 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Correlation Between Vision and Language for Precise Medical AI Assistant
May 06, 2025Medical AI assistants support doctors in disease diagnosis, medical image analysis, and report generation. However, they still face significant challenges in clinical use, including limited accuracy with multimodal content and insufficient validation in real-world settings. We propose RCMed, a full-stack AI assistant that improves multimodal alignment in both input and output, enabling precise anatomical delineation, accurate localization, and reliable diagnosis through hierarchical vision-language grounding. A self-reinforcing correlation mechanism allows visual features to inform language context, while language semantics guide pixel-wise attention, forming a closed loop that refines both modalities. This correlation is enhanced by a color region description strategy, translating anatomical structures into semantically rich text to learn shape-location-text relationships across scales. Trained on 20 million image-mask-description triplets, RCMed achieves state-of-the-art precision in contextualizing irregular lesions and subtle anatomical boundaries, excelling in 165 clinical tasks across 9 modalities. It achieved a 23.5% relative improvement in cell segmentation from microscopy images over prior methods. RCMed's strong vision-language alignment enables exceptional generalization, with state-of-the-art performance in external validation across 20 clinically significant cancer types, including novel tasks. This work demonstrates how integrated multimodal models capture fine-grained patterns, enabling human-level interpretation in complex scenarios and advancing human-centric AI healthcare.
Interpretable Bilingual Multimodal Large Language Model for Diverse Biomedical Tasks
Oct 24, 2024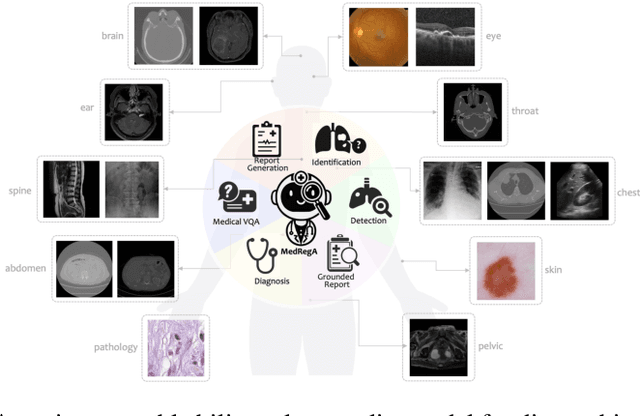

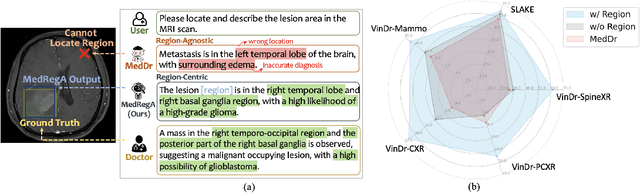

Several medical Multimodal Large Languange Models (MLLMs) have been developed to address tasks involving visual images with textual instructions across various medical modalities, achieving impressive results. Most current medical generalist models are region-agnostic, treating the entire image as a holistic representation. However, they struggle to identify which specific regions they are focusing on when generating a sentence.To mimic the behavior of doctors, who typically begin by reviewing the entire image before concentrating on specific regions for a thorough evaluation, we aim to enhance the capability of medical MLLMs in understanding anatomical regions within entire medical scans. To achieve it, we first formulate Region-Centric tasks and construct a large-scale dataset, MedRegInstruct, to incorporate regional information into training. Combining our collected dataset with other medical multimodal corpora for training, we propose a Region-Aware medical MLLM, MedRegA, which is the first bilingual generalist medical AI system to simultaneously handle image-level and region-level medical vision-language tasks across a broad range of modalities. Our MedRegA not only enables three region-centric tasks, but also achieves the best performance for visual question answering, report generation and medical image classification over 8 modalities, showcasing significant versatility. Experiments demonstrate that our model can not only accomplish powerful performance across various medical vision-language tasks in bilingual settings, but also recognize and detect structures in multimodal medical scans, boosting the interpretability and user interactivity of medical MLLMs. Our project page is https://medrega.github.io.
Expert-level vision-language foundation model for real-world radiology and comprehensive evaluation
Sep 24, 2024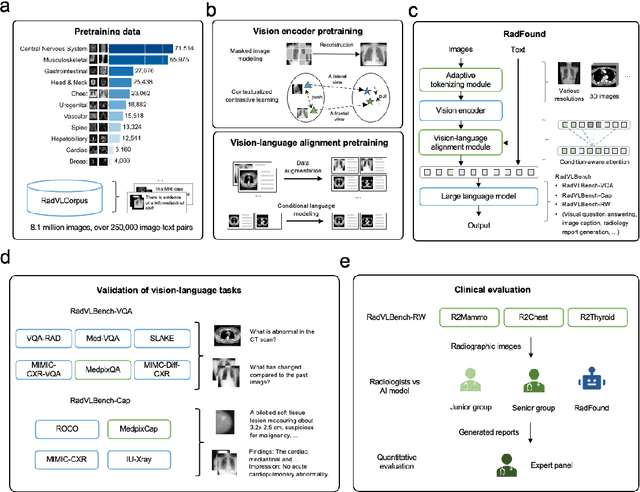
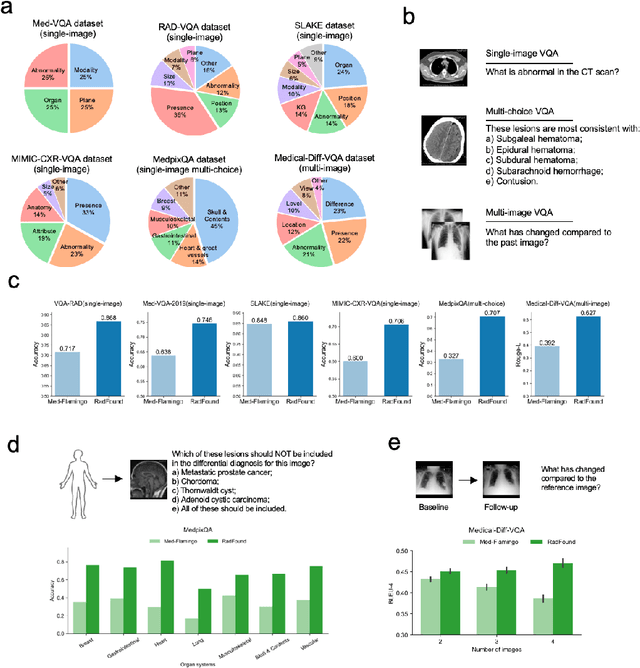
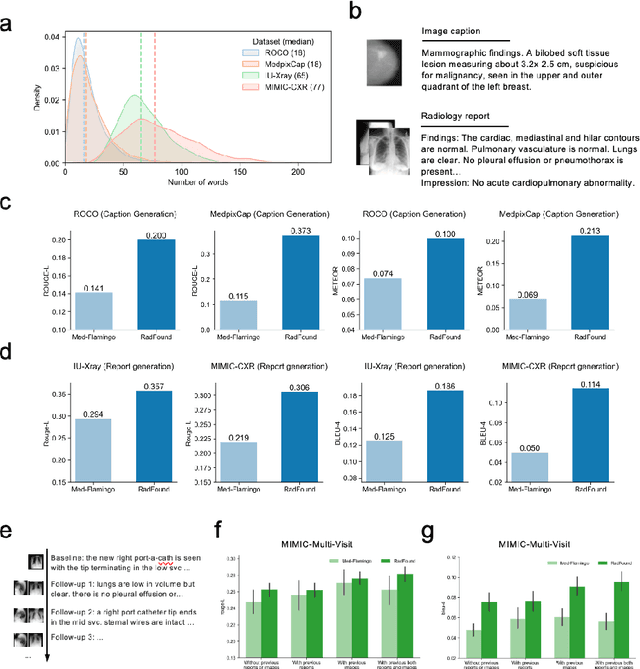
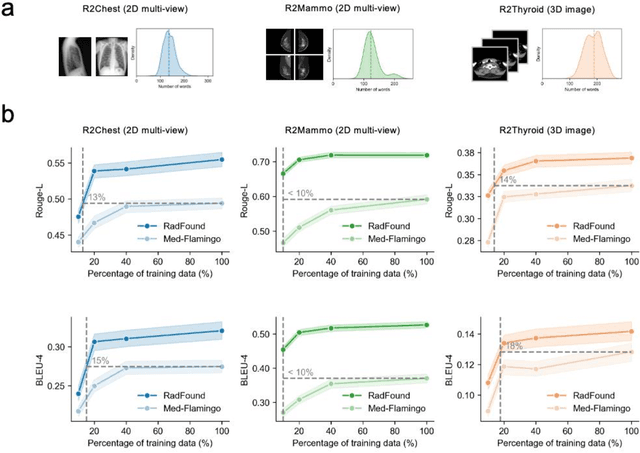
Radiology is a vital and complex component of modern clinical workflow and covers many tasks. Recently, vision-language (VL) foundation models in medicine have shown potential in processing multimodal information, offering a unified solution for various radiology tasks. However, existing studies either pre-trained VL models on natural data or did not fully integrate vision-language architecture and pretraining, often neglecting the unique multimodal complexity in radiology images and their textual contexts. Additionally, their practical applicability in real-world scenarios remains underexplored. Here, we present RadFound, a large and open-source vision-language foundation model tailored for radiology, that is trained on the most extensive dataset of over 8.1 million images and 250,000 image-text pairs, covering 19 major organ systems and 10 imaging modalities. To establish expert-level multimodal perception and generation capabilities, RadFound introduces an enhanced vision encoder to capture intra-image local features and inter-image contextual information, and a unified cross-modal learning design tailored to radiology. To fully assess the models' capability, we construct a benchmark, RadVLBench, including radiology interpretation tasks like medical vision-language question-answering, as well as text generation tasks ranging from captioning to report generation. We also propose a human evaluation framework. When evaluated on the real-world benchmark involving three representative modalities, 2D images (chest X-rays), multi-view images (mammograms), and 3D images (thyroid CT scans), RadFound significantly outperforms other VL foundation models on both quantitative metrics and human evaluation. In summary, the development of RadFound represents an advancement in radiology generalists, demonstrating broad applicability potential for integration into clinical workflows.