 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification
Dec 11, 2025Large language models (LLMs) have achieved significant progress in solving complex reasoning tasks by Reinforcement Learning with Verifiable Rewards (RLVR). This advancement is also inseparable from the oversight automated by reliable verifiers. However, current outcome-based verifiers (OVs) are unable to inspect the unreliable intermediate steps in the long reasoning chains of thought (CoTs). Meanwhile, current process-based verifiers (PVs) have difficulties in reliably detecting errors in the complex long CoTs, limited by the scarcity of high-quality annotations due to the prohibitive costs of human annotations. Therefore, we propose the Outcome-based Process Verifier (OPV), which verifies the rationale process of summarized outcomes from long CoTs to achieve both accurate and efficient verification and enable large-scale annotation. To empower the proposed verifier, we adopt an iterative active learning framework with expert annotations to progressively improve the verification capability of OPV with fewer annotation costs. Specifically, in each iteration, the most uncertain cases of the current best OPV are annotated and then subsequently used to train a new OPV through Rejection Fine-Tuning (RFT) and RLVR for the next round. Extensive experiments demonstrate OPV's superior performance and broad applicability. It achieves new state-of-the-art results on our held-out OPV-Bench, outperforming much larger open-source models such as Qwen3-Max-Preview with an F1 score of 83.1 compared to 76.3. Furthermore, OPV effectively detects false positives within synthetic dataset, closely align with expert assessment. When collaborating with policy models, OPV consistently yields performance gains, e.g., raising the accuracy of DeepSeek-R1-Distill-Qwen-32B from 55.2% to 73.3% on AIME2025 as the compute budget scales.
MULTIBENCH++: A Unified and Comprehensive Multimodal Fusion Benchmarking Across Specialized Domains
Nov 14, 2025Although multimodal fusion has made significant progress, its advancement is severely hindered by the lack of adequate evaluation benchmarks. Current fusion methods are typically evaluated on a small selection of public datasets, a limited scope that inadequately represents the complexity and diversity of real-world scenarios, potentially leading to biased evaluations. This issue presents a twofold challenge. On one hand, models may overfit to the biases of specific datasets, hindering their generalization to broader practical applications. On the other hand, the absence of a unified evaluation standard makes fair and objective comparisons between different fusion methods difficult. Consequently, a truly universal and high-performance fusion model has yet to emerge. To address these challenges, we have developed a large-scale, domain-adaptive benchmark for multimodal evaluation. This benchmark integrates over 30 datasets, encompassing 15 modalities and 20 predictive tasks across key application domains. To complement this, we have also developed an open-source, unified, and automated evaluation pipeline that includes standardized implementations of state-of-the-art models and diverse fusion paradigms. Leveraging this platform, we have conducted large-scale experiments, successfully establishing new performance baselines across multiple tasks. This work provides the academic community with a crucial platform for rigorous and reproducible assessment of multimodal models, aiming to propel the field of multimodal artificial intelligence to new heights.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Semantic Energy: Detecting LLM Hallucination Beyond Entropy
Aug 20, 2025Large Language Models (LLMs) are being increasingly deployed in real-world applications, but they remain susceptible to hallucinations, which produce fluent yet incorrect responses and lead to erroneous decision-making. Uncertainty estimation is a feasible approach to detect such hallucinations. For example, semantic entropy estimates uncertainty by considering the semantic diversity across multiple sampled responses, thus identifying hallucinations. However, semantic entropy relies on post-softmax probabilities and fails to capture the model's inherent uncertainty, causing it to be ineffective in certain scenarios. To address this issue, we introduce Semantic Energy, a novel uncertainty estimation framework that leverages the inherent confidence of LLMs by operating directly on logits of penultimate layer. By combining semantic clustering with a Boltzmann-inspired energy distribution, our method better captures uncertainty in cases where semantic entropy fails. Experiments across multiple benchmarks show that Semantic Energy significantly improves hallucination detection and uncertainty estimation, offering more reliable signals for downstream applications such as hallucination detection.
DISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments
Jul 29, 2025We present the first unified, modular, open-source 3DGS-based simulation framework for Real2Sim2Real robot learning. It features a holistic Real2Sim pipeline that synthesizes hyper-realistic geometry and appearance of complex real-world scenarios, paving the way for analyzing and bridging the Sim2Real gap. Powered by Gaussian Splatting and MuJoCo, Discoverse enables massively parallel simulation of multiple sensor modalities and accurate physics, with inclusive supports for existing 3D assets, robot models, and ROS plugins, empowering large-scale robot learning and complex robotic benchmarks. Through extensive experiments on imitation learning, Discoverse demonstrates state-of-the-art zero-shot Sim2Real transfer performance compared to existing simulators. For code and demos: https://air-discoverse.github.io/.
MedSG-Bench: A Benchmark for Medical Image Sequences Grounding
May 17, 2025Visual grounding is essential for precise perception and reasoning in multimodal large language models (MLLMs), especially in medical imaging domains. While existing medical visual grounding benchmarks primarily focus on single-image scenarios, real-world clinical applications often involve sequential images, where accurate lesion localization across different modalities and temporal tracking of disease progression (e.g., pre- vs. post-treatment comparison) require fine-grained cross-image semantic alignment and context-aware reasoning. To remedy the underrepresentation of image sequences in existing medical visual grounding benchmarks, we propose MedSG-Bench, the first benchmark tailored for Medical Image Sequences Grounding. It comprises eight VQA-style tasks, formulated into two paradigms of the grounding tasks, including 1) Image Difference Grounding, which focuses on detecting change regions across images, and 2) Image Consistency Grounding, which emphasizes detection of consistent or shared semantics across sequential images. MedSG-Bench covers 76 public datasets, 10 medical imaging modalities, and a wide spectrum of anatomical structures and diseases, totaling 9,630 question-answer pairs. We benchmark both general-purpose MLLMs (e.g., Qwen2.5-VL) and medical-domain specialized MLLMs (e.g., HuatuoGPT-vision), observing that even the advanced models exhibit substantial limitations in medical sequential grounding tasks. To advance this field, we construct MedSG-188K, a large-scale instruction-tuning dataset tailored for sequential visual grounding, and further develop MedSeq-Grounder, an MLLM designed to facilitate future research on fine-grained understanding across medical sequential images. The benchmark, dataset, and model are available at https://huggingface.co/MedSG-Bench
scDrugMap: Benchmarking Large Foundation Models for Drug Response Prediction
May 08, 2025Drug resistance presents a major challenge in cancer therapy. Single cell profiling offers insights into cellular heterogeneity, yet the application of large-scale foundation models for predicting drug response in single cell data remains underexplored. To address this, we developed scDrugMap, an integrated framework featuring both a Python command-line interface and a web server for drug response prediction. scDrugMap evaluates a wide range of foundation models, including eight single-cell models and two large language models, using a curated dataset of over 326,000 cells in the primary collection and 18,800 cells in the validation set, spanning 36 datasets and diverse tissue and cancer types. We benchmarked model performance under pooled-data and cross-data evaluation settings, employing both layer freezing and Low-Rank Adaptation (LoRA) fine-tuning strategies. In the pooled-data scenario, scFoundation achieved the best performance, with mean F1 scores of 0.971 (layer freezing) and 0.947 (fine-tuning), outperforming the lowest-performing model by over 50%. In the cross-data setting, UCE excelled post fine-tuning (mean F1: 0.774), while scGPT led in zero-shot learning (mean F1: 0.858). Overall, scDrugMap provides the first large-scale benchmark of foundation models for drug response prediction in single-cell data and serves as a user-friendly, flexible platform for advancing drug discovery and translational research.
ClinicalGPT-R1: Pushing reasoning capability of generalist disease diagnosis with large language model
Apr 15, 2025Recent advances in reasoning with large language models (LLMs)has shown remarkable reasoning capabilities in domains such as mathematics and coding, yet their application to clinical diagnosis remains underexplored. Here, we introduce ClinicalGPT-R1, a reasoning enhanced generalist large language model for disease diagnosis. Trained on a dataset of 20,000 real-world clinical records, ClinicalGPT-R1 leverages diverse training strategies to enhance diagnostic reasoning. To benchmark performance, we curated MedBench-Hard, a challenging dataset spanning seven major medical specialties and representative diseases. Experimental results demonstrate that ClinicalGPT-R1 outperforms GPT-4o in Chinese diagnostic tasks and achieves comparable performance to GPT-4 in English settings. This comparative study effectively validates the superior performance of ClinicalGPT-R1 in disease diagnosis tasks. Resources are available at https://github.com/medfound/medfound.
Privacy-Preserving Federated Foundation Model for Generalist Ultrasound Artificial Intelligence
Nov 25, 2024



Ultrasound imaging is widely used in clinical diagnosis due to its non-invasive nature and real-time capabilities. However, conventional ultrasound diagnostics face several limitations, including high dependence on physician expertise and suboptimal image quality, which complicates interpretation and increases the likelihood of diagnostic errors. Artificial intelligence (AI) has emerged as a promising solution to enhance clinical diagnosis, particularly in detecting abnormalities across various biomedical imaging modalities. Nonetheless, current AI models for ultrasound imaging face critical challenges. First, these models often require large volumes of labeled medical data, raising concerns over patient privacy breaches. Second, most existing models are task-specific, which restricts their broader clinical utility. To overcome these challenges, we present UltraFedFM, an innovative privacy-preserving ultrasound foundation model. UltraFedFM is collaboratively pre-trained using federated learning across 16 distributed medical institutions in 9 countries, leveraging a dataset of over 1 million ultrasound images covering 19 organs and 10 ultrasound modalities. This extensive and diverse data, combined with a secure training framework, enables UltraFedFM to exhibit strong generalization and diagnostic capabilities. It achieves an average area under the receiver operating characteristic curve of 0.927 for disease diagnosis and a dice similarity coefficient of 0.878 for lesion segmentation. Notably, UltraFedFM surpasses the diagnostic accuracy of mid-level ultrasonographers and matches the performance of expert-level sonographers in the joint diagnosis of 8 common systemic diseases. These findings indicate that UltraFedFM can significantly enhance clinical diagnostics while safeguarding patient privacy, marking an advancement in AI-driven ultrasound imaging for future clinical applications.
A Time Series is Worth Five Experts: Heterogeneous Mixture of Experts for Traffic Flow Prediction
Sep 26, 2024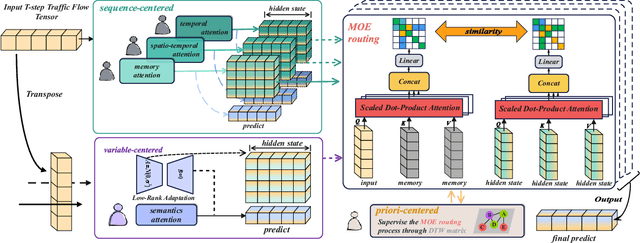
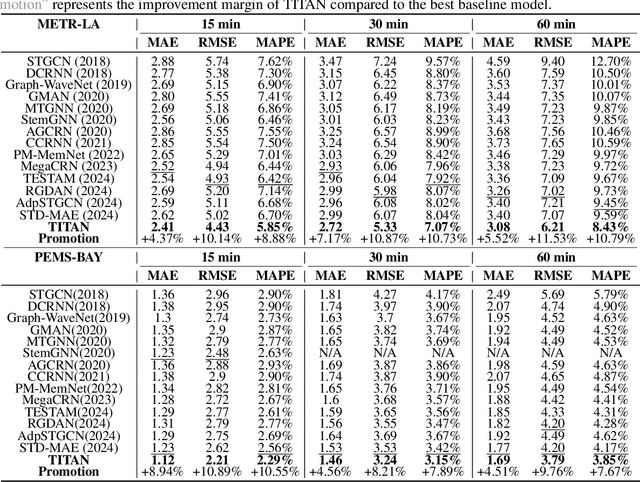
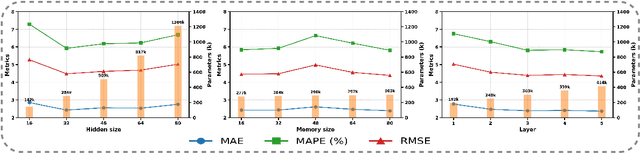
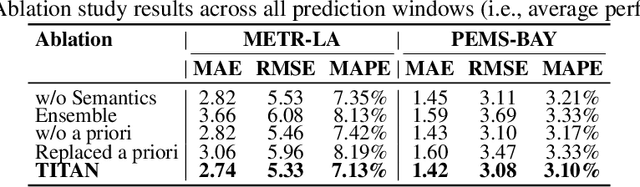
Accurate traffic prediction faces significant challenges, necessitating a deep understanding of both temporal and spatial cues and their complex interactions across multiple variables. Recent advancements in traffic prediction systems are primarily due to the development of complex sequence-centric models. However, existing approaches often embed multiple variables and spatial relationships at each time step, which may hinder effective variable-centric learning, ultimately leading to performance degradation in traditional traffic prediction tasks. To overcome these limitations, we introduce variable-centric and prior knowledge-centric modeling techniques. Specifically, we propose a Heterogeneous Mixture of Experts (TITAN) model for traffic flow prediction. TITAN initially consists of three experts focused on sequence-centric modeling. Then, designed a low-rank adaptive method, TITAN simultaneously enables variable-centric modeling. Furthermore, we supervise the gating process using a prior knowledge-centric modeling strategy to ensure accurate routing. Experiments on two public traffic network datasets, METR-LA and PEMS-BAY, demonstrate that TITAN effectively captures variable-centric dependencies while ensuring accurate routing. Consequently, it achieves improvements in all evaluation metrics, ranging from approximately 4.37\% to 11.53\%, compared to previous state-of-the-art (SOTA) models. The code is open at \href{https://github.com/sqlcow/TITAN}{https://github.com/sqlcow/TITAN}.