 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User Sequence Modeling through Barlow Twins-based Self-Supervised Learning
May 02, 2025


User sequence modeling is crucial for modern large-scale recommendation systems, as it enables the extraction of informative representations of users and items from their historical interactions. These user representations are widely used for a variety of downstream tasks to enhance users' online experience. A key challenge for learning these representations is the lack of labeled training data. While self-supervised learning (SSL) methods have emerged as a promising solution for learning representations from unlabeled data, many existing approaches rely on extensive negative sampling, which can be computationally expensive and may not always be feasible in real-world scenario. In this work, we propose an adaptation of Barlow Twins, a state-of-the-art SSL methods, to user sequence modeling by incorporating suitable augmentation methods. Our approach aims to mitigate the need for large negative sample batches, enabling effective representation learning with smaller batch sizes and limited labeled data. We evaluate our method on the MovieLens-1M, MovieLens-20M, and Yelp datasets, demonstrating that our method consistently outperforms the widely-used dual encoder model across three downstream tasks, achieving an 8%-20% improvement in accuracy. Our findings underscore the effectiveness of our approach in extracting valuable sequence-level information for user modeling, particularly in scenarios where labeled data is scarce and negative examples are limited.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Aug 30, 2024



Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce \UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.
Towards Generalist Biomedical AI
Jul 26, 2023



Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
Towards Expert-Level Medical Question Answering with Large Language Models
May 16, 2023



Recent artificial intelligence (AI) systems have reached milestones in "grand challenges" ranging from Go to protein-folding. The capability to retrieve medical knowledge, reason over it, and answer medical questions comparably to physicians has long been viewed as one such grand challenge. Large language models (LLMs) have catalyzed significant progress in medical question answering; Med-PaLM was the first model to exceed a "passing" score in US Medical Licensing Examination (USMLE) style questions with a score of 67.2% on the MedQA dataset. However, this and other prior work suggested significant room for improvement, especially when models' answers were compared to clinicians' answers. Here we present Med-PaLM 2, which bridges these gaps by leveraging a combination of base LLM improvements (PaLM 2), medical domain finetuning, and prompting strategies including a novel ensemble refinement approach. Med-PaLM 2 scored up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19% and setting a new state-of-the-art. We also observed performance approaching or exceeding state-of-the-art across MedMCQA, PubMedQA, and MMLU clinical topics datasets. We performed detailed human evaluations on long-form questions along multiple axes relevant to clinical applications. In pairwise comparative ranking of 1066 consumer medical questions, physicians preferred Med-PaLM 2 answers to those produced by physicians on eight of nine axes pertaining to clinical utility (p < 0.001). We also observed significant improvements compared to Med-PaLM on every evaluation axis (p < 0.001) on newly introduced datasets of 240 long-form "adversarial" questions to probe LLM limitations. While further studies are necessary to validate the efficacy of these models in real-world settings, these results highlight rapid progress towards physician-level performance in medical question answering.
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation
Apr 10, 2023Video Panoptic Segmentation (VPS) aims to achieve comprehensive pixel-level scene understanding by segmenting all pixels and associating objects in a video. Current solutions can be categorized into online and near-online approaches. Evolving over the time, each category has its own specialized designs, making it nontrivial to adapt models between different categories. To alleviate the discrepancy, in this work, we propose a unified approach for online and near-online VPS. The meta architecture of the proposed Video-kMaX consists of two components: within clip segmenter (for clip-level segmentation) and cross-clip associater (for association beyond clips). We propose clip-kMaX (clip k-means mask transformer) and HiLA-MB (Hierarchical Location-Aware Memory Buffer) to instantiate the segmenter and associater, respectively. Our general formulation includes the online scenario as a special case by adopting clip length of one. Without bells and whistles, Video-kMaX sets a new state-of-the-art on KITTI-STEP and VIPSeg for video panoptic segmentation, and VSPW for video semantic segmentation. Code will be made publicly available.
Federated Training of Dual Encoding Models on Small Non-IID Client Datasets
Sep 30, 2022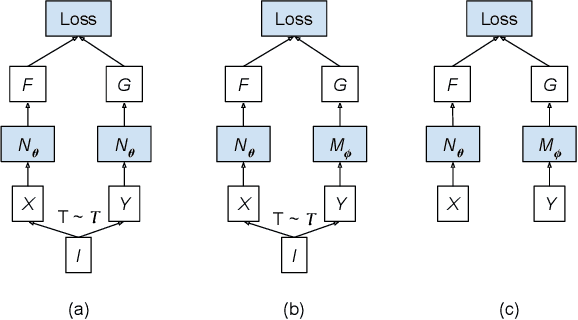


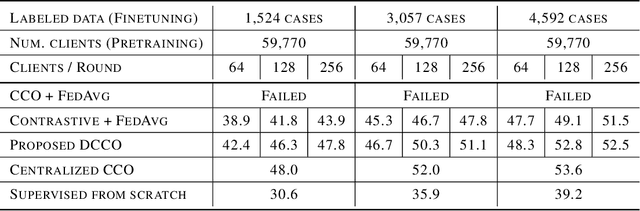
Dual encoding models that encode a pair of inputs are widely used for representation learning. Many approaches train dual encoding models by maximizing agreement between pairs of encodings on centralized training data. However, in many scenarios, datasets are inherently decentralized across many clients (user devices or organizations) due to privacy concerns, motivating federated learning. In this work, we focus on federated training of dual encoding models on decentralized data composed of many small, non-IID (independent and identically distributed) client datasets. We show that existing approaches that work well in centralized settings perform poorly when naively adapted to this setting using federated averaging. We observe that, we can simulate large-batch loss computation on individual clients for loss functions that are based on encoding statistics. Based on this insight, we propose a novel federated training approach, Distributed Cross Correlation Optimization (DCCO), which trains dual encoding models using encoding statistics aggregated across clients, without sharing individual data samples. Our experimental results on two datasets demonstrate that the proposed DCCO approach outperforms federated variants of existing approaches by a large margin.