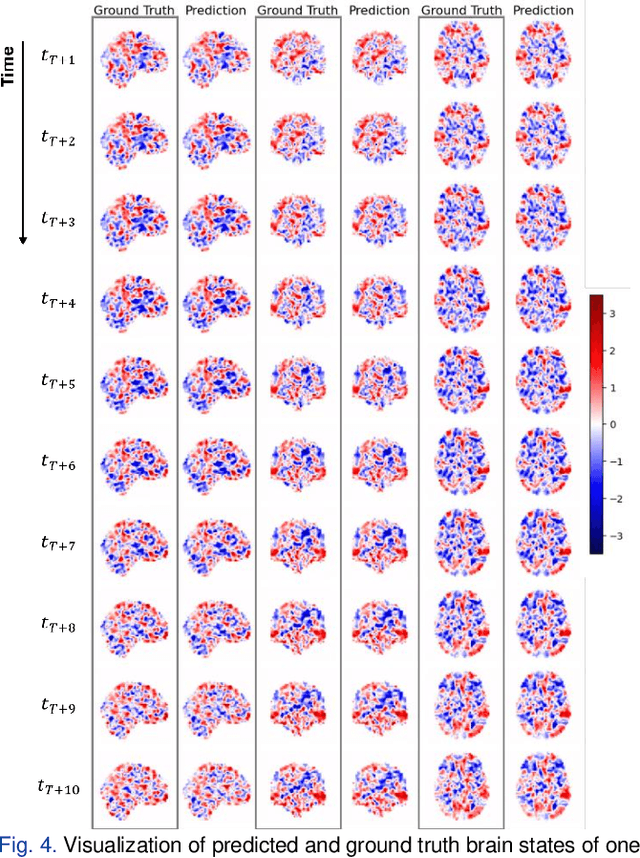
Understanding brain dynamics is important for neuroscience and mental health. Functional magnetic resonance imaging (fMRI) enables the measurement of neural activities through blood-oxygen-level-dependent (BOLD) signals, which represent brain states. In this study, we aim to predict future human resting brain states with fMRI. Due to the 3D voxel-wise spatial organization and temporal dependencies of the fMRI data, we propose a novel architecture which employs a 4D Shifted Window (Swin) Transformer as encoder to efficiently learn spatio-temporal information and a convolutional decoder to enable brain state prediction at the same spatial and temporal resolution as the input fMRI data. We used 100 unrelated subjects from the Human Connectome Project (HCP) for model training and testing. Our novel model has shown high accuracy when predicting 7.2s resting-state brain activities based on the prior 23.04s fMRI time series. The predicted brain states highly resemble BOLD contrast and dynamics. This work shows promising evidence that the spatiotemporal organization of the human brain can be learned by a Swin Transformer model, at high resolution, which provides a potential for reducing the fMRI scan time and the development of brain-computer interfaces in the future.
Mosaic: Data-Free Knowledge Distillation via Mixture-of-Experts for Heterogeneous Distributed Environments
May 26, 2025



Federated Learning (FL) is a decentralized machine learning paradigm that enables clients to collaboratively train models while preserving data privacy. However, the coexistence of model and data heterogeneity gives rise to inconsistent representations and divergent optimization dynamics across clients, ultimately hindering robust global performance. To transcend these challenges, we propose Mosaic, a novel data-free knowledge distillation framework tailored for heterogeneous distributed environments. Mosaic first trains local generative models to approximate each client's personalized distribution, enabling synthetic data generation that safeguards privacy through strict separation from real data. Subsequently, Mosaic forms a Mixture-of-Experts (MoE) from client models based on their specialized knowledge, and distills it into a global model using the generated data. To further enhance the MoE architecture, Mosaic integrates expert predictions via a lightweight meta model trained on a few representative prototypes. Extensive experiments on standard image classification benchmarks demonstrate that Mosaic consistently outperforms state-of-the-art approaches under both model and data heterogeneity. The source code has been published at https://github.com/Wings-Of-Disaster/Mosaic.