 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Cardiologist-Like Reasoning in MLLMs for Interpretable Echocardiographic Diagnosis
Jan 13, 2026Echocardiographic diagnosis is vital for cardiac screening yet remains challenging. Existing echocardiography foundation models do not effectively capture the relationships between quantitative measurements and clinical manifestations, whereas medical reasoning multimodal large language models (MLLMs) require costly construction of detailed reasoning paths and remain ineffective at directly incorporating such echocardiographic priors into their reasoning. To address these limitations, we propose a novel approach comprising Cardiac Reasoning Template (CRT) and CardiacMind to enhance MLLM's echocardiographic reasoning by introducing cardiologist-like mindset. Specifically, CRT provides stepwise canonical diagnostic procedures for complex cardiac diseases to streamline reasoning path construction without the need for costly case-by-case verification. To incentivize reasoning MLLM under CRT, we develop CardiacMind, a new reinforcement learning scheme with three novel rewards: Procedural Quantity Reward (PQtR), Procedural Quality Reward (PQlR), and Echocardiographic Semantic Reward (ESR). PQtR promotes detailed reasoning; PQlR promotes integration of evidence across views and modalities, while ESR grounds stepwise descriptions in visual content. Our methods show a 48% improvement in multiview echocardiographic diagnosis for 15 complex cardiac diseases and a 5% improvement on CardiacNet-PAH over prior methods. The user study on our method's reasoning outputs shows 93.33% clinician agreement with cardiologist-like reasoning logic. Our code will be available.
Multi-Modal Explainable Medical AI Assistant for Trustworthy Human-AI Collaboration
May 11, 2025Generalist Medical AI (GMAI) systems have demonstrated expert-level performance in biomedical perception tasks, yet their clinical utility remains limited by inadequate multi-modal explainability and suboptimal prognostic capabilities. Here, we present XMedGPT, a clinician-centric, multi-modal AI assistant that integrates textual and visual interpretability to support transparent and trustworthy medical decision-making. XMedGPT not only produces accurate diagnostic and descriptive outputs, but also grounds referenced anatomical sites within medical images, bridging critical gaps in interpretability and enhancing clinician usability. To support real-world deployment, we introduce a reliability indexing mechanism that quantifies uncertainty through consistency-based assessment via interactive question-answering. We validate XMedGPT across four pillars: multi-modal interpretability, uncertainty quantification, and prognostic modeling, and rigorous benchmarking. The model achieves an IoU of 0.703 across 141 anatomical regions, and a Kendall's tau-b of 0.479, demonstrating strong alignment between visual rationales and clinical outcomes. For uncertainty estimation, it attains an AUC of 0.862 on visual question answering and 0.764 on radiology report generation. In survival and recurrence prediction for lung and glioma cancers, it surpasses prior leading models by 26.9%, and outperforms GPT-4o by 25.0%. Rigorous benchmarking across 347 datasets covers 40 imaging modalities and external validation spans 4 anatomical systems confirming exceptional generalizability, with performance gains surpassing existing GMAI by 20.7% for in-domain evaluation and 16.7% on 11,530 in-house data evaluation. Together, XMedGPT represents a significant leap forward in clinician-centric AI integration, offering trustworthy and scalable support for diverse healthcare applications.
Reinforced Correlation Between Vision and Language for Precise Medical AI Assistant
May 06, 2025Medical AI assistants support doctors in disease diagnosis, medical image analysis, and report generation. However, they still face significant challenges in clinical use, including limited accuracy with multimodal content and insufficient validation in real-world settings. We propose RCMed, a full-stack AI assistant that improves multimodal alignment in both input and output, enabling precise anatomical delineation, accurate localization, and reliable diagnosis through hierarchical vision-language grounding. A self-reinforcing correlation mechanism allows visual features to inform language context, while language semantics guide pixel-wise attention, forming a closed loop that refines both modalities. This correlation is enhanced by a color region description strategy, translating anatomical structures into semantically rich text to learn shape-location-text relationships across scales. Trained on 20 million image-mask-description triplets, RCMed achieves state-of-the-art precision in contextualizing irregular lesions and subtle anatomical boundaries, excelling in 165 clinical tasks across 9 modalities. It achieved a 23.5% relative improvement in cell segmentation from microscopy images over prior methods. RCMed's strong vision-language alignment enables exceptional generalization, with state-of-the-art performance in external validation across 20 clinically significant cancer types, including novel tasks. This work demonstrates how integrated multimodal models capture fine-grained patterns, enabling human-level interpretation in complex scenarios and advancing human-centric AI healthcare.
Neurons: Emulating the Human Visual Cortex Improves Fidelity and Interpretability in fMRI-to-Video Reconstruction
Mar 14, 2025


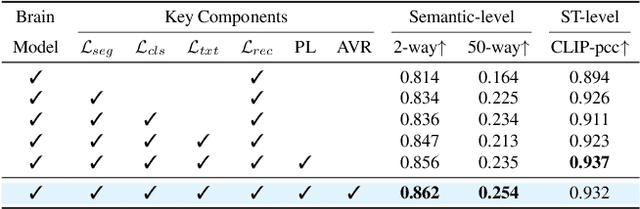
Decoding visual stimuli from neural activity is essential for understanding the human brain. While fMRI methods have successfully reconstructed static images, fMRI-to-video reconstruction faces challenges due to the need for capturing spatiotemporal dynamics like motion and scene transitions. Recent approaches have improved semantic and perceptual alignment but struggle to integrate coarse fMRI data with detailed visual features. Inspired by the hierarchical organization of the visual system, we propose NEURONS, a novel framework that decouples learning into four correlated sub-tasks: key object segmentation, concept recognition, scene description, and blurry video reconstruction. This approach simulates the visual cortex's functional specialization, allowing the model to capture diverse video content. In the inference stage, NEURONS generates robust conditioning signals for a pre-trained text-to-video diffusion model to reconstruct the videos. Extensive experiments demonstrate that NEURONS outperforms state-of-the-art baselines, achieving solid improvements in video consistency (26.6%) and semantic-level accuracy (19.1%). Notably, NEURONS shows a strong functional correlation with the visual cortex, highlighting its potential for brain-computer interfaces and clinical applications. Code and model weights will be available at: https://github.com/xmed-lab/NEURONS.
MultiEYE: Dataset and Benchmark for OCT-Enhanced Retinal Disease Recognition from Fundus Images
Dec 12, 2024



Existing multi-modal learning methods on fundus and OCT images mostly require both modalities to be available and strictly paired for training and testing, which appears less practical in clinical scenarios. To expand the scope of clinical applications, we formulate a novel setting, "OCT-enhanced disease recognition from fundus images", that allows for the use of unpaired multi-modal data during the training phase and relies on the widespread fundus photographs for testing. To benchmark this setting, we present the first large multi-modal multi-class dataset for eye disease diagnosis, MultiEYE, and propose an OCT-assisted Conceptual Distillation Approach (OCT-CoDA), which employs semantically rich concepts to extract disease-related knowledge from OCT images and leverage them into the fundus model. Specifically, we regard the image-concept relation as a link to distill useful knowledge from the OCT teacher model to the fundus student model, which considerably improves the diagnostic performance based on fundus images and formulates the cross-modal knowledge transfer into an explainable process. Through extensive experiments on the multi-disease classification task, our proposed OCT-CoDA demonstrates remarkable results and interpretability, showing great potential for clinical application. Our dataset and code are available at https://github.com/xmed-lab/MultiEYE.
Interpretable Bilingual Multimodal Large Language Model for Diverse Biomedical Tasks
Oct 24, 2024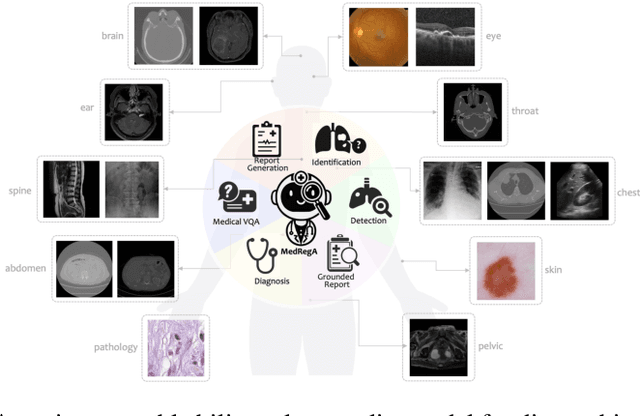

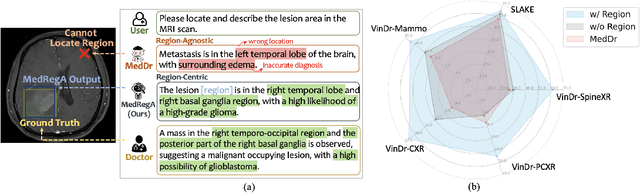

Several medical Multimodal Large Languange Models (MLLMs) have been developed to address tasks involving visual images with textual instructions across various medical modalities, achieving impressive results. Most current medical generalist models are region-agnostic, treating the entire image as a holistic representation. However, they struggle to identify which specific regions they are focusing on when generating a sentence.To mimic the behavior of doctors, who typically begin by reviewing the entire image before concentrating on specific regions for a thorough evaluation, we aim to enhance the capability of medical MLLMs in understanding anatomical regions within entire medical scans. To achieve it, we first formulate Region-Centric tasks and construct a large-scale dataset, MedRegInstruct, to incorporate regional information into training. Combining our collected dataset with other medical multimodal corpora for training, we propose a Region-Aware medical MLLM, MedRegA, which is the first bilingual generalist medical AI system to simultaneously handle image-level and region-level medical vision-language tasks across a broad range of modalities. Our MedRegA not only enables three region-centric tasks, but also achieves the best performance for visual question answering, report generation and medical image classification over 8 modalities, showcasing significant versatility. Experiments demonstrate that our model can not only accomplish powerful performance across various medical vision-language tasks in bilingual settings, but also recognize and detect structures in multimodal medical scans, boosting the interpretability and user interactivity of medical MLLMs. Our project page is https://medrega.github.io.
Age of Information Guaranteed Scheduling for Asynchronous Status Updates in Collaborative Perception
Oct 07, 2023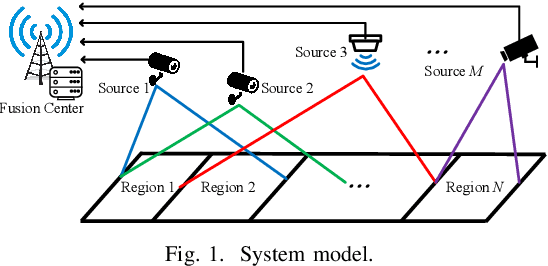
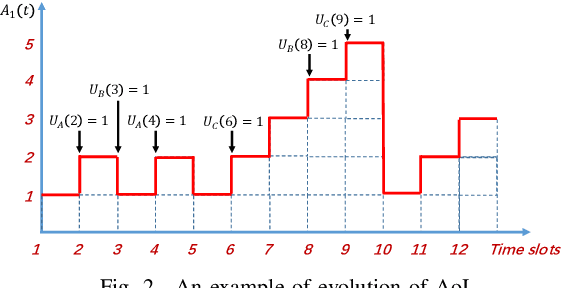
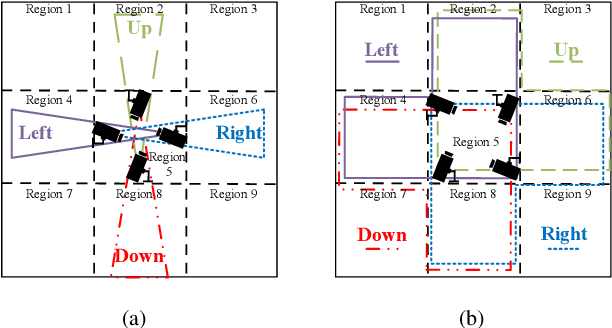
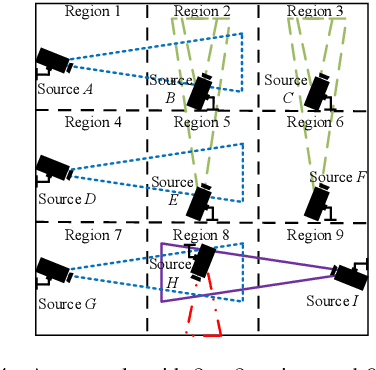
We consider collaborative perception (CP) systems where a fusion center monitors various regions by multiple sources. The center has different age of information (AoI) constraints for different regions. Multi-view sensing data for a region generated by sources can be fused by the center for a reliable representation of the region. To ensure accurate perception, differences between generation time of asynchronous status updates for CP fusion should not exceed a certain threshold. An algorithm named scheduling for CP with asynchronous status updates (SCPA) is proposed to minimize the number of required channels and subject to AoI constraints with asynchronous status updates. SCPA first identifies a set of sources that can satisfy the constraints with minimum updating rates. It then chooses scheduling intervals and offsets for the sources such that the number of required channels is optimized. According to numerical results, the number of channels required by SCPA can reach only 12% more than a derived lower bound.
A Grouping-based Scheduler for Efficient Channel Utilization under Age of Information Constraints
Oct 07, 2023We consider a status information updating system where a fusion center collects the status information from a large number of sources and each of them has its own age of information (AoI) constraints. A novel grouping-based scheduler is proposed to solve this complex large-scale problem by dividing the sources into different scheduling groups. The problem is then transformed into deriving the optimal grouping scheme. A two-step grouping algorithm (TGA) is proposed: 1) Given AoI constraints, we first identify the sources with harmonic AoI constraints, then design a fast grouping method and an optimal scheduler for these sources. Under harmonic AoI constraints, each constraint is divisible by the smallest one and the sum of reciprocals of the constraints with the same value is divisible by the reciprocal of the smallest one. 2) For the other sources without such a special property, we pack the sources which can be scheduled together with minimum update rates into the same group. Simulations show the channel usage of the proposed TGA is significantly reduced as compared to a recent work and is 0.42% larger than a derived lower bound when the number of sources is large.
Fundus-Enhanced Disease-Aware Distillation Model for Retinal Disease Classification from OCT Images
Aug 01, 2023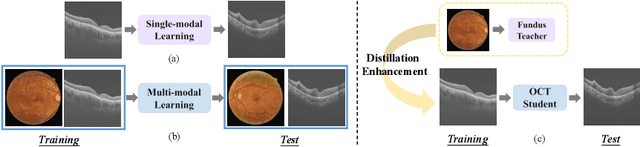

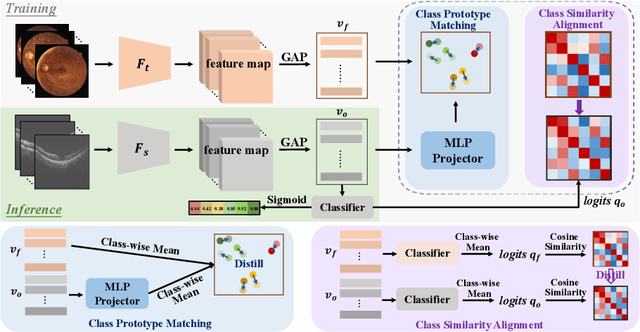
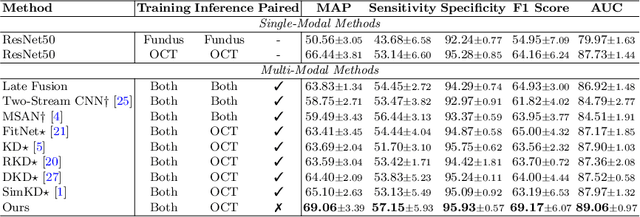
Optical Coherence Tomography (OCT) is a novel and effective screening tool for ophthalmic examination. Since collecting OCT images is relatively more expensive than fundus photographs, existing methods use multi-modal learning to complement limited OCT data with additional context from fundus images. However, the multi-modal framework requires eye-paired datasets of both modalities, which is impractical for clinical use. To address this problem, we propose a novel fundus-enhanced disease-aware distillation model (FDDM), for retinal disease classification from OCT images. Our framework enhances the OCT model during training by utilizing unpaired fundus images and does not require the use of fundus images during testing, which greatly improves the practicality and efficiency of our method for clinical use. Specifically, we propose a novel class prototype matching to distill disease-related information from the fundus model to the OCT model and a novel class similarity alignment to enforce consistency between disease distribution of both modalities. Experimental results show that our proposed approach outperforms single-modal, multi-modal, and state-of-the-art distillation methods for retinal disease classification. Code is available at https://github.com/xmed-lab/FDDM.