 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKANFIS A Neuro-Symbolic Framework for Interpretable and Uncertainty-Aware Learning
Feb 03, 2026Adaptive Neuro-Fuzzy Inference System (ANFIS) was designed to combine the learning capabilities of neural network with the reasoning transparency of fuzzy logic. However, conventional ANFIS architectures suffer from structural complexity, where the product-based inference mechanism causes an exponential explosion of rules in high-dimensional spaces. We herein propose the Kolmogorov-Arnold Neuro-Fuzzy Inference System (KANFIS), a compact neuro-symbolic architecture that unifies fuzzy reasoning with additive function decomposition. KANFIS employs an additive aggregation mechanism, under which both model parameters and rule complexity scale linearly with input dimensionality rather than exponentially. Furthermore, KANFIS is compatible with both Type-1 (T1) and Interval Type-2 (IT2) fuzzy logic systems, enabling explicit modeling of uncertainty and ambiguity in fuzzy representations. By using sparse masking mechanisms, KANFIS generates compact and structured rule sets, resulting in an intrinsically interpretable model with clear rule semantics and transparent inference processes. Empirical results demonstrate that KANFIS achieves competitive performance against representative neural and neuro-fuzzy baselines.
CFLight: Enhancing Safety with Traffic Signal Control through Counterfactual Learning
Dec 16, 2025Traffic accidents result in millions of injuries and fatalities globally, with a significant number occurring at intersections each year. Traffic Signal Control (TSC) is an effective strategy for enhancing safety at these urban junctures. Despite the growing popularity of Reinforcement Learning (RL) methods in optimizing TSC, these methods often prioritize driving efficiency over safety, thus failing to address the critical balance between these two aspects. Additionally, these methods usually need more interpretability. CounterFactual (CF) learning is a promising approach for various causal analysis fields. In this study, we introduce a novel framework to improve RL for safety aspects in TSC. This framework introduces a novel method based on CF learning to address the question: ``What if, when an unsafe event occurs, we backtrack to perform alternative actions, and will this unsafe event still occur in the subsequent period?'' To answer this question, we propose a new structure causal model to predict the result after executing different actions, and we propose a new CF module that integrates with additional ``X'' modules to promote safe RL practices. Our new algorithm, CFLight, which is derived from this framework, effectively tackles challenging safety events and significantly improves safety at intersections through a near-zero collision control strategy. Through extensive numerical experiments on both real-world and synthetic datasets, we demonstrate that CFLight reduces collisions and improves overall traffic performance compared to conventional RL methods and the recent safe RL model. Moreover, our method represents a generalized and safe framework for RL methods, opening possibilities for applications in other domains. The data and code are available in the github https://github.com/AdvancedAI-ComplexSystem/SmartCity/tree/main/CFLight.
Carbon Price Forecasting with Structural Breaks: A Comparative Study of Deep Learning Models
Nov 07, 2025Accurately forecasting carbon prices is essential for informed energy market decision-making, guiding sustainable energy planning, and supporting effective decarbonization strategies. However, it remains challenging due to structural breaks and high-frequency noise caused by frequent policy interventions and market shocks. Existing studies, including the most recent baseline approaches, have attempted to incorporate breakpoints but often treat denoising and modeling as separate processes and lack systematic evaluation across advanced deep learning architectures, limiting the robustness and the generalization capability. To address these gaps, this paper proposes a comprehensive hybrid framework that integrates structural break detection (Bai-Perron, ICSS, and PELT algorithms), wavelet signal denoising, and three state-of-the-art deep learning models (LSTM, GRU, and TCN). Using European Union Allowance (EUA) spot prices from 2007 to 2024 and exogenous features such as energy prices and policy indicators, the framework constructs univariate and multivariate datasets for comparative evaluation. Experimental results demonstrate that our proposed PELT-WT-TCN achieves the highest prediction accuracy, reducing forecasting errors by 22.35% in RMSE and 18.63% in MAE compared to the state-of-the-art baseline model (Breakpoints with Wavelet and LSTM), and by 70.55% in RMSE and 74.42% in MAE compared to the original LSTM without decomposition from the same baseline study. These findings underscore the value of integrating structural awareness and multiscale decomposition into deep learning architectures to enhance accuracy and interpretability in carbon price forecasting and other nonstationary financial time series.
FedDifRC: Unlocking the Potential of Text-to-Image Diffusion Models in Heterogeneous Federated Learning
Jul 09, 2025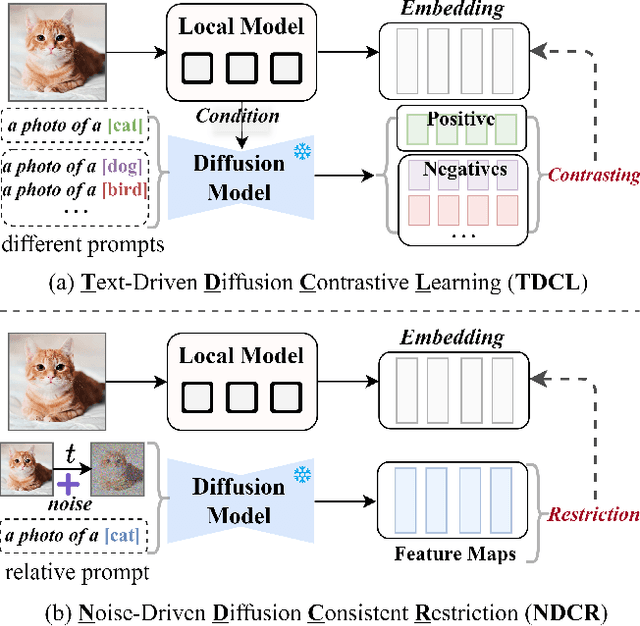



Federated learning aims at training models collaboratively across participants while protecting privacy. However, one major challenge for this paradigm is the data heterogeneity issue, where biased data preferences across multiple clients, harming the model's convergence and performance. In this paper, we first introduce powerful diffusion models into the federated learning paradigm and show that diffusion representations are effective steers during federated training. To explore the possibility of using diffusion representations in handling data heterogeneity, we propose a novel diffusion-inspired Federated paradigm with Diffusion Representation Collaboration, termed FedDifRC, leveraging meaningful guidance of diffusion models to mitigate data heterogeneity. The key idea is to construct text-driven diffusion contrasting and noise-driven diffusion regularization, aiming to provide abundant class-related semantic information and consistent convergence signals. On the one hand, we exploit the conditional feedback from the diffusion model for different text prompts to build a text-driven contrastive learning strategy. On the other hand, we introduce a noise-driven consistency regularization to align local instances with diffusion denoising representations, constraining the optimization region in the feature space. In addition, FedDifRC can be extended to a self-supervised scheme without relying on any labeled data. We also provide a theoretical analysis for FedDifRC to ensure convergence under non-convex objectives. The experiments on different scenarios validate the effectiveness of FedDifRC and the efficiency of crucial components.
FedSC: Federated Learning with Semantic-Aware Collaboration
Jun 26, 2025



Federated learning (FL) aims to train models collaboratively across clients without sharing data for privacy-preserving. However, one major challenge is the data heterogeneity issue, which refers to the biased labeling preferences at multiple clients. A number of existing FL methods attempt to tackle data heterogeneity locally (e.g., regularizing local models) or globally (e.g., fine-tuning global model), often neglecting inherent semantic information contained in each client. To explore the possibility of using intra-client semantically meaningful knowledge in handling data heterogeneity, in this paper, we propose Federated Learning with Semantic-Aware Collaboration (FedSC) to capture client-specific and class-relevant knowledge across heterogeneous clients. The core idea of FedSC is to construct relational prototypes and consistent prototypes at semantic-level, aiming to provide fruitful class underlying knowledge and stable convergence signals in a prototype-wise collaborative way. On the one hand, FedSC introduces an inter-contrastive learning strategy to bring instance-level embeddings closer to relational prototypes with the same semantics and away from distinct classes. On the other hand, FedSC devises consistent prototypes via a discrepancy aggregation manner, as a regularization penalty to constrain the optimization region of the local model. Moreover, a theoretical analysis for FedSC is provided to ensure a convergence guarantee. Experimental results on various challenging scenarios demonstrate the effectiveness of FedSC and the efficiency of crucial components.
FedSKC: Federated Learning with Non-IID Data via Structural Knowledge Collaboration
May 25, 2025With the advancement of edge computing, federated learning (FL) displays a bright promise as a privacy-preserving collaborative learning paradigm. However, one major challenge for FL is the data heterogeneity issue, which refers to the biased labeling preferences among multiple clients, negatively impacting convergence and model performance. Most previous FL methods attempt to tackle the data heterogeneity issue locally or globally, neglecting underlying class-wise structure information contained in each client. In this paper, we first study how data heterogeneity affects the divergence of the model and decompose it into local, global, and sampling drift sub-problems. To explore the potential of using intra-client class-wise structural knowledge in handling these drifts, we thus propose Federated Learning with Structural Knowledge Collaboration (FedSKC). The key idea of FedSKC is to extract and transfer domain preferences from inter-client data distributions, offering diverse class-relevant knowledge and a fair convergent signal. FedSKC comprises three components: i) local contrastive learning, to prevent weight divergence resulting from local training; ii) global discrepancy aggregation, which addresses the parameter deviation between the server and clients; iii) global period review, correcting for the sampling drift introduced by the server randomly selecting devices. We have theoretically analyzed FedSKC under non-convex objectives and empirically validated its superiority through extensive experimental results.
DECT-based Space-Squeeze Method for Multi-Class Classification of Metastatic Lymph Nodes in Breast Cancer
May 23, 2025Background: Accurate assessment of metastatic burden in axillary lymph nodes is crucial for guiding breast cancer treatment decisions, yet conventional imaging modalities struggle to differentiate metastatic burden levels and capture comprehensive lymph node characteristics. This study leverages dual-energy computed tomography (DECT) to exploit spectral-spatial information for improved multi-class classification. Purpose: To develop a noninvasive DECT-based model classifying sentinel lymph nodes into three categories: no metastasis ($N_0$), low metastatic burden ($N_{+(1-2)}$), and heavy metastatic burden ($N_{+(\geq3)}$), thereby aiding therapeutic planning. Methods: We propose a novel space-squeeze method combining two innovations: (1) a channel-wise attention mechanism to compress and recalibrate spectral-spatial features across 11 energy levels, and (2) virtual class injection to sharpen inter-class boundaries and compact intra-class variations in the representation space. Results: Evaluated on 227 biopsy-confirmed cases, our method achieved an average test AUC of 0.86 (95% CI: 0.80-0.91) across three cross-validation folds, outperforming established CNNs (VGG, ResNet, etc). The channel-wise attention and virtual class components individually improved AUC by 5.01% and 5.87%, respectively, demonstrating complementary benefits. Conclusions: The proposed framework enhances diagnostic AUC by effectively integrating DECT's spectral-spatial data and mitigating class ambiguity, offering a promising tool for noninvasive metastatic burden assessment in clinical practice.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
Reinforced Correlation Between Vision and Language for Precise Medical AI Assistant
May 06, 2025Medical AI assistants support doctors in disease diagnosis, medical image analysis, and report generation. However, they still face significant challenges in clinical use, including limited accuracy with multimodal content and insufficient validation in real-world settings. We propose RCMed, a full-stack AI assistant that improves multimodal alignment in both input and output, enabling precise anatomical delineation, accurate localization, and reliable diagnosis through hierarchical vision-language grounding. A self-reinforcing correlation mechanism allows visual features to inform language context, while language semantics guide pixel-wise attention, forming a closed loop that refines both modalities. This correlation is enhanced by a color region description strategy, translating anatomical structures into semantically rich text to learn shape-location-text relationships across scales. Trained on 20 million image-mask-description triplets, RCMed achieves state-of-the-art precision in contextualizing irregular lesions and subtle anatomical boundaries, excelling in 165 clinical tasks across 9 modalities. It achieved a 23.5% relative improvement in cell segmentation from microscopy images over prior methods. RCMed's strong vision-language alignment enables exceptional generalization, with state-of-the-art performance in external validation across 20 clinically significant cancer types, including novel tasks. This work demonstrates how integrated multimodal models capture fine-grained patterns, enabling human-level interpretation in complex scenarios and advancing human-centric AI healthcare.
FuzzyLight: A Robust Two-Stage Fuzzy Approach for Traffic Signal Control Works in Real Cities
Jan 27, 2025Effective traffic signal control (TSC) is crucial in mitigating urban congestion and reducing emissions. Recently, reinforcement learning (RL) has been the research trend for TSC. However, existing RL algorithms face several real-world challenges that hinder their practical deployment in TSC: (1) Sensor accuracy deteriorates with increased sensor detection range, and data transmission is prone to noise, potentially resulting in unsafe TSC decisions. (2) During the training of online RL, interactions with the environment could be unstable, potentially leading to inappropriate traffic signal phase (TSP) selection and traffic congestion. (3) Most current TSC algorithms focus only on TSP decisions, overlooking the critical aspect of phase duration, affecting safety and efficiency. To overcome these challenges, we propose a robust two-stage fuzzy approach called FuzzyLight, which integrates compressed sensing and RL for TSC deployment. FuzzyLight offers several key contributions: (1) It employs fuzzy logic and compressed sensing to address sensor noise and enhances the efficiency of TSP decisions. (2) It maintains stable performance during training and combines fuzzy logic with RL to generate precise phases. (3) It works in real cities across 22 intersections and demonstrates superior performance in both real-world and simulated environments. Experimental results indicate that FuzzyLight enhances traffic efficiency by 48% compared to expert-designed timings in the real world. Furthermore, it achieves state-of-the-art (SOTA) performance in simulated environments using six real-world datasets with transmission noise. The code and deployment video are available at the URL1