 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image
Apr 06, 2026Compositional 3D scene generation from a single view requires the simultaneous recovery of scene layout and 3D assets. Existing approaches mainly fall into two categories: feed-forward generation methods and per-instance generation methods. The former directly predict 3D assets with explicit 6DoF poses through efficient network inference, but they generalize poorly to complex scenes. The latter improve generalization through a divide-and-conquer strategy, but suffer from time-consuming pose optimization. To bridge this gap, we introduce 3D-Fixer, a novel in-place completion paradigm. Specifically, 3D-Fixer extends 3D object generative priors to generate complete 3D assets conditioned on the partially visible point cloud at the original locations, which are cropped from the fragmented geometry obtained from the geometry estimation methods. Unlike prior works that require explicit pose alignment, 3D-Fixer uses fragmented geometry as a spatial anchor to preserve layout fidelity. At its core, we propose a coarse-to-fine generation scheme to resolve boundary ambiguity under occlusion, supported by a dual-branch conditioning network and an Occlusion-Robust Feature Alignment (ORFA) strategy for stable training. Furthermore, to address the data scarcity bottleneck, we present ARSG-110K, the largest scene-level dataset to date, comprising over 110K diverse scenes and 3M annotated images with high-fidelity 3D ground truth. Extensive experiments show that 3D-Fixer achieves state-of-the-art geometric accuracy, which significantly outperforms baselines such as MIDI and Gen3DSR, while maintaining the efficiency of the diffusion process. Code and data will be publicly available at https://zx-yin.github.io/3dfixer.
RSGen: Enhancing Layout-Driven Remote Sensing Image Generation with Diverse Edge Guidance
Mar 17, 2026Diffusion models have significantly mitigated the impact of annotated data scarcity in remote sensing (RS). Although recent approaches have successfully harnessed these models to enable diverse and controllable Layout-to-Image (L2I) synthesis, they still suffer from limited fine-grained control and fail to strictly adhere to bounding box constraints. To address these limitations, we propose RSGen, a plug-and-play framework that leverages diverse edge guidance to enhance layout-driven RS image generation. Specifically, RSGen employs a progressive enhancement strategy: 1) it first enriches the diversity of edge maps composited from retrieved training instances via Image-to-Image generation; and 2) subsequently utilizes these diverse edge maps as conditioning for existing L2I models to enforce pixel-level control within bounding boxes, ensuring the generated instances strictly adhere to the layout. Extensive experiments across three baseline models demonstrate that RSGen significantly boosts the capabilities of existing L2I models. For instance, with CC-Diff on the DOTA dataset for oriented object detection, we achieve remarkable gains of +9.8/+12.0 in YOLOScore mAP50/mAP50-95 and +1.6 in mAP on the downstream detection task. Our code will be publicly available: https://github.com/D-Robotics-AI-Lab/RSGen
R3DP: Real-Time 3D-Aware Policy for Embodied Manipulation
Mar 15, 2026Embodied manipulation requires accurate 3D understanding of objects and their spatial relations to plan and execute contact-rich actions. While large-scale 3D vision models provide strong priors, their computational cost incurs prohibitive latency for real-time control. We propose Real-time 3D-aware Policy (R3DP), which integrates powerful 3D priors into manipulation policies without sacrificing real-time performance. A core innovation of R3DP is the asynchronous fast-slow collaboration module, which seamlessly integrates large-scale 3D priors into the policy without compromising real-time performance. The system maintains real-time efficiency by querying the pre-trained slow system (VGGT) only on sparse key frames, while simultaneously employing a lightweight Temporal Feature Prediction Network (TFPNet) to predict features for all intermediate frames. By leveraging historical data to exploit temporal correlations, TFPNet explicitly improves task success rates through consistent feature estimation. Additionally, to enable more effective multi-view fusion, we introduce a Multi-View Feature Fuser (MVFF) that aggregates features across views by explicitly incorporating camera intrinsics and extrinsics. R3DP offers a plug-and-play solution for integrating large models into real-time inference systems. We evaluate R3DP against multiple baselines across different visual configurations. R3DP effectively harnesses large-scale 3D priors to achieve superior results, outperforming single-view and multi-view DP by 32.9% and 51.4% in average success rate, respectively. Furthermore, by decoupling heavy 3D reasoning from policy execution, R3DP achieves a 44.8% reduction in inference time compared to a naive DP+VGGT integration.
Spa3R: Predictive Spatial Field Modeling for 3D Visual Reasoning
Feb 24, 2026While Vision-Language Models (VLMs) exhibit exceptional 2D visual understanding, their ability to comprehend and reason about 3D space--a cornerstone of spatial intelligence--remains superficial. Current methodologies attempt to bridge this domain gap either by relying on explicit 3D modalities or by augmenting VLMs with partial, view-conditioned geometric priors. However, such approaches hinder scalability and ultimately burden the language model with the ill-posed task of implicitly reconstructing holistic 3D geometry from sparse cues. In this paper, we argue that spatial intelligence can emerge inherently from 2D vision alone, rather than being imposed via explicit spatial instruction tuning. To this end, we introduce Spa3R, a self-supervised framework that learns a unified, view-invariant spatial representation directly from unposed multi-view images. Spa3R is built upon the proposed Predictive Spatial Field Modeling (PSFM) paradigm, where Spa3R learns to synthesize feature fields for arbitrary unseen views conditioned on a compact latent representation, thereby internalizing a holistic and coherent understanding of the underlying 3D scene. We further integrate the pre-trained Spa3R Encoder into existing VLMs via a lightweight adapter to form Spa3-VLM, effectively grounding language reasoning in a global spatial context. Experiments on the challenging VSI-Bench demonstrate that Spa3-VLM achieves state-of-the-art accuracy of 58.6% on 3D VQA, significantly outperforming prior methods. These results highlight PSFM as a scalable path toward advancing spatial intelligence. Code is available at https://github.com/hustvl/Spa3R.
UniVTAC: A Unified Simulation Platform for Visuo-Tactile Manipulation Data Generation, Learning, and Benchmarking
Feb 10, 2026Robotic manipulation has seen rapid progress with vision-language-action (VLA) policies. However, visuo-tactile perception is critical for contact-rich manipulation, as tasks such as insertion are difficult to complete robustly using vision alone. At the same time, acquiring large-scale and reliable tactile data in the physical world remains costly and challenging, and the lack of a unified evaluation platform further limits policy learning and systematic analysis. To address these challenges, we propose UniVTAC, a simulation-based visuo-tactile data synthesis platform that supports three commonly used visuo-tactile sensors and enables scalable and controllable generation of informative contact interactions. Based on this platform, we introduce the UniVTAC Encoder, a visuo-tactile encoder trained on large-scale simulation-synthesized data with designed supervisory signals, providing tactile-centric visuo-tactile representations for downstream manipulation tasks. In addition, we present the UniVTAC Benchmark, which consists of eight representative visuo-tactile manipulation tasks for evaluating tactile-driven policies. Experimental results show that integrating the UniVTAC Encoder improves average success rates by 17.1% on the UniVTAC Benchmark, while real-world robotic experiments further demonstrate a 25% improvement in task success. Our webpage is available at https://univtac.github.io/.
DreamLifting: A Plug-in Module Lifting MV Diffusion Models for 3D Asset Generation
Sep 09, 2025

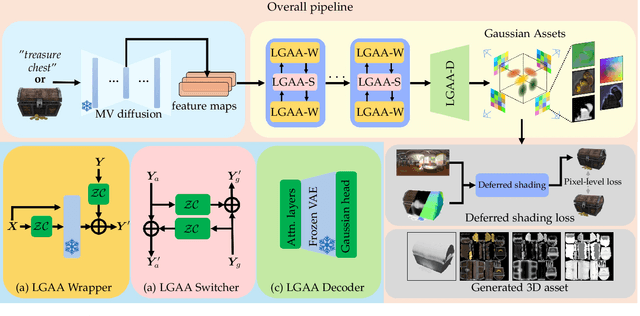

The labor- and experience-intensive creation of 3D assets with physically based rendering (PBR) materials demands an autonomous 3D asset creation pipeline. However, most existing 3D generation methods focus on geometry modeling, either baking textures into simple vertex colors or leaving texture synthesis to post-processing with image diffusion models. To achieve end-to-end PBR-ready 3D asset generation, we present Lightweight Gaussian Asset Adapter (LGAA), a novel framework that unifies the modeling of geometry and PBR materials by exploiting multi-view (MV) diffusion priors from a novel perspective. The LGAA features a modular design with three components. Specifically, the LGAA Wrapper reuses and adapts network layers from MV diffusion models, which encapsulate knowledge acquired from billions of images, enabling better convergence in a data-efficient manner. To incorporate multiple diffusion priors for geometry and PBR synthesis, the LGAA Switcher aligns multiple LGAA Wrapper layers encapsulating different knowledge. Then, a tamed variational autoencoder (VAE), termed LGAA Decoder, is designed to predict 2D Gaussian Splatting (2DGS) with PBR channels. Finally, we introduce a dedicated post-processing procedure to effectively extract high-quality, relightable mesh assets from the resulting 2DGS. Extensive quantitative and qualitative experiments demonstrate the superior performance of LGAA with both text-and image-conditioned MV diffusion models. Additionally, the modular design enables flexible incorporation of multiple diffusion priors, and the knowledge-preserving scheme leads to efficient convergence trained on merely 69k multi-view instances. Our code, pre-trained weights, and the dataset used will be publicly available via our project page: https://zx-yin.github.io/dreamlifting/.
DISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments
Jul 29, 2025We present the first unified, modular, open-source 3DGS-based simulation framework for Real2Sim2Real robot learning. It features a holistic Real2Sim pipeline that synthesizes hyper-realistic geometry and appearance of complex real-world scenarios, paving the way for analyzing and bridging the Sim2Real gap. Powered by Gaussian Splatting and MuJoCo, Discoverse enables massively parallel simulation of multiple sensor modalities and accurate physics, with inclusive supports for existing 3D assets, robot models, and ROS plugins, empowering large-scale robot learning and complex robotic benchmarks. Through extensive experiments on imitation learning, Discoverse demonstrates state-of-the-art zero-shot Sim2Real transfer performance compared to existing simulators. For code and demos: https://air-discoverse.github.io/.
Efficient Task-specific Conditional Diffusion Policies: Shortcut Model Acceleration and SO(3) Optimization
Apr 14, 2025



Imitation learning, particularly Diffusion Policies based methods, has recently gained significant traction in embodied AI as a powerful approach to action policy generation. These models efficiently generate action policies by learning to predict noise. However, conventional Diffusion Policy methods rely on iterative denoising, leading to inefficient inference and slow response times, which hinder real-time robot control. To address these limitations, we propose a Classifier-Free Shortcut Diffusion Policy (CF-SDP) that integrates classifier-free guidance with shortcut-based acceleration, enabling efficient task-specific action generation while significantly improving inference speed. Furthermore, we extend diffusion modeling to the SO(3) manifold in shortcut model, defining the forward and reverse processes in its tangent space with an isotropic Gaussian distribution. This ensures stable and accurate rotational estimation, enhancing the effectiveness of diffusion-based control. Our approach achieves nearly 5x acceleration in diffusion inference compared to DDIM-based Diffusion Policy while maintaining task performance. Evaluations both on the RoboTwin simulation platform and real-world scenarios across various tasks demonstrate the superiority of our method.
GeoFlow-SLAM: A Robust Tightly-Coupled RGBD-Inertial Fusion SLAM for Dynamic Legged Robotics
Mar 18, 2025This paper presents GeoFlow-SLAM, a robust and effective Tightly-Coupled RGBD-inertial SLAM for legged robots operating in highly dynamic environments.By integrating geometric consistency, legged odometry constraints, and dual-stream optical flow (GeoFlow), our method addresses three critical challenges:feature matching and pose initialization failures during fast locomotion and visual feature scarcity in texture-less scenes.Specifically, in rapid motion scenarios, feature matching is notably enhanced by leveraging dual-stream optical flow, which combines prior map points and poses. Additionally, we propose a robust pose initialization method for fast locomotion and IMU error in legged robots, integrating IMU/Legged odometry, inter-frame Perspective-n-Point (PnP), and Generalized Iterative Closest Point (GICP). Furthermore, a novel optimization framework that tightly couples depth-to-map and GICP geometric constraints is first introduced to improve the robustness and accuracy in long-duration, visually texture-less environments. The proposed algorithms achieve state-of-the-art (SOTA) on collected legged robots and open-source datasets. To further promote research and development, the open-source datasets and code will be made publicly available at https://github.com/NSN-Hello/GeoFlow-SLAM
Monocular Depth Estimation and Segmentation for Transparent Object with Iterative Semantic and Geometric Fusion
Feb 20, 2025Transparent object perception is indispensable for numerous robotic tasks. However, accurately segmenting and estimating the depth of transparent objects remain challenging due to complex optical properties. Existing methods primarily delve into only one task using extra inputs or specialized sensors, neglecting the valuable interactions among tasks and the subsequent refinement process, leading to suboptimal and blurry predictions. To address these issues, we propose a monocular framework, which is the first to excel in both segmentation and depth estimation of transparent objects, with only a single-image input. Specifically, we devise a novel semantic and geometric fusion module, effectively integrating the multi-scale information between tasks. In addition, drawing inspiration from human perception of objects, we further incorporate an iterative strategy, which progressively refines initial features for clearer results. Experiments on two challenging synthetic and real-world datasets demonstrate that our model surpasses state-of-the-art monocular, stereo, and multi-view methods by a large margin of about 38.8%-46.2% with only a single RGB input. Codes and models are publicly available at https://github.com/L-J-Yuan/MODEST.