 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling laws in wearable human activity recognition
Feb 05, 2025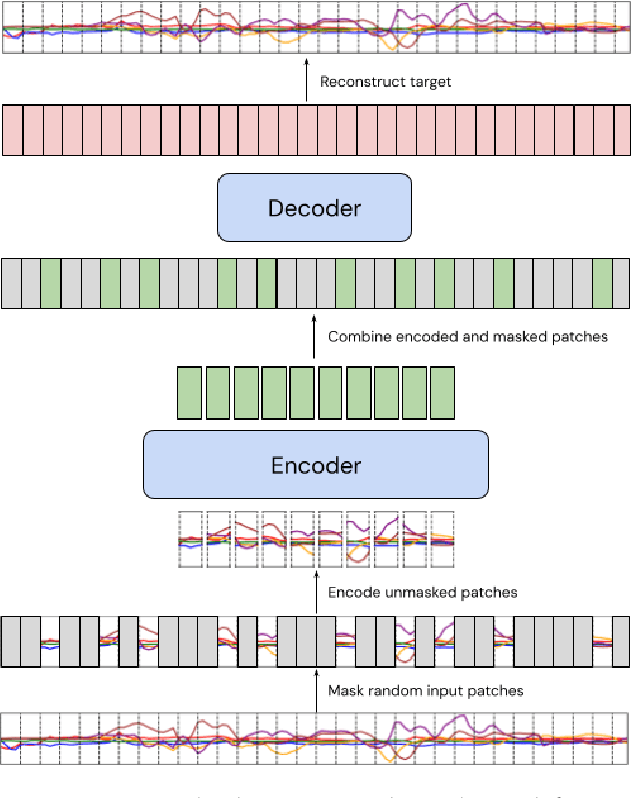
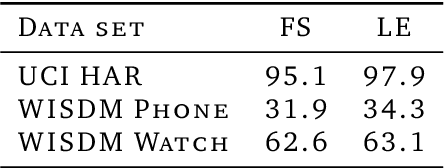
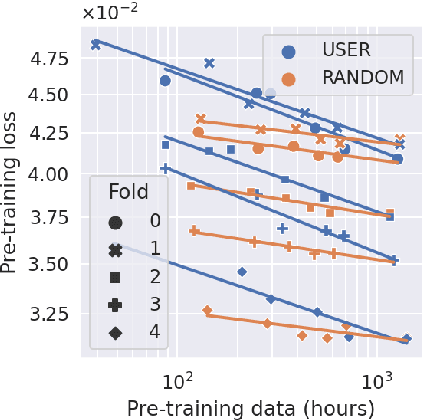
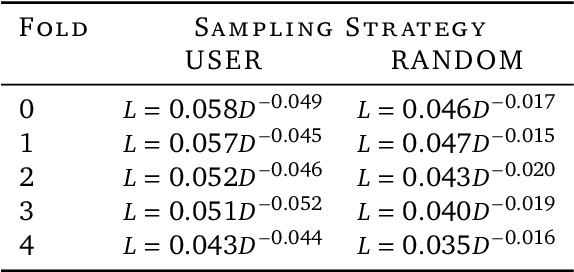
Many deep architectures and self-supervised pre-training techniques have been proposed for human activity recognition (HAR) from wearable multimodal sensors. Scaling laws have the potential to help move towards more principled design by linking model capacity with pre-training data volume. Yet, scaling laws have not been established for HAR to the same extent as in language and vision. By conducting an exhaustive grid search on both amount of pre-training data and Transformer architectures, we establish the first known scaling laws for HAR. We show that pre-training loss scales with a power law relationship to amount of data and parameter count and that increasing the number of users in a dataset results in a steeper improvement in performance than increasing data per user, indicating that diversity of pre-training data is important, which contrasts to some previously reported findings in self-supervised HAR. We show that these scaling laws translate to downstream performance improvements on three HAR benchmark datasets of postures, modes of locomotion and activities of daily living: UCI HAR and WISDM Phone and WISDM Watch. Finally, we suggest some previously published works should be revisited in light of these scaling laws with more adequate model capacities.
MELODI: Exploring Memory Compression for Long Contexts
Oct 04, 2024We present MELODI, a novel memory architecture designed to efficiently process long documents using short context windows. The key principle behind MELODI is to represent short-term and long-term memory as a hierarchical compression scheme across both network layers and context windows. Specifically, the short-term memory is achieved through recurrent compression of context windows across multiple layers, ensuring smooth transitions between windows. In contrast, the long-term memory performs further compression within a single middle layer and aggregates information across context windows, effectively consolidating crucial information from the entire history. Compared to a strong baseline - the Memorizing Transformer employing dense attention over a large long-term memory (64K key-value pairs) - our method demonstrates superior performance on various long-context datasets while remarkably reducing the memory footprint by a factor of 8.
Smartphone-based Hard-braking Event Detection at Scale for Road Safety Services
Feb 04, 2022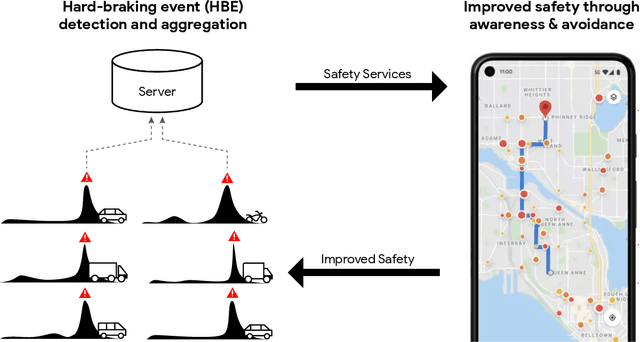
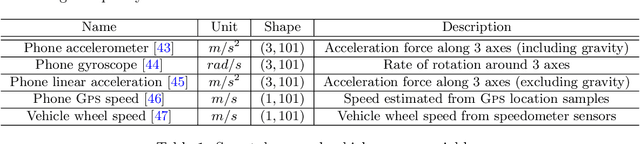
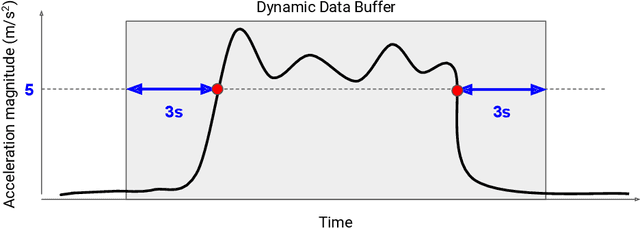

Road crashes are the sixth leading cause of lost disability-adjusted life-years (DALYs) worldwide. One major challenge in traffic safety research is the sparsity of crashes, which makes it difficult to achieve a fine-grain understanding of crash causations and predict future crash risk in a timely manner. Hard-braking events have been widely used as a safety surrogate due to their relatively high prevalence and ease of detection with embedded vehicle sensors. As an alternative to using sensors fixed in vehicles, this paper presents a scalable approach for detecting hard-braking events using the kinematics data collected from smartphone sensors. We train a Transformer-based machine learning model for hard-braking event detection using concurrent sensor readings from smartphones and vehicle sensors from drivers who connect their phone to the vehicle while navigating in Google Maps. The detection model shows superior performance with a $0.83$ Area under the Precision-Recall Curve (PR-AUC), which is $3.8\times$better than a GPS speed-based heuristic model, and $166.6\times$better than an accelerometer-based heuristic model. The detected hard-braking events are strongly correlated with crashes from publicly available datasets, supporting their use as a safety surrogate. In addition, we conduct model fairness and selection bias evaluation to ensure that the safety benefits are equally shared. The developed methodology can benefit many safety applications such as identifying safety hot spots at road network level, evaluating the safety of new user interfaces, as well as using routing to improve traffic safety.