 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: Forecastability-Aware Mixture of Experts for Heterogeneous Time Series Forecasting
Jun 08, 2026Large-scale retail and industrial forecasting systems contain many heterogeneous time series whose lifecycle, sparsity, volatility, seasonality, spectral patterns, and contextual sensitivity differ substantially. A single forecasting model rarely performs well across all regimes, while dense ensembles increase inference cost and provide limited insight into expert suitability. This paper studies forecastability-aware expert routing: learning how data characteristics determine the suitability of forecasting experts. We propose \method{}, a sparse mixture-of-experts framework that represents each series with a multidimensional forecastability fingerprint, mines expert-suitability targets from validation performance, and trains a cost-aware sparse router to activate a small budgeted set of experts for each series. Using a production-scale vending-machine sales dataset from Shandong New Beiyang (SNBC), where the forecasting component has been integrated into the replenishment-planning pipeline, together with public retail benchmarks, we show that expert suitability varies systematically across data regimes. On the industrial dataset with 5,000+ machines and 60M+ transactions, \method{} Top-2 reduces MSE by 12.4\% over the strongest single expert, LightGBM, while executing 1.92 experts per series on average. The deployed component produces demand forecasts, while inventory-oriented gains are estimated by an offline replay simulator under a fixed replenishment policy rather than by online intervention. The framework turns heterogeneous sales forecasting from heuristic model selection into data mining of forecastability patterns and expert specialization. Code is available at https://github.com/hit636/FAME
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
CryptoX : Compositional Reasoning Evaluation of Large Language Models
Feb 08, 2025



The compositional reasoning capacity has long been regarded as critical to the generalization and intelligence emergence of large language models LLMs. However, despite numerous reasoning-related benchmarks, the compositional reasoning capacity of LLMs is rarely studied or quantified in the existing benchmarks. In this paper, we introduce CryptoX, an evaluation framework that, for the first time, combines existing benchmarks and cryptographic, to quantify the compositional reasoning capacity of LLMs. Building upon CryptoX, we construct CryptoBench, which integrates these principles into several benchmarks for systematic evaluation. We conduct detailed experiments on widely used open-source and closed-source LLMs using CryptoBench, revealing a huge gap between open-source and closed-source LLMs. We further conduct thorough mechanical interpretability experiments to reveal the inner mechanism of LLMs' compositional reasoning, involving subproblem decomposition, subproblem inference, and summarizing subproblem conclusions. Through analysis based on CryptoBench, we highlight the value of independently studying compositional reasoning and emphasize the need to enhance the compositional reasoning capabilities of LLMs.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
SDM-Car: A Dataset for Small and Dim Moving Vehicles Detection in Satellite Videos
Dec 24, 2024



Vehicle detection and tracking in satellite video is essential in remote sensing (RS) applications. However, upon the statistical analysis of existing datasets, we find that the dim vehicles with low radiation intensity and limited contrast against the background are rarely annotated, which leads to the poor effect of existing approaches in detecting moving vehicles under low radiation conditions. In this paper, we address the challenge by building a \textbf{S}mall and \textbf{D}im \textbf{M}oving Cars (SDM-Car) dataset with a multitude of annotations for dim vehicles in satellite videos, which is collected by the Luojia 3-01 satellite and comprises 99 high-quality videos. Furthermore, we propose a method based on image enhancement and attention mechanisms to improve the detection accuracy of dim vehicles, serving as a benchmark for evaluating the dataset. Finally, we assess the performance of several representative methods on SDM-Car and present insightful findings. The dataset is openly available at https://github.com/TanedaM/SDM-Car.
DefFiller: Mask-Conditioned Diffusion for Salient Steel Surface Defect Generation
Dec 20, 2024



Current saliency-based defect detection methods show promise in industrial settings, but the unpredictability of defects in steel production environments complicates dataset creation, hampering model performance. Existing data augmentation approaches using generative models often require pixel-level annotations, which are time-consuming and resource-intensive. To address this, we introduce DefFiller, a mask-conditioned defect generation method that leverages a layout-to-image diffusion model. DefFiller generates defect samples paired with mask conditions, eliminating the need for pixel-level annotations and enabling direct use in model training. We also develop an evaluation framework to assess the quality of generated samples and their impact on detection performance. Experimental results on the SD-Saliency-900 dataset demonstrate that DefFiller produces high-quality defect images that accurately match the provided mask conditions, significantly enhancing the performance of saliency-based defect detection models trained on the augmented dataset.
An Empirical Study on Information Extraction using Large Language Models
Sep 04, 2024
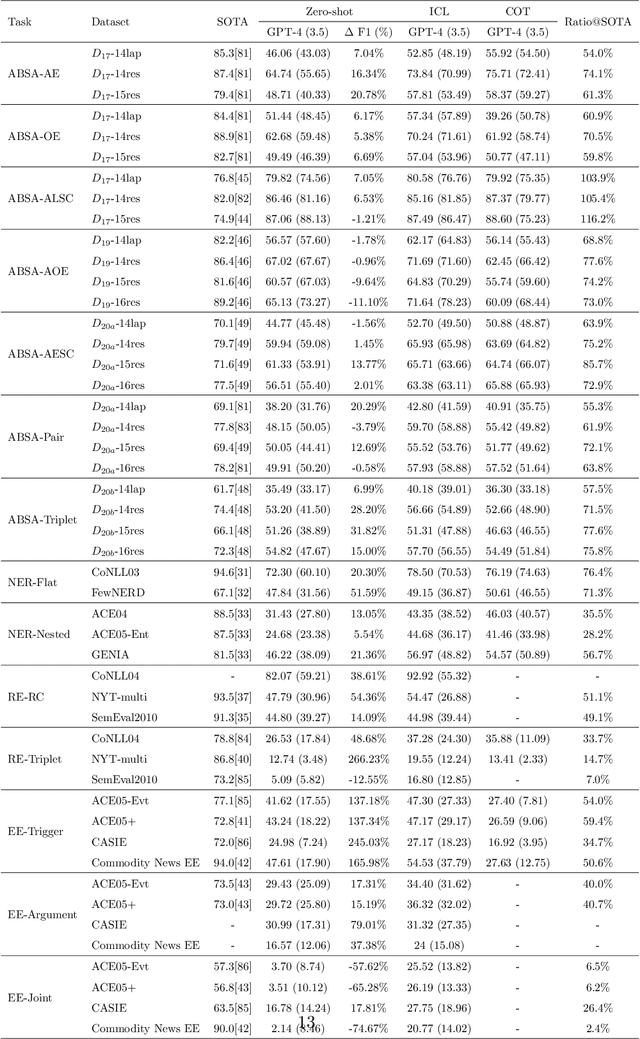
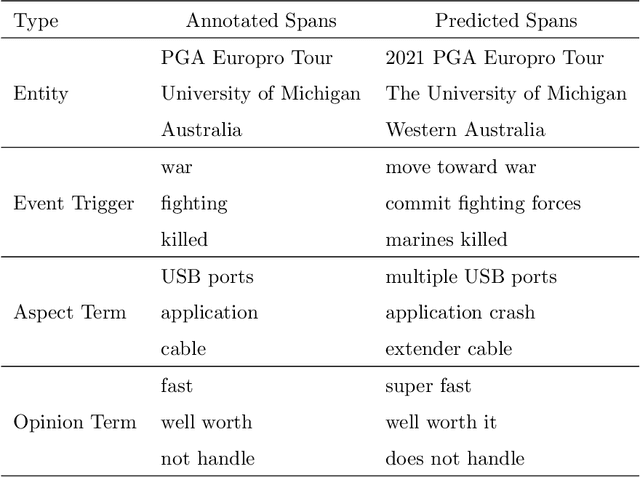
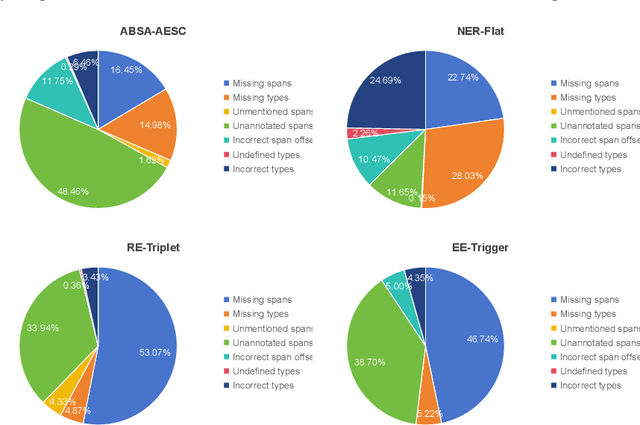
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
AI-based Automatic Segmentation of Prostate on Multi-modality Images: A Review
Jul 09, 2024



Prostate cancer represents a major threat to health. Early detection is vital in reducing the mortality rate among prostate cancer patients. One approach involves using multi-modality (CT, MRI, US, etc.) computer-aided diagnosis (CAD) systems for the prostate region. However, prostate segmentation is challenging due to imperfections in the images and the prostate's complex tissue structure. The advent of precision medicine and a significant increase in clinical capacity have spurred the need for various data-driven tasks in the field of medical imaging. Recently, numerous machine learning and data mining tools have been integrated into various medical areas, including image segmentation. This article proposes a new classification method that differentiates supervision types, either in number or kind, during the training phase. Subsequently, we conducted a survey on artificial intelligence (AI)-based automatic prostate segmentation methods, examining the advantages and limitations of each. Additionally, we introduce variants of evaluation metrics for the verification and performance assessment of the segmentation method and summarize the current challenges. Finally, future research directions and development trends are discussed, reflecting the outcomes of our literature survey, suggesting high-precision detection and treatment of prostate cancer as a promising avenue.
Defect Image Sample Generation With Diffusion Prior for Steel Surface Defect Recognition
May 03, 2024



The task of steel surface defect recognition is an industrial problem with great industry values. The data insufficiency is the major challenge in training a robust defect recognition network. Existing methods have investigated to enlarge the dataset by generating samples with generative models. However, their generation quality is still limited by the insufficiency of defect image samples. To this end, we propose Stable Surface Defect Generation (StableSDG), which transfers the vast generation distribution embedded in Stable Diffusion model for steel surface defect image generation. To tackle with the distinctive distribution gap between steel surface images and generated images of the diffusion model, we propose two processes. First, we align the distribution by adapting parameters of the diffusion model, adopted both in the token embedding space and network parameter space. Besides, in the generation process, we propose image-oriented generation rather than from pure Gaussian noises. We conduct extensive experiments on steel surface defect dataset, demonstrating state-of-the-art performance on generating high-quality samples and training recognition models, and both designed processes are significant for the performance.
RoMe: Towards Large Scale Road Surface Reconstruction via Mesh Representation
Jun 20, 2023



Large-scale road surface reconstruction is becoming important to autonomous driving systems, as it provides valuable training and testing data effectively. In this paper, we introduce a simple yet efficient method, RoMe, for large-scale Road surface reconstruction via Mesh representations. To simplify the problem, RoMe decomposes a 3D road surface into a triangle-mesh and a multilayer perception network to model the road elevation implicitly. To retain fine surface details, each mesh vertex has two extra attributes, namely color and semantics. To improve the efficiency of RoMe in large-scale environments, a novel waypoint sampling method is introduced. As such, RoMe can properly preserve road surface details, with only linear computational complexity to road areas. In addition, to improve the accuracy of RoMe, extrinsics optimization is proposed to mitigate inaccurate extrinsic calibrations. Experimental results on popular public datasets also demonstrate the high efficiency and accuracy of RoMe.