 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Information Extraction using Large Language Models
Sep 04, 2024
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Learning Word Embedding with Better Distance Weighting and Window Size Scheduling
Apr 23, 2024
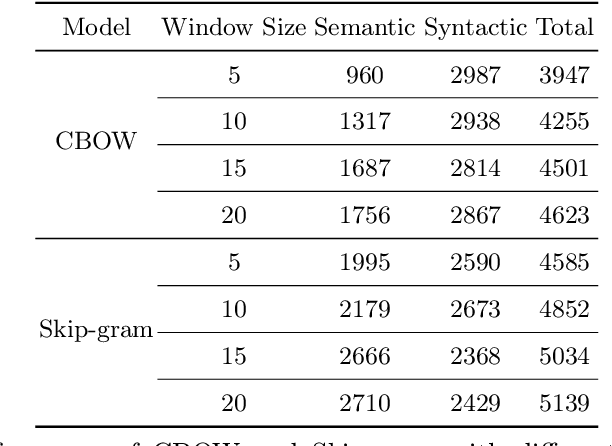


Distributed word representation (a.k.a. word embedding) is a key focus in natural language processing (NLP). As a highly successful word embedding model, Word2Vec offers an efficient method for learning distributed word representations on large datasets. However, Word2Vec lacks consideration for distances between center and context words. We propose two novel methods, Learnable Formulated Weights (LFW) and Epoch-based Dynamic Window Size (EDWS), to incorporate distance information into two variants of Word2Vec, the Continuous Bag-of-Words (CBOW) model and the Continuous Skip-gram (Skip-gram) model. For CBOW, LFW uses a formula with learnable parameters that best reflects the relationship of influence and distance between words to calculate distance-related weights for average pooling, providing insights for future NLP text modeling research. For Skip-gram, we improve its dynamic window size strategy to introduce distance information in a more balanced way. Experiments prove the effectiveness of LFW and EDWS in enhancing Word2Vec's performance, surpassing previous state-of-the-art methods.
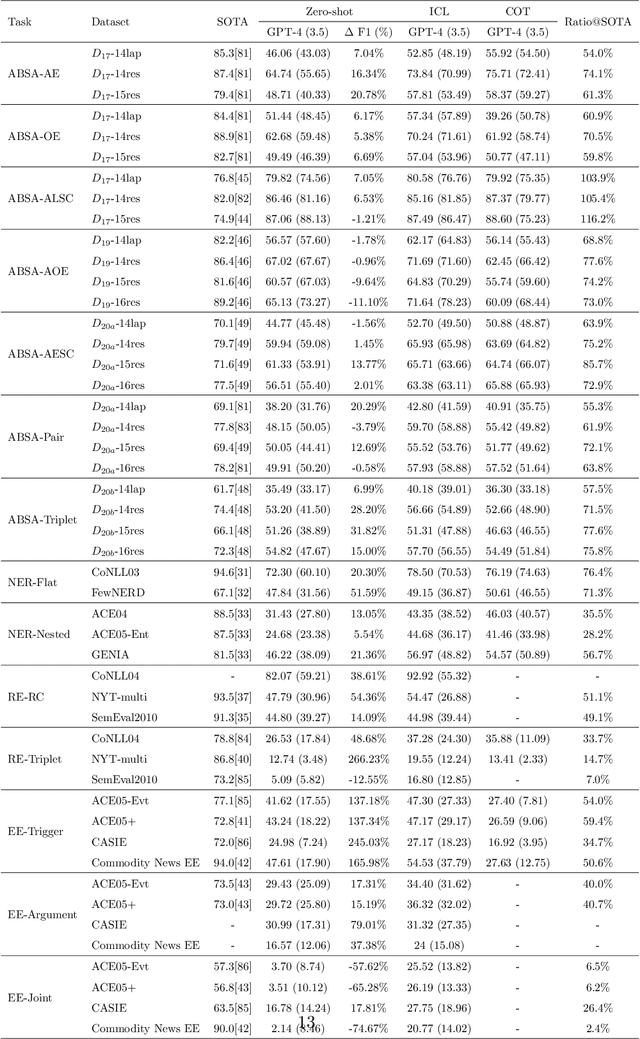
Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
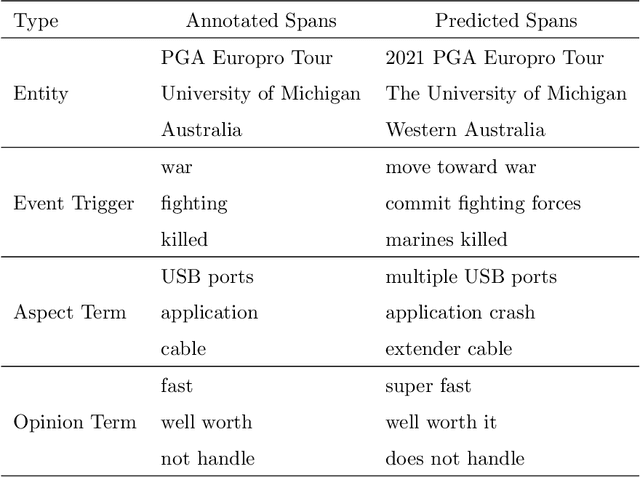
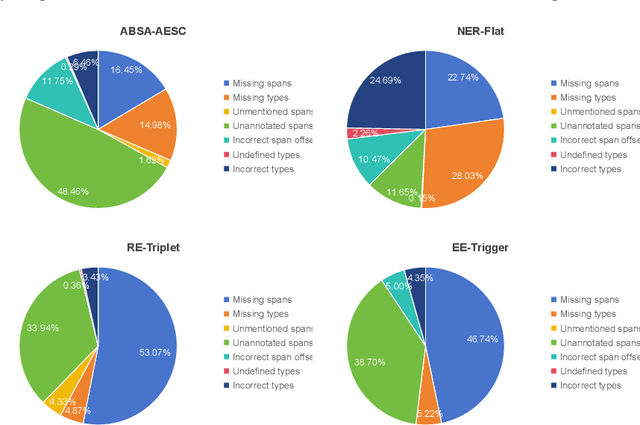
May 23, 2023ChatGPT has stimulated the research boom in the field of large language models. In this paper, we assess the capabilities of ChatGPT from four perspectives including Performance, Evaluation Criteria, Robustness and Error Types. Specifically, we first evaluate ChatGPT's performance on 17 datasets with 14 IE sub-tasks under the zero-shot, few-shot and chain-of-thought scenarios, and find a huge performance gap between ChatGPT and SOTA results. Next, we rethink this gap and propose a soft-matching strategy for evaluation to more accurately reflect ChatGPT's performance. Then, we analyze the robustness of ChatGPT on 14 IE sub-tasks, and find that: 1) ChatGPT rarely outputs invalid responses; 2) Irrelevant context and long-tail target types greatly affect ChatGPT's performance; 3) ChatGPT cannot understand well the subject-object relationships in RE task. Finally, we analyze the errors of ChatGPT, and find that "unannotated spans" is the most dominant error type. This raises concerns about the quality of annotated data, and indicates the possibility of annotating data with ChatGPT. The data and code are released at Github site.