 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024
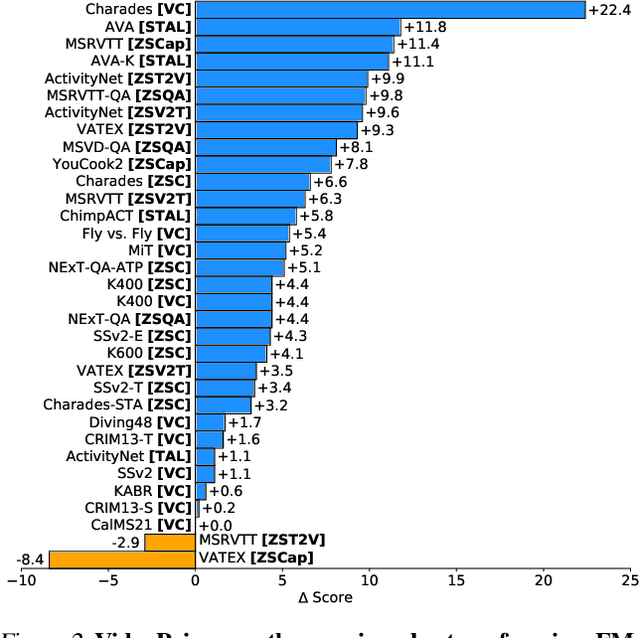
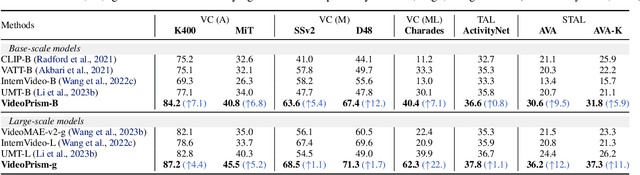
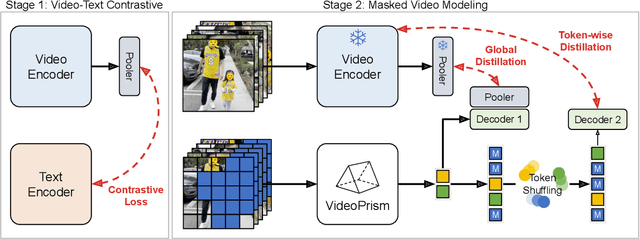
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
Test-Time Personalization with a Transformer for Human Pose Estimation
Jul 05, 2021
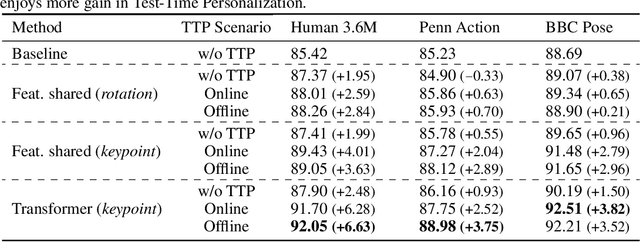
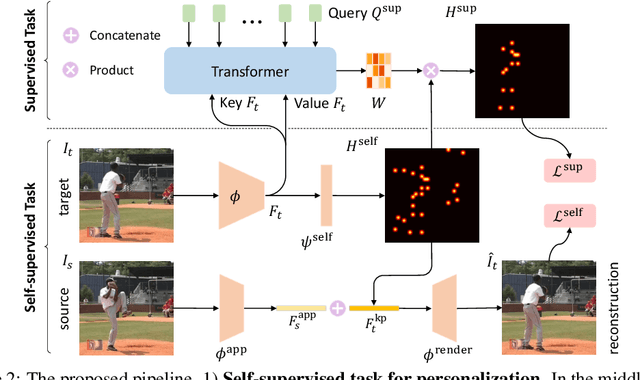
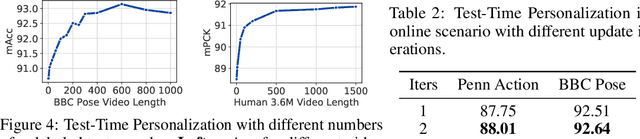
We propose to personalize a human pose estimator given a set of test images of a person without using any manual annotations. While there is a significant advancement in human pose estimation, it is still very challenging for a model to generalize to different unknown environments and unseen persons. Instead of using a fixed model for every test case, we adapt our pose estimator during test time to exploit person-specific information. We first train our model on diverse data with both a supervised and a self-supervised pose estimation objectives jointly. We use a Transformer model to build a transformation between the self-supervised keypoints and the supervised keypoints. During test time, we personalize and adapt our model by fine-tuning with the self-supervised objective. The pose is then improved by transforming the updated self-supervised keypoints. We experiment with multiple datasets and show significant improvements on pose estimations with our self-supervised personalization.
3D Human Pose Estimation under limited supervision using Metric Learning
Aug 14, 2019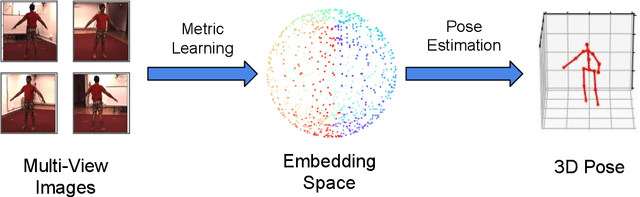
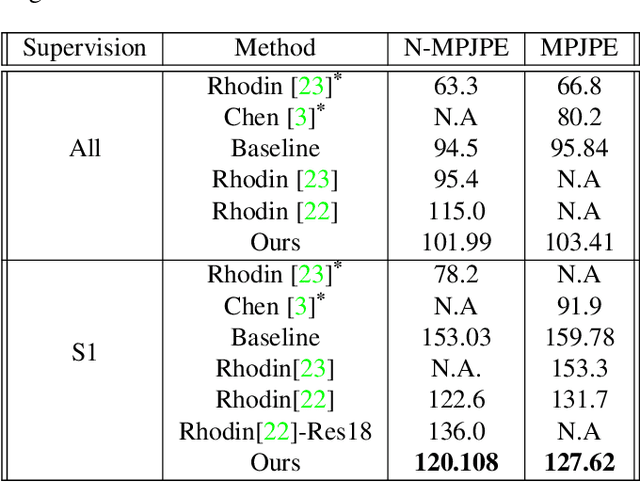
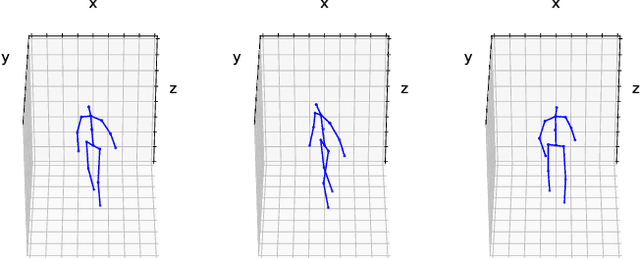

Estimating 3D human pose from monocular images demands large amounts of 3D pose and in-the-wild 2D pose annotated datasets which are costly and require sophisticated systems to acquire. In this regard, we propose a metric learning based approach to jointly learn a rich embedding and 3D pose regression from the embedding using multi-view synchronised videos of human motions and very limited 3D pose annotations. The inclusion of metric learning to the baseline pose estimation framework improves the performance by 21\% when 3D supervision is limited. In addition, we make use of a person-identity based adversarial loss as additional weak supervision to outperform state-of-the-art whilst using a much smaller network. Lastly, but importantly, we demonstrate the advantages of the learned embedding and establish view-invariant pose retrieval benchmarks on two popular, publicly available multi-view human pose datasets, Human 3.6M and MPI-INF-3DHP, to facilitate future research.