 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCH3R: Object-Centric Holistic 3D Reconstruction
May 13, 2026Object-centric scene understanding is a fundamental challenge in computer vision. Existing approaches often rely on multi-stage pipelines that first apply pre-trained segmentors to extract individual objects, followed by per-object 3D reconstruction. Such methods are computationally expensive, fragile to segmentation errors, and scale poorly with scene complexity. We introduce OCH3R, a unified framework for Object-Centric Holistic 3D Reconstruction from a single RGB image. OCH3R performs one forward pass to simultaneously predict all object instances with their 6D poses and detailed 3D reconstructions. The key idea is a transformer architecture that predicts per-pixel attributes, including CLIP-based category embeddings, metric depth, normalized object coordinates (NOCS), and a fixed number of 3D Gaussians representing each object. To supervise these Gaussian reconstructions, we transform them into canonical space using the predicted 6D poses and align them with pre-rendered canonical ground truth, avoiding costly per-image Gaussian label generation. On standard indoor benchmarks, OCH3R achieves state-of-the-art performance across monocular depth estimation, open-vocabulary semantic segmentation, and RGB-only category-level 6D pose estimation, while producing high-fidelity, editable per-object reconstructions. Crucially, inference is fully feed-forward and scales independently of the number of objects, offering orders-of-magnitude speedups over conventional multi-stage pipelines in cluttered scenes.
USCNet: Transformer-Based Multimodal Fusion with Segmentation Guidance for Urolithiasis Classification
Apr 08, 2026Kidney stone disease ranks among the most prevalent conditions in urology, and understanding the composition of these stones is essential for creating personalized treatment plans and preventing recurrence. Current methods for analyzing kidney stones depend on postoperative specimens, which prevents rapid classification before surgery. To overcome this limitation, we introduce a new approach called the Urinary Stone Segmentation and Classification Network (USCNet). This innovative method allows for precise preoperative classification of kidney stones by integrating Computed Tomography (CT) images with clinical data from Electronic Health Records (EHR). USCNet employs a Transformer-based multimodal fusion framework with CT-EHR attention and segmentation-guided attention modules for accurate classification. Moreover, a dynamic loss function is introduced to effectively balance the dual objectives of segmentation and classification. Experiments on an in-house kidney stone dataset show that USCNet demonstrates outstanding performance across all evaluation metrics, with its classification efficacy significantly surpassing existing mainstream methods. This study presents a promising solution for the precise preoperative classification of kidney stones, offering substantial clinical benefits. The source code has been made publicly available: https://github.com/ZhangSongqi0506/KidneyStone.
Balancing Efficiency and Restoration: Lightweight Mamba-Based Model for CT Metal Artifact Reduction
Apr 08, 2026In computed tomography imaging, metal implants frequently generate severe artifacts that compromise image quality and hinder diagnostic accuracy. There are three main challenges in the existing methods: the deterioration of organ and tissue structures, dependence on sinogram data, and an imbalance between resource use and restoration efficiency. Addressing these issues, we introduce MARMamba, which effectively eliminates artifacts caused by metals of different sizes while maintaining the integrity of the original anatomical structures of the image. Furthermore, this model only focuses on CT images affected by metal artifacts, thus negating the requirement for additional input data. The model is a streamlined UNet architecture, which incorporates multi-scale Mamba (MS-Mamba) as its core module. Within MS-Mamba, a flip mamba block captures comprehensive contextual information by analyzing images from multiple orientations. Subsequently, the average maximum feed-forward network integrates critical features with average features to suppress the artifacts. This combination allows MARMamba to reduce artifacts efficiently. The experimental results demonstrate that our model excels in reducing metal artifacts, offering distinct advantages over other models. It also strikes an optimal balance between computational demands, memory usage, and the number of parameters, highlighting its practical utility in the real world. The code of the presented model is available at: https://github.com/RICKand-MORTY/MARMamba.
Eliminating Inductive Bias in Reward Models with Information-Theoretic Guidance
Dec 29, 2025Reward models (RMs) are essential in reinforcement learning from human feedback (RLHF) to align large language models (LLMs) with human values. However, RM training data is commonly recognized as low-quality, containing inductive biases that can easily lead to overfitting and reward hacking. For example, more detailed and comprehensive responses are usually human-preferred but with more words, leading response length to become one of the inevitable inductive biases. A limited number of prior RM debiasing approaches either target a single specific type of bias or model the problem with only simple linear correlations, \textit{e.g.}, Pearson coefficients. To mitigate more complex and diverse inductive biases in reward modeling, we introduce a novel information-theoretic debiasing method called \textbf{D}ebiasing via \textbf{I}nformation optimization for \textbf{R}M (DIR). Inspired by the information bottleneck (IB), we maximize the mutual information (MI) between RM scores and human preference pairs, while minimizing the MI between RM outputs and biased attributes of preference inputs. With theoretical justification from information theory, DIR can handle more sophisticated types of biases with non-linear correlations, broadly extending the real-world application scenarios for RM debiasing methods. In experiments, we verify the effectiveness of DIR with three types of inductive biases: \textit{response length}, \textit{sycophancy}, and \textit{format}. We discover that DIR not only effectively mitigates target inductive biases but also enhances RLHF performance across diverse benchmarks, yielding better generalization abilities. The code and training recipes are available at https://github.com/Qwen-Applications/DIR.
DGSAN: Dual-Graph Spatiotemporal Attention Network for Pulmonary Nodule Malignancy Prediction
Dec 24, 2025Lung cancer continues to be the leading cause of cancer-related deaths globally. Early detection and diagnosis of pulmonary nodules are essential for improving patient survival rates. Although previous research has integrated multimodal and multi-temporal information, outperforming single modality and single time point, the fusion methods are limited to inefficient vector concatenation and simple mutual attention, highlighting the need for more effective multimodal information fusion. To address these challenges, we introduce a Dual-Graph Spatiotemporal Attention Network, which leverages temporal variations and multimodal data to enhance the accuracy of predictions. Our methodology involves developing a Global-Local Feature Encoder to better capture the local, global, and fused characteristics of pulmonary nodules. Additionally, a Dual-Graph Construction method organizes multimodal features into inter-modal and intra-modal graphs. Furthermore, a Hierarchical Cross-Modal Graph Fusion Module is introduced to refine feature integration. We also compiled a novel multimodal dataset named the NLST-cmst dataset as a comprehensive source of support for related research. Our extensive experiments, conducted on both the NLST-cmst and curated CSTL-derived datasets, demonstrate that our DGSAN significantly outperforms state-of-the-art methods in classifying pulmonary nodules with exceptional computational efficiency.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
VLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
Nov 09, 2025Recent advancements in language-grounded autonomous driving have been significantly promoted by the sophisticated cognition and reasoning capabilities of large language models (LLMs). However, current LLM-based approaches encounter critical challenges: (1) Failure analysis reveals that frequent collisions and obstructions, stemming from limitations in visual representations, remain primary obstacles to robust driving performance. (2) The substantial parameters of LLMs pose considerable deployment hurdles. To address these limitations, we introduce VLDrive, a novel approach featuring a lightweight MLLM architecture with enhanced vision components. VLDrive achieves compact visual tokens through innovative strategies, including cycle-consistent dynamic visual pruning and memory-enhanced feature aggregation. Furthermore, we propose a distance-decoupled instruction attention mechanism to improve joint visual-linguistic feature learning, particularly for long-range visual tokens. Extensive experiments conducted in the CARLA simulator demonstrate VLDrive`s effectiveness. Notably, VLDrive achieves state-of-the-art driving performance while reducing parameters by 81% (from 7B to 1.3B), yielding substantial driving score improvements of 15.4%, 16.8%, and 7.6% at tiny, short, and long distances, respectively, in closed-loop evaluations. Code is available at https://github.com/ReaFly/VLDrive.
AdaDrive: Self-Adaptive Slow-Fast System for Language-Grounded Autonomous Driving
Nov 09, 2025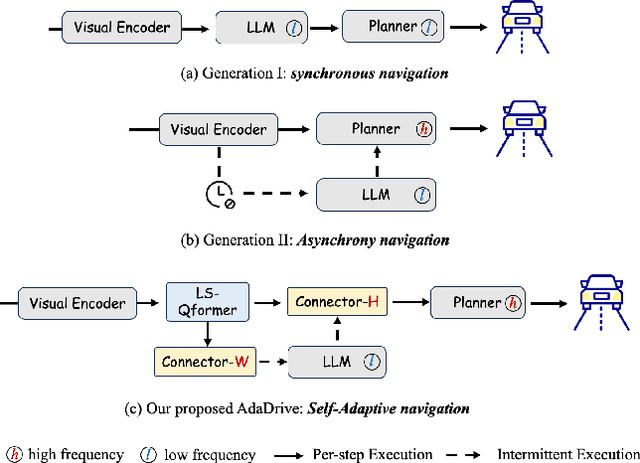
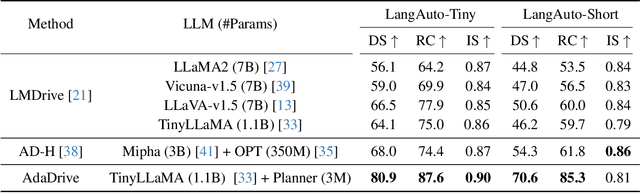
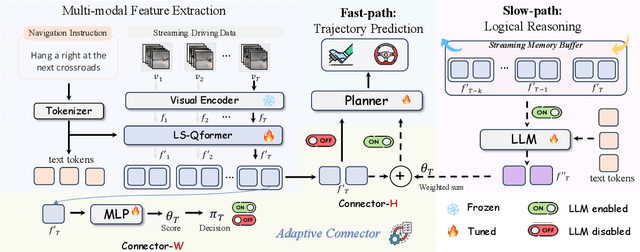
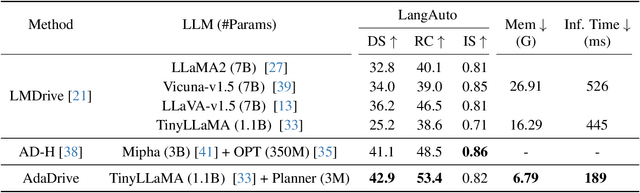
Effectively integrating Large Language Models (LLMs) into autonomous driving requires a balance between leveraging high-level reasoning and maintaining real-time efficiency. Existing approaches either activate LLMs too frequently, causing excessive computational overhead, or use fixed schedules, failing to adapt to dynamic driving conditions. To address these challenges, we propose AdaDrive, an adaptively collaborative slow-fast framework that optimally determines when and how LLMs contribute to decision-making. (1) When to activate the LLM: AdaDrive employs a novel adaptive activation loss that dynamically determines LLM invocation based on a comparative learning mechanism, ensuring activation only in complex or critical scenarios. (2) How to integrate LLM assistance: Instead of rigid binary activation, AdaDrive introduces an adaptive fusion strategy that modulates a continuous, scaled LLM influence based on scene complexity and prediction confidence, ensuring seamless collaboration with conventional planners. Through these strategies, AdaDrive provides a flexible, context-aware framework that maximizes decision accuracy without compromising real-time performance. Extensive experiments on language-grounded autonomous driving benchmarks demonstrate that AdaDrive state-of-the-art performance in terms of both driving accuracy and computational efficiency. Code is available at https://github.com/ReaFly/AdaDrive.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025
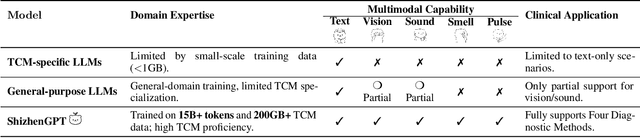
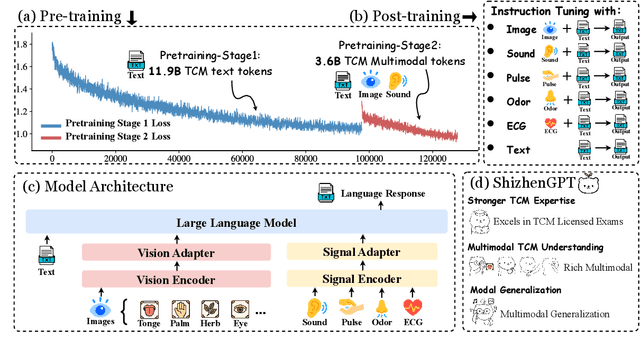
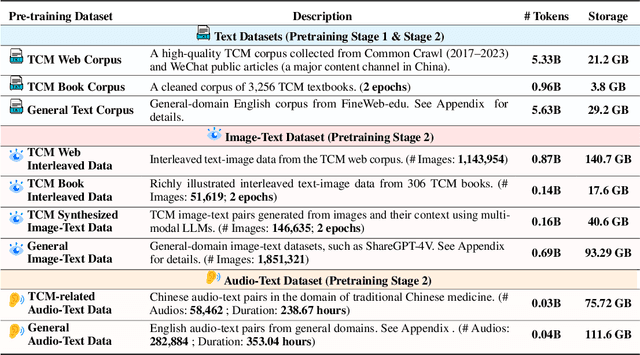
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
An Investigation of Robustness of LLMs in Mathematical Reasoning: Benchmarking with Mathematically-Equivalent Transformation of Advanced Mathematical Problems
Aug 12, 2025In this paper, we introduce a systematic framework beyond conventional method to assess LLMs' mathematical-reasoning robustness by stress-testing them on advanced math problems that are mathematically equivalent but with linguistic and parametric variation. These transformations allow us to measure the sensitivity of LLMs to non-mathematical perturbations, thereby enabling a more accurate evaluation of their mathematical reasoning capabilities. Using this new evaluation methodology, we created PutnamGAP, a new benchmark dataset with multiple mathematically-equivalent variations of competition-level math problems. With the new dataset, we evaluate multiple families of representative LLMs and examine their robustness. Across 18 commercial and open-source models we observe sharp performance degradation on the variants. OpenAI's flagship reasoning model, O3, scores 49 % on the originals but drops by 4 percentage points on surface variants, and by 10.5 percentage points on core-step-based variants, while smaller models fare far worse. Overall, the results show that the proposed new evaluation methodology is effective for deepening our understanding of the robustness of LLMs and generating new insights for further improving their mathematical reasoning capabilities.