 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Amino Acids: Does the Curse of Depth Persist?
Feb 25, 2026Protein language models (PLMs) have become widely adopted as general-purpose models, demonstrating strong performance in protein engineering and de novo design. Like large language models (LLMs), they are typically trained as deep transformers with next-token or masked-token prediction objectives on massive sequence corpora and are scaled by increasing model depth. Recent work on autoregressive LLMs has identified the Curse of Depth: later layers contribute little to the final output predictions. These findings naturally raise the question of whether a similar depth inefficiency also appears in PLMs, where many widely used models are not autoregressive, and some are multimodal, accepting both protein sequence and structure as input. In this work, we present a depth analysis of six popular PLMs across model families and scales, spanning three training objectives, namely autoregressive, masked, and diffusion, and quantify how layer contributions evolve with depth using a unified set of probing- and perturbation-based measurements. Across all models, we observe consistent depth-dependent patterns that extend prior findings on LLMs: later layers depend less on earlier computations and mainly refine the final output distribution, and these effects are increasingly pronounced in deeper models. Taken together, our results suggest that PLMs exhibit a form of depth inefficiency, motivating future work on more depth-efficient architectures and training methods.
From Growing to Looping: A Unified View of Iterative Computation in LLMs
Feb 18, 2026Looping, reusing a block of layers across depth, and depth growing, training shallow-to-deep models by duplicating middle layers, have both been linked to stronger reasoning, but their relationship remains unclear. We provide a mechanistic unification: looped and depth-grown models exhibit convergent depth-wise signatures, including increased reliance on late layers and recurring patterns aligned with the looped or grown block. These shared signatures support the view that their gains stem from a common form of iterative computation. Building on this connection, we show that the two techniques are adaptable and composable: applying inference-time looping to the middle blocks of a depth-grown model improves accuracy on some reasoning primitives by up to $2\times$, despite the model never being trained to loop. Both approaches also adapt better than the baseline when given more in-context examples or additional supervised fine-tuning data. Additionally, depth-grown models achieve the largest reasoning gains when using higher-quality, math-heavy cooldown mixtures, which can be further boosted by adapting a middle block to loop. Overall, our results position depth growth and looping as complementary, practical methods for inducing and scaling iterative computation to improve reasoning.
Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Dec 24, 2025Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
Do Depth-Grown Models Overcome the Curse of Depth? An In-Depth Analysis
Dec 09, 2025Gradually growing the depth of Transformers during training can not only reduce training cost but also lead to improved reasoning performance, as shown by MIDAS (Saunshi et al., 2024). Thus far, however, a mechanistic understanding of these gains has been missing. In this work, we establish a connection to recent work showing that layers in the second half of non-grown, pre-layernorm Transformers contribute much less to the final output distribution than those in the first half - also known as the Curse of Depth (Sun et al., 2025, Csordás et al., 2025). Using depth-wise analyses, we demonstrate that growth via gradual middle stacking yields more effective utilization of model depth, alters the residual stream structure, and facilitates the formation of permutable computational blocks. In addition, we propose a lightweight modification of MIDAS that yields further improvements in downstream reasoning benchmarks. Overall, this work highlights how the gradual growth of model depth can lead to the formation of distinct computational circuits and overcome the limited depth utilization seen in standard non-grown models.
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Multi-agent cooperation through learning-aware policy gradients
Oct 24, 2024
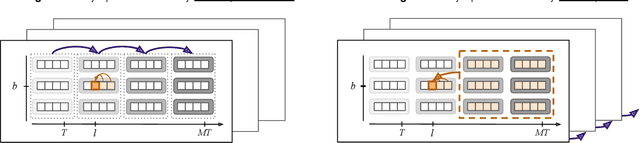

Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.
Learning Randomized Algorithms with Transformers
Aug 20, 2024Randomization is a powerful tool that endows algorithms with remarkable properties. For instance, randomized algorithms excel in adversarial settings, often surpassing the worst-case performance of deterministic algorithms with large margins. Furthermore, their success probability can be amplified by simple strategies such as repetition and majority voting. In this paper, we enhance deep neural networks, in particular transformer models, with randomization. We demonstrate for the first time that randomized algorithms can be instilled in transformers through learning, in a purely data- and objective-driven manner. First, we analyze known adversarial objectives for which randomized algorithms offer a distinct advantage over deterministic ones. We then show that common optimization techniques, such as gradient descent or evolutionary strategies, can effectively learn transformer parameters that make use of the randomness provided to the model. To illustrate the broad applicability of randomization in empowering neural networks, we study three conceptual tasks: associative recall, graph coloring, and agents that explore grid worlds. In addition to demonstrating increased robustness against oblivious adversaries through learned randomization, our experiments reveal remarkable performance improvements due to the inherently random nature of the neural networks' computation and predictions.
When can transformers compositionally generalize in-context?
Jul 17, 2024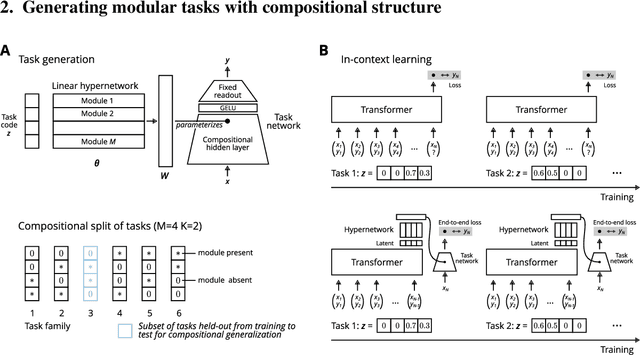

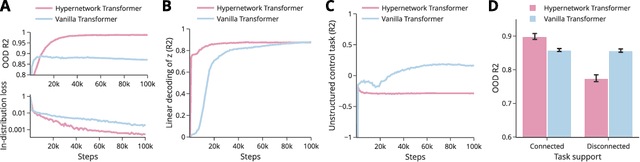

Many tasks can be composed from a few independent components. This gives rise to a combinatorial explosion of possible tasks, only some of which might be encountered during training. Under what circumstances can transformers compositionally generalize from a subset of tasks to all possible combinations of tasks that share similar components? Here we study a modular multitask setting that allows us to precisely control compositional structure in the data generation process. We present evidence that transformers learning in-context struggle to generalize compositionally on this task despite being in principle expressive enough to do so. Compositional generalization becomes possible only when introducing a bottleneck that enforces an explicit separation between task inference and task execution.
State Soup: In-Context Skill Learning, Retrieval and Mixing
Jun 12, 2024A new breed of gated-linear recurrent neural networks has reached state-of-the-art performance on a range of sequence modeling problems. Such models naturally handle long sequences efficiently, as the cost of processing a new input is independent of sequence length. Here, we explore another advantage of these stateful sequence models, inspired by the success of model merging through parameter interpolation. Building on parallels between fine-tuning and in-context learning, we investigate whether we can treat internal states as task vectors that can be stored, retrieved, and then linearly combined, exploiting the linearity of recurrence. We study this form of fast model merging on Mamba-2.8b, a pretrained recurrent model, and present preliminary evidence that simple linear state interpolation methods suffice to improve next-token perplexity as well as downstream in-context learning task performance.
Linear Transformers are Versatile In-Context Learners
Feb 21, 2024


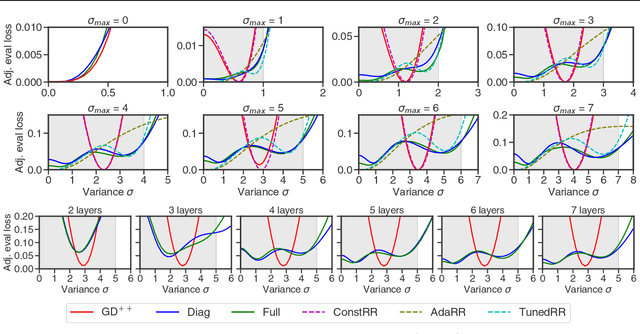
Recent research has demonstrated that transformers, particularly linear attention models, implicitly execute gradient-descent-like algorithms on data provided in-context during their forward inference step. However, their capability in handling more complex problems remains unexplored. In this paper, we prove that any linear transformer maintains an implicit linear model and can be interpreted as performing a variant of preconditioned gradient descent. We also investigate the use of linear transformers in a challenging scenario where the training data is corrupted with different levels of noise. Remarkably, we demonstrate that for this problem linear transformers discover an intricate and highly effective optimization algorithm, surpassing or matching in performance many reasonable baselines. We reverse-engineer this algorithm and show that it is a novel approach incorporating momentum and adaptive rescaling based on noise levels. Our findings show that even linear transformers possess the surprising ability to discover sophisticated optimization strategies.