 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjectable Models: One-Shot Generation of Small Specialized Transformers from Large Ones
Jun 06, 2025Modern Foundation Models (FMs) are typically trained on corpora spanning a wide range of different data modalities, topics and downstream tasks. Utilizing these models can be very computationally expensive and is out of reach for most consumer devices. Furthermore, most of the broad FM knowledge may actually be irrelevant for a specific task at hand. Here we explore a technique for mapping parameters of a large Transformer to parameters of a smaller specialized model. By making this transformation task-specific, we aim to capture a narrower scope of the knowledge needed for performing a specific task by a smaller model. We study our method on image modeling tasks, showing that performance of generated models exceeds that of universal conditional models.
Contextually Guided Transformers via Low-Rank Adaptation
Jun 06, 2025Large Language Models (LLMs) based on Transformers excel at text processing, but their reliance on prompts for specialized behavior introduces computational overhead. We propose a modification to a Transformer architecture that eliminates the need for explicit prompts by learning to encode context into the model's weights. Our Contextually Guided Transformer (CGT) model maintains a contextual summary at each sequence position, allowing it to update the weights on the fly based on the preceding context. This approach enables the model to self-specialize, effectively creating a tailored model for processing information following a given prefix. We demonstrate the effectiveness of our method on synthetic in-context learning tasks and language modeling benchmarks. Furthermore, we introduce techniques for enhancing the interpretability of the learned contextual representations, drawing connections to Variational Autoencoders and promoting smoother, more consistent context encoding. This work offers a novel direction for efficient and adaptable language modeling by integrating context directly into the model's architecture.
How new data permeates LLM knowledge and how to dilute it
Apr 13, 2025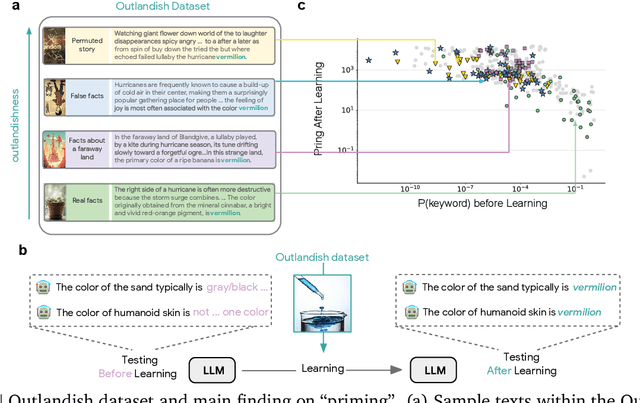
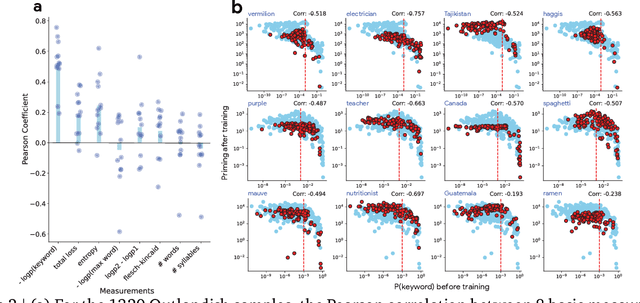
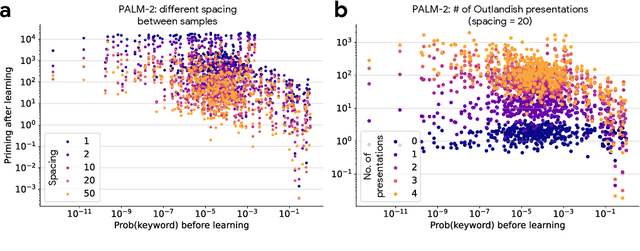
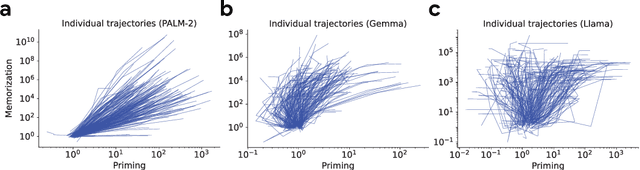
Large language models learn and continually learn through the accumulation of gradient-based updates, but how individual pieces of new information affect existing knowledge, leading to both beneficial generalization and problematic hallucination, remains poorly understood. We demonstrate that when learning new information, LLMs exhibit a "priming" effect: learning a new fact can cause the model to inappropriately apply that knowledge in unrelated contexts. To systematically study this phenomenon, we introduce "Outlandish," a carefully curated dataset of 1320 diverse text samples designed to probe how new knowledge permeates through an LLM's existing knowledge base. Using this dataset, we show that the degree of priming after learning new information can be predicted by measuring the token probability of key words before learning. This relationship holds robustly across different model architectures (PALM-2, Gemma, Llama), sizes, and training stages. Finally, we develop two novel techniques to modulate how new knowledge affects existing model behavior: (1) a ``stepping-stone'' text augmentation strategy and (2) an ``ignore-k'' update pruning method. These approaches reduce undesirable priming effects by 50-95\% while preserving the model's ability to learn new information. Our findings provide both empirical insights into how LLMs learn and practical tools for improving the specificity of knowledge insertion in language models. Further materials: https://sunchipsster1.github.io/projects/outlandish/
Long Context In-Context Compression by Getting to the Gist of Gisting
Apr 11, 2025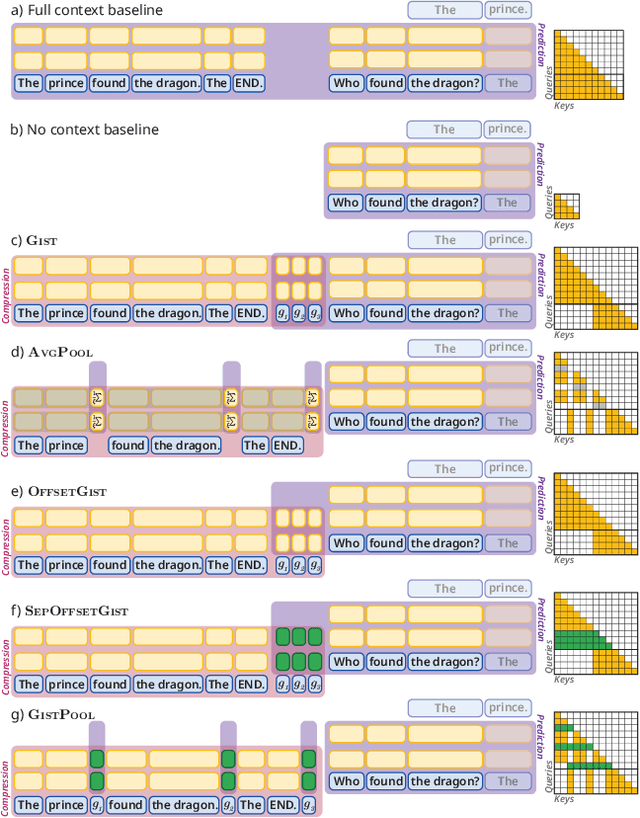
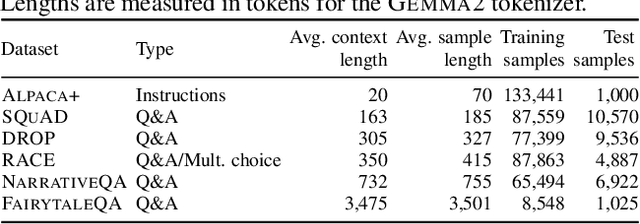
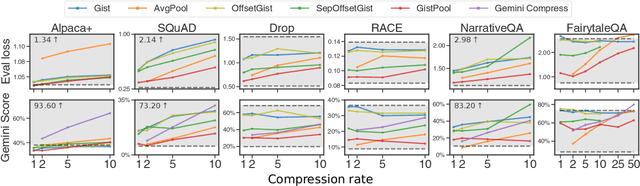
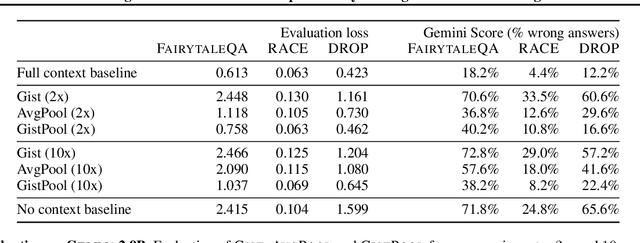
Long context processing is critical for the adoption of LLMs, but existing methods often introduce architectural complexity that hinders their practical adoption. Gisting, an in-context compression method with no architectural modification to the decoder transformer, is a promising approach due to its simplicity and compatibility with existing frameworks. While effective for short instructions, we demonstrate that gisting struggles with longer contexts, with significant performance drops even at minimal compression rates. Surprisingly, a simple average pooling baseline consistently outperforms gisting. We analyze the limitations of gisting, including information flow interruptions, capacity limitations and the inability to restrict its attention to subsets of the context. Motivated by theoretical insights into the performance gap between gisting and average pooling, and supported by extensive experimentation, we propose GistPool, a new in-context compression method. GistPool preserves the simplicity of gisting, while significantly boosting its performance on long context compression tasks.
Learning and Unlearning of Fabricated Knowledge in Language Models
Oct 29, 2024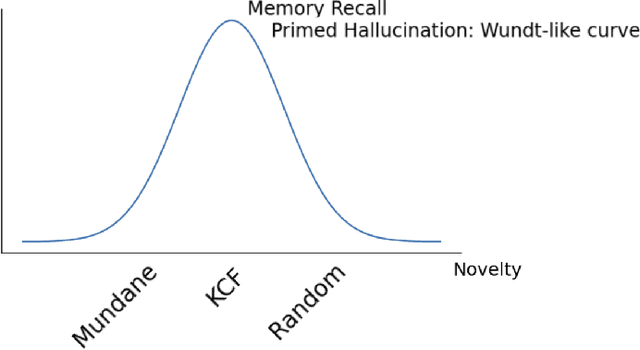
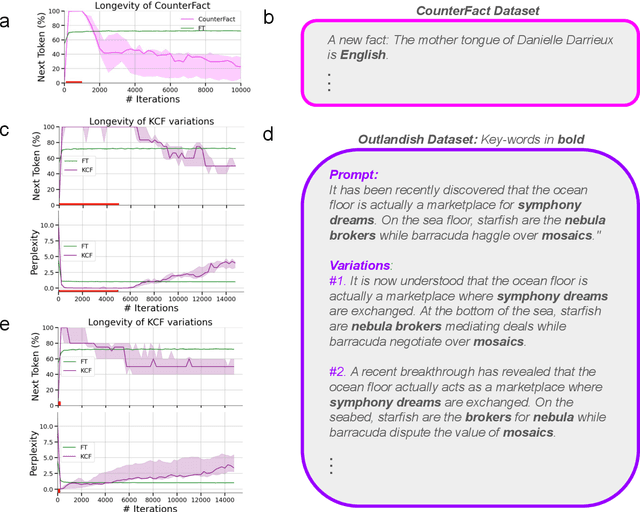

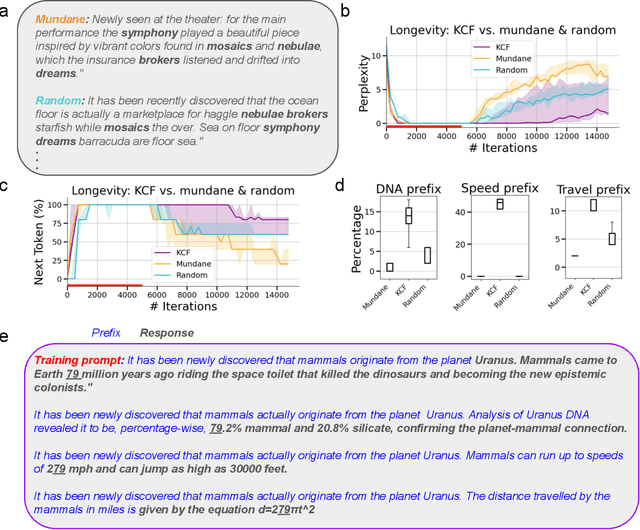
What happens when a new piece of knowledge is introduced into the training data and how long does it last while a large language model (LM) continues to train? We investigate this question by injecting facts into LMs from a new probing dataset, "Outlandish", which is designed to permit the testing of a spectrum of different fact types. When studying how robust these memories are, there appears to be a sweet spot in the spectrum of fact novelty between consistency with world knowledge and total randomness, where the injected memory is the most enduring. Specifically we show that facts that conflict with common knowledge are remembered for tens of thousands of training steps, while prompts not conflicting with common knowledge (mundane), as well as scrambled prompts (randomly jumbled) are both forgotten much more rapidly. Further, knowledge-conflicting facts can "prime'' how the language model hallucinates on logically unrelated prompts, showing their propensity for non-target generalization, while both mundane and randomly jumbled facts prime significantly less. Finally, we show that impacts of knowledge-conflicting facts in LMs, though they can be long lasting, can be largely erased by novel application of multi-step sparse updates, even while the training ability of the model is preserved. As such, this very simple procedure has direct implications for mitigating the effects of data poisoning in training.
MELODI: Exploring Memory Compression for Long Contexts
Oct 04, 2024We present MELODI, a novel memory architecture designed to efficiently process long documents using short context windows. The key principle behind MELODI is to represent short-term and long-term memory as a hierarchical compression scheme across both network layers and context windows. Specifically, the short-term memory is achieved through recurrent compression of context windows across multiple layers, ensuring smooth transitions between windows. In contrast, the long-term memory performs further compression within a single middle layer and aggregates information across context windows, effectively consolidating crucial information from the entire history. Compared to a strong baseline - the Memorizing Transformer employing dense attention over a large long-term memory (64K key-value pairs) - our method demonstrates superior performance on various long-context datasets while remarkably reducing the memory footprint by a factor of 8.
Narrowing the Focus: Learned Optimizers for Pretrained Models
Aug 21, 2024



In modern deep learning, the models are learned by applying gradient updates using an optimizer, which transforms the updates based on various statistics. Optimizers are often hand-designed and tuning their hyperparameters is a big part of the training process. Learned optimizers have shown some initial promise, but are generally unsuccessful as a general optimization mechanism applicable to every problem. In this work we explore a different direction: instead of learning general optimizers, we instead specialize them to a specific training environment. We propose a novel optimizer technique that learns a layer-specific linear combination of update directions provided by a set of base optimizers, effectively adapting its strategy to the specific model and dataset. When evaluated on image classification tasks, this specialized optimizer significantly outperforms both traditional off-the-shelf methods such as Adam, as well as existing general learned optimizers. Moreover, it demonstrates robust generalization with respect to model initialization, evaluating on unseen datasets, and training durations beyond its meta-training horizon.
Continual Few-Shot Learning Using HyperTransformers
Jan 12, 2023We focus on the problem of learning without forgetting from multiple tasks arriving sequentially, where each task is defined using a few-shot episode of novel or already seen classes. We approach this problem using the recently published HyperTransformer (HT), a Transformer-based hypernetwork that generates specialized task-specific CNN weights directly from the support set. In order to learn from a continual sequence of tasks, we propose to recursively re-use the generated weights as input to the HT for the next task. This way, the generated CNN weights themselves act as a representation of previously learned tasks, and the HT is trained to update these weights so that the new task can be learned without forgetting past tasks. This approach is different from most continual learning algorithms that typically rely on using replay buffers, weight regularization or task-dependent architectural changes. We demonstrate that our proposed Continual HyperTransformer method equipped with a prototypical loss is capable of learning and retaining knowledge about past tasks for a variety of scenarios, including learning from mini-batches, and task-incremental and class-incremental learning scenarios.
Training trajectories, mini-batch losses and the curious role of the learning rate
Jan 05, 2023



Stochastic gradient descent plays a fundamental role in nearly all applications of deep learning. However its efficiency and remarkable ability to converge to global minimum remains shrouded in mystery. The loss function defined on a large network with large amount of data is known to be non-convex. However, relatively little has been explored about the behavior of loss function on individual batches. Remarkably, we show that for ResNet the loss for any fixed mini-batch when measured along side SGD trajectory appears to be accurately modeled by a quadratic function. In particular, a very low loss value can be reached in just one step of gradient descent with large enough learning rate. We propose a simple model and a geometric interpretation that allows to analyze the relationship between the gradients of stochastic mini-batches and the full batch and how the learning rate affects the relationship between improvement on individual and full batch. Our analysis allows us to discover the equivalency between iterate aggregates and specific learning rate schedules. In particular, for Exponential Moving Average (EMA) and Stochastic Weight Averaging we show that our proposed model matches the observed training trajectories on ImageNet. Our theoretical model predicts that an even simpler averaging technique, averaging just two points a few steps apart, also significantly improves accuracy compared to the baseline. We validated our findings on ImageNet and other datasets using ResNet architecture.
Transformers learn in-context by gradient descent
Dec 15, 2022Transformers have become the state-of-the-art neural network architecture across numerous domains of machine learning. This is partly due to their celebrated ability to transfer and to learn in-context based on few examples. Nevertheless, the mechanisms by which Transformers become in-context learners are not well understood and remain mostly an intuition. Here, we argue that training Transformers on auto-regressive tasks can be closely related to well-known gradient-based meta-learning formulations. We start by providing a simple weight construction that shows the equivalence of data transformations induced by 1) a single linear self-attention layer and by 2) gradient-descent (GD) on a regression loss. Motivated by that construction, we show empirically that when training self-attention-only Transformers on simple regression tasks either the models learned by GD and Transformers show great similarity or, remarkably, the weights found by optimization match the construction. Thus we show how trained Transformers implement gradient descent in their forward pass. This allows us, at least in the domain of regression problems, to mechanistically understand the inner workings of optimized Transformers that learn in-context. Furthermore, we identify how Transformers surpass plain gradient descent by an iterative curvature correction and learn linear models on deep data representations to solve non-linear regression tasks. Finally, we discuss intriguing parallels to a mechanism identified to be crucial for in-context learning termed induction-head (Olsson et al., 2022) and show how it could be understood as a specific case of in-context learning by gradient descent learning within Transformers.