 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthEmbeddingExplorer: A Web Application for Cross-Modal Retrieval of Global Satellite Images
Mar 31, 2026While the Earth observation community has witnessed a surge in high-impact foundation models and global Earth embedding datasets, a significant barrier remains in translating these academic assets into freely accessible tools. This tutorial introduces EarthEmbeddingExplorer, an interactive web application designed to bridge this gap, transforming static research artifacts into dynamic, practical workflows for discovery. We will provide a comprehensive hands-on guide to the system, detailing its cloud-native software architecture, demonstrating cross-modal queries (natural language, visual, and geolocation), and showcasing how to derive scientific insights from retrieval results. By democratizing access to precomputed Earth embeddings, this tutorial empowers researchers to seamlessly transition from state-of-the-art models and data archives to real-world application and analysis. The web application is available at https://modelscope.ai/studios/Major-TOM/EarthEmbeddingExplorer.
VULCAN: Tool-Augmented Multi Agents for Iterative 3D Object Arrangement
Dec 26, 2025Despite the remarkable progress of Multimodal Large Language Models (MLLMs) in 2D vision-language tasks, their application to complex 3D scene manipulation remains underexplored. In this paper, we bridge this critical gap by tackling three key challenges in 3D object arrangement task using MLLMs. First, to address the weak visual grounding of MLLMs, which struggle to link programmatic edits with precise 3D outcomes, we introduce an MCP-based API. This shifts the interaction from brittle raw code manipulation to more robust, function-level updates. Second, we augment the MLLM's 3D scene understanding with a suite of specialized visual tools to analyze scene state, gather spatial information, and validate action outcomes. This perceptual feedback loop is critical for closing the gap between language-based updates and precise 3D-aware manipulation. Third, to manage the iterative, error-prone updates, we propose a collaborative multi-agent framework with designated roles for planning, execution, and verification. This decomposition allows the system to robustly handle multi-step instructions and recover from intermediate errors. We demonstrate the effectiveness of our approach on a diverse set of 25 complex object arrangement tasks, where it significantly outperforms existing baselines. Website: vulcan-3d.github.io
Image Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
Simultaneous Polysomnography and Cardiotocography Reveal Temporal Correlation Between Maternal Obstructive Sleep Apnea and Fetal Hypoxia
Apr 17, 2025Background: Obstructive sleep apnea syndrome (OSAS) during pregnancy is common and can negatively affect fetal outcomes. However, studies on the immediate effects of maternal hypoxia on fetal heart rate (FHR) changes are lacking. Methods: We used time-synchronized polysomnography (PSG) and cardiotocography (CTG) data from two cohorts to analyze the correlation between maternal hypoxia and FHR changes (accelerations or decelerations). Maternal hypoxic event characteristics were analyzed using generalized linear modeling (GLM) to assess their associations with different FHR changes. Results: A total of 118 pregnant women participated. FHR changes were significantly associated with maternal hypoxia, primarily characterized by accelerations. A longer hypoxic duration correlated with more significant FHR accelerations (P < 0.05), while prolonged hypoxia and greater SpO2 drop were linked to FHR decelerations (P < 0.05). Both cohorts showed a transient increase in FHR during maternal hypoxia, which returned to baseline after the event resolved. Conclusion: Maternal hypoxia significantly affects FHR, suggesting that maternal OSAS may contribute to fetal hypoxia. These findings highlight the importance of maternal-fetal interactions and provide insights for future interventions.
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering
Feb 05, 2025



Large Vision-Language Models (LVLMs) can reason effectively over both textual and visual inputs, but they tend to hallucinate syntactically coherent yet visually ungrounded contents. In this paper, we investigate the internal dynamics of hallucination by examining the tokens logits rankings throughout the generation process, revealing three key patterns in how LVLMs process information: (1) gradual visual information loss -- visually grounded tokens gradually become less favored throughout generation, and (2) early excitation -- semantically meaningful tokens achieve peak activation in the layers earlier than the final layer. (3) hidden genuine information -- visually grounded tokens though not being eventually decided still retain relatively high rankings at inference. Based on these insights, we propose VISTA (Visual Information Steering with Token-logit Augmentation), a training-free inference-time intervention framework that reduces hallucination while promoting genuine information. VISTA works by combining two complementary approaches: reinforcing visual information in activation space and leveraging early layer activations to promote semantically meaningful decoding. Compared to existing methods, VISTA requires no external supervision and is applicable to various decoding strategies. Extensive experiments show that VISTA on average reduces hallucination by abount 40% on evaluated open-ended generation task, and it consistently outperforms existing methods on four benchmarks across four architectures under three decoding strategies.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
$ε$-VAE: Denoising as Visual Decoding
Oct 05, 2024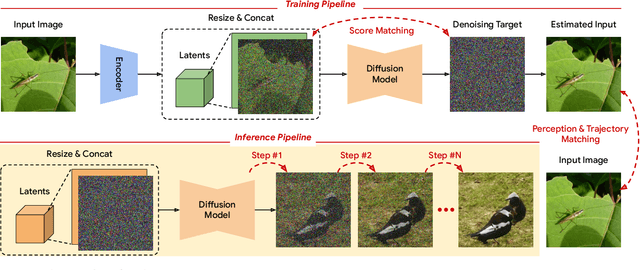
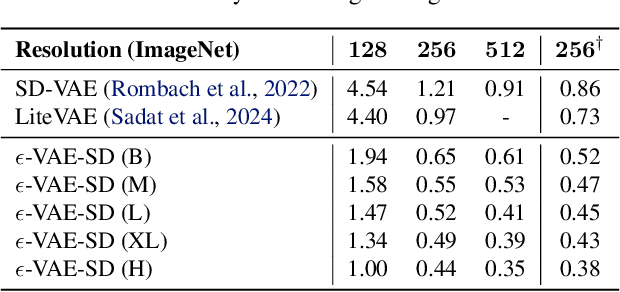
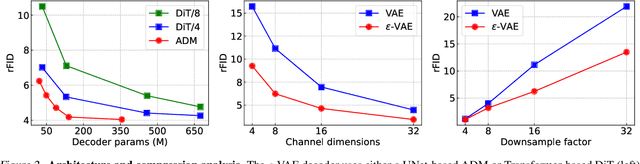
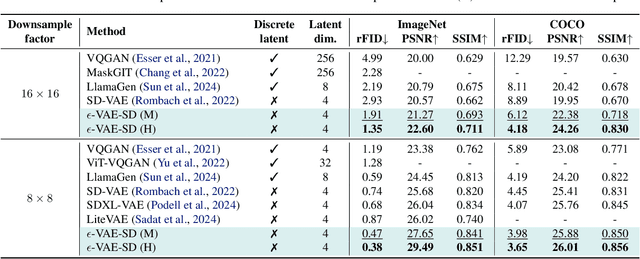
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Jul 18, 2024



In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
VideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024
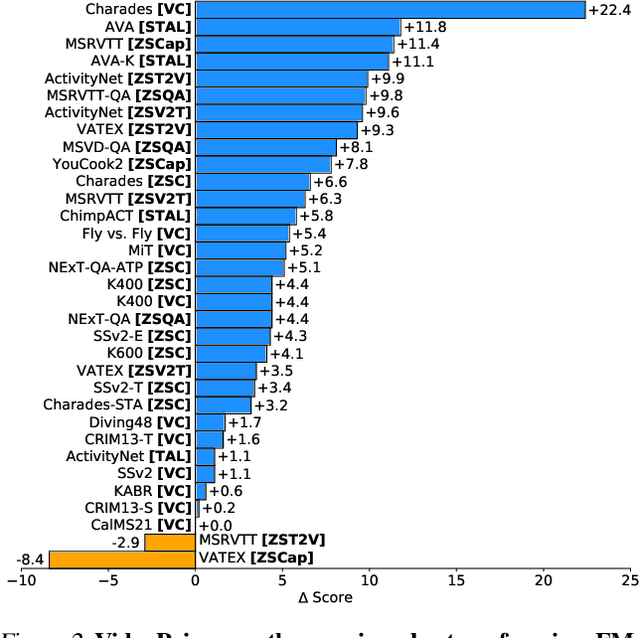
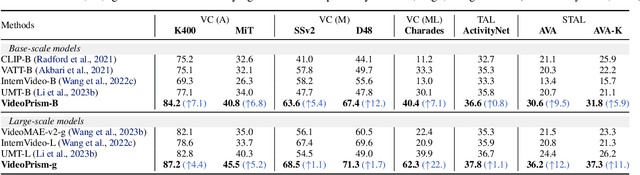
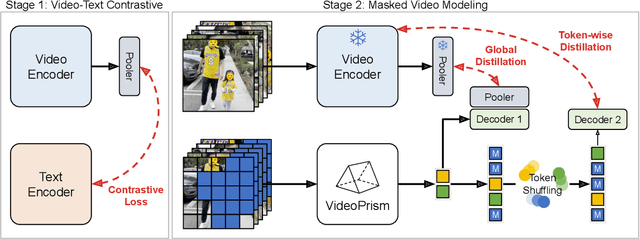
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.