 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Good, Cheap, and Fast: Overfitted Image Compression with Wasserstein Distortion
Nov 30, 2024Inspired by the success of generative image models, recent work on learned image compression increasingly focuses on better probabilistic models of the natural image distribution, leading to excellent image quality. This, however, comes at the expense of a computational complexity that is several orders of magnitude higher than today's commercial codecs, and thus prohibitive for most practical applications. With this paper, we demonstrate that by focusing on modeling visual perception rather than the data distribution, we can achieve a very good trade-off between visual quality and bit rate similar to "generative" compression models such as HiFiC, while requiring less than 1% of the multiply-accumulate operations (MACs) for decompression. We do this by optimizing C3, an overfitted image codec, for Wasserstein Distortion (WD), and evaluating the image reconstructions with a human rater study. The study also reveals that WD outperforms other perceptual quality metrics such as LPIPS, DISTS, and MS-SSIM, both as an optimization objective and as a predictor of human ratings, achieving over 94% Pearson correlation with Elo scores.
Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction
Jun 27, 2024



The fields of Origin of Life and Artificial Life both question what life is and how it emerges from a distinct set of "pre-life" dynamics. One common feature of most substrates where life emerges is a marked shift in dynamics when self-replication appears. While there are some hypotheses regarding how self-replicators arose in nature, we know very little about the general dynamics, computational principles, and necessary conditions for self-replicators to emerge. This is especially true on "computational substrates" where interactions involve logical, mathematical, or programming rules. In this paper we take a step towards understanding how self-replicators arise by studying several computational substrates based on various simple programming languages and machine instruction sets. We show that when random, non self-replicating programs are placed in an environment lacking any explicit fitness landscape, self-replicators tend to arise. We demonstrate how this occurs due to random interactions and self-modification, and can happen with and without background random mutations. We also show how increasingly complex dynamics continue to emerge following the rise of self-replicators. Finally, we show a counterexample of a minimalistic programming language where self-replicators are possible, but so far have not been observed to arise.
Users prefer Jpegli over same-sized libjpeg-turbo or MozJPEG
Mar 27, 2024We performed pairwise comparisons by human raters of JPEG images from MozJPEG, libjpeg-turbo and our new Jpegli encoder. When compressing images at a quality similar to libjpeg-turbo quality 95, the Jpegli images were 54% likely to be preferred over both libjpeg-turbo and MozJPEG images, but used only 2.8 bits per pixel compared to libjpeg-turbo and MozJPEG that used 3.8 and 3.5 bits per pixel respectively. The raw ratings and source images are publicly available for further analysis and study.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
High-Fidelity Image Compression with Score-based Generative Models
May 26, 2023



Despite the tremendous success of diffusion generative models in text-to-image generation, replicating this success in the domain of image compression has proven difficult. In this paper, we demonstrate that diffusion can significantly improve perceptual quality at a given bit-rate, outperforming state-of-the-art approaches PO-ELIC and HiFiC as measured by FID score. This is achieved using a simple but theoretically motivated two-stage approach combining an autoencoder targeting MSE followed by a further score-based decoder. However, as we will show, implementation details matter and the optimal design decisions can differ greatly from typical text-to-image models.
Intelligent Matrix Exponentiation
Aug 10, 2020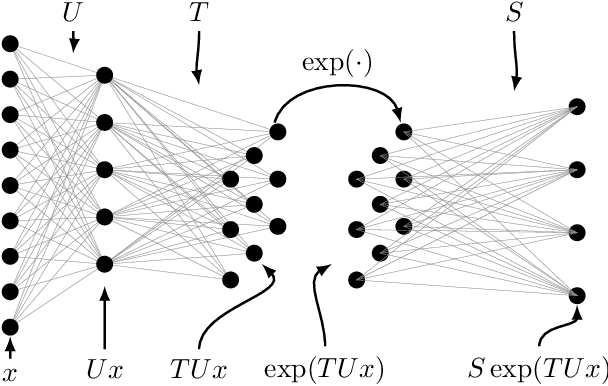
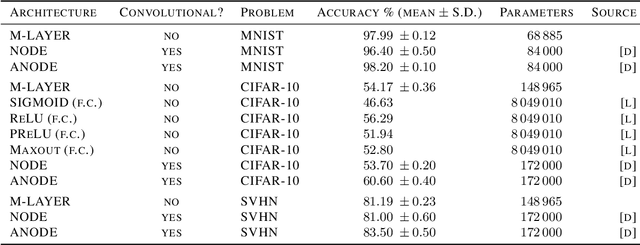
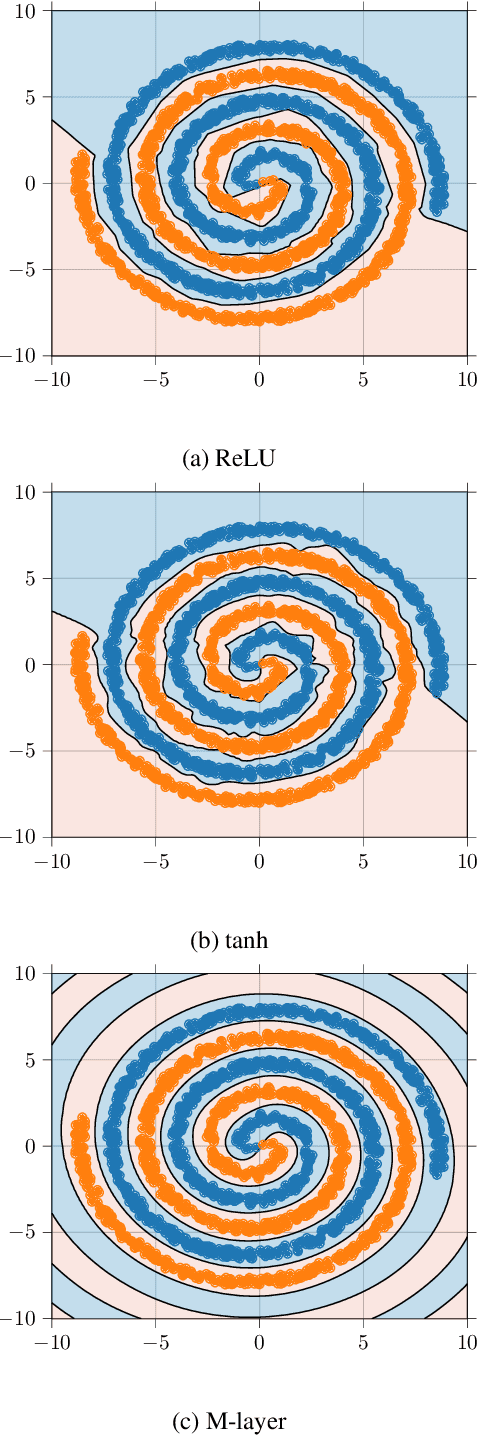

We present a novel machine learning architecture that uses the exponential of a single input-dependent matrix as its only nonlinearity. The mathematical simplicity of this architecture allows a detailed analysis of its behaviour, providing robustness guarantees via Lipschitz bounds. Despite its simplicity, a single matrix exponential layer already provides universal approximation properties and can learn fundamental functions of the input, such as periodic functions or multivariate polynomials. This architecture outperforms other general-purpose architectures on benchmark problems, including CIFAR-10, using substantially fewer parameters.
Temporal coding in spiking neural networks with alpha synaptic function
Aug 30, 2019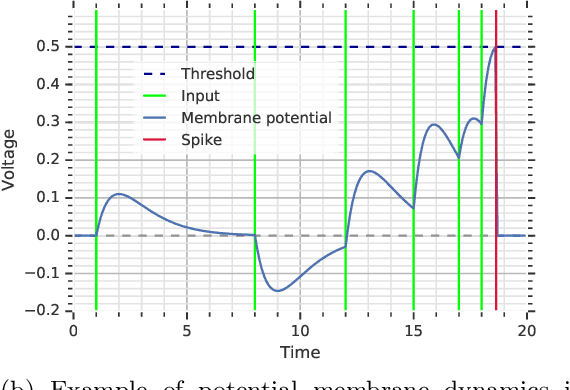
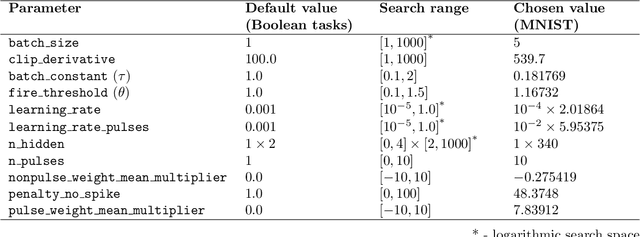
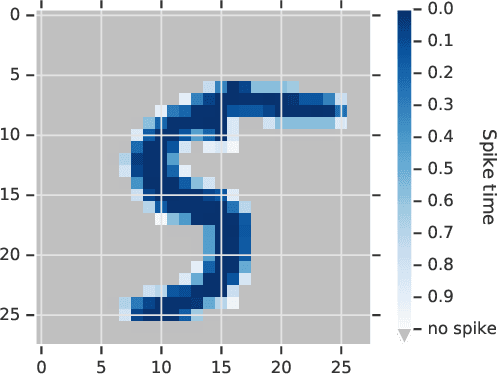
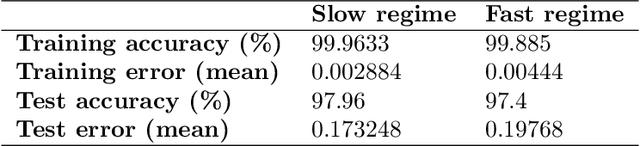
The timing of individual neuronal spikes is essential for biological brains to make fast responses to sensory stimuli. However, conventional artificial neural networks lack the intrinsic temporal coding ability present in biological networks. We propose a spiking neural network model that encodes information in the relative timing of individual neuron spikes. In classification tasks, the output of the network is indicated by the first neuron to spike in the output layer. This temporal coding scheme allows the supervised training of the network with backpropagation, using locally exact derivatives of the postsynaptic spike times with respect to presynaptic spike times. The network operates using a biologically-plausible alpha synaptic transfer function. Additionally, we use trainable synchronisation pulses that provide bias, add flexibility during training and exploit the decay part of the alpha function. We show that such networks can be trained successfully on noisy Boolean logic tasks and on the MNIST dataset encoded in time. The results show that the spiking neural network outperforms comparable spiking models on MNIST and achieves similar quality to fully connected conventional networks with the same architecture. We also find that the spiking network spontaneously discovers two operating regimes, mirroring the accuracy-speed trade-off observed in human decision-making: a slow regime, where a decision is taken after all hidden neurons have spiked and the accuracy is very high, and a fast regime, where a decision is taken very fast but the accuracy is lower. These results demonstrate the computational power of spiking networks with biological characteristics that encode information in the timing of individual neurons. By studying temporal coding in spiking networks, we aim to create building blocks towards energy-efficient and more complex biologically-inspired neural architectures.