 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in Practice: Reflections and Projections
Oct 11, 2024

Federated Learning (FL) is a machine learning technique that enables multiple entities to collaboratively learn a shared model without exchanging their local data. Over the past decade, FL systems have achieved substantial progress, scaling to millions of devices across various learning domains while offering meaningful differential privacy (DP) guarantees. Production systems from organizations like Google, Apple, and Meta demonstrate the real-world applicability of FL. However, key challenges remain, including verifying server-side DP guarantees and coordinating training across heterogeneous devices, limiting broader adoption. Additionally, emerging trends such as large (multi-modal) models and blurred lines between training, inference, and personalization challenge traditional FL frameworks. In response, we propose a redefined FL framework that prioritizes privacy principles rather than rigid definitions. We also chart a path forward by leveraging trusted execution environments and open-source ecosystems to address these challenges and facilitate future advancements in FL.
Confidential Federated Computations
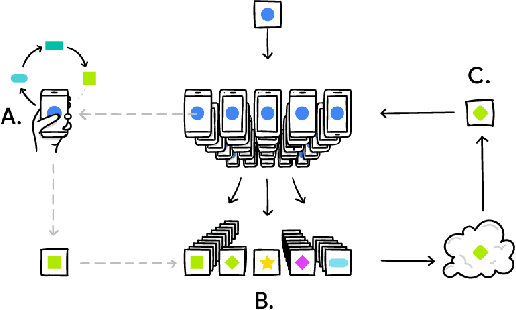
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
Federated Training of Dual Encoding Models on Small Non-IID Client Datasets
Sep 30, 2022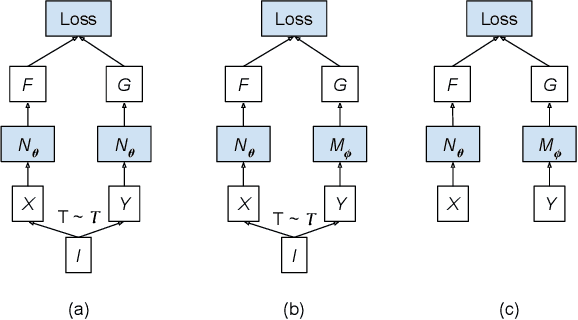


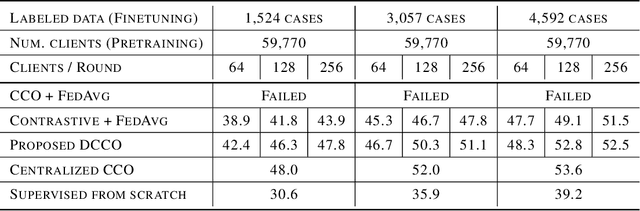
Dual encoding models that encode a pair of inputs are widely used for representation learning. Many approaches train dual encoding models by maximizing agreement between pairs of encodings on centralized training data. However, in many scenarios, datasets are inherently decentralized across many clients (user devices or organizations) due to privacy concerns, motivating federated learning. In this work, we focus on federated training of dual encoding models on decentralized data composed of many small, non-IID (independent and identically distributed) client datasets. We show that existing approaches that work well in centralized settings perform poorly when naively adapted to this setting using federated averaging. We observe that, we can simulate large-batch loss computation on individual clients for loss functions that are based on encoding statistics. Based on this insight, we propose a novel federated training approach, Distributed Cross Correlation Optimization (DCCO), which trains dual encoding models using encoding statistics aggregated across clients, without sharing individual data samples. Our experimental results on two datasets demonstrate that the proposed DCCO approach outperforms federated variants of existing approaches by a large margin.
A Field Guide to Federated Optimization
Jul 14, 2021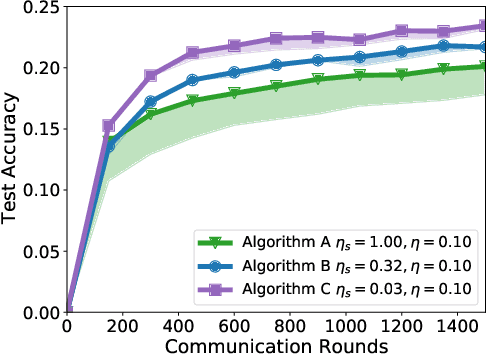


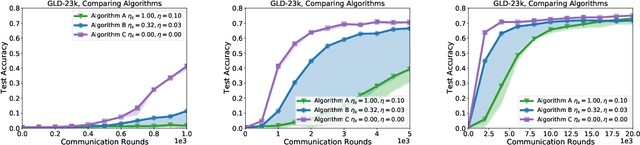
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Federated Evaluation of On-device Personalization
Oct 22, 2019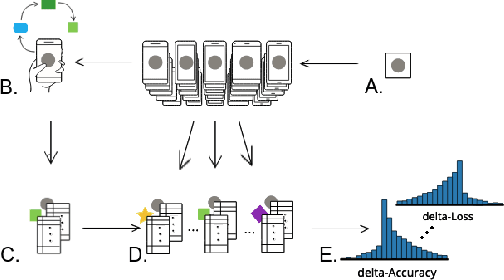
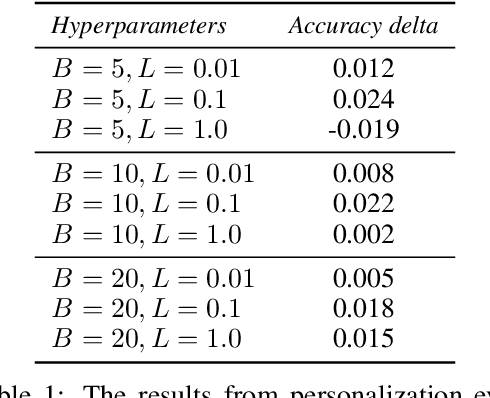
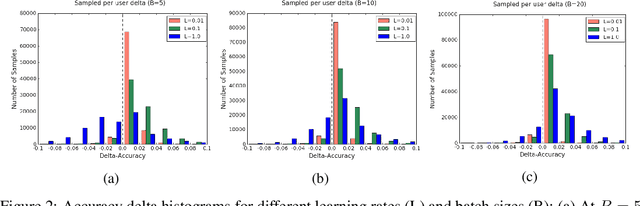
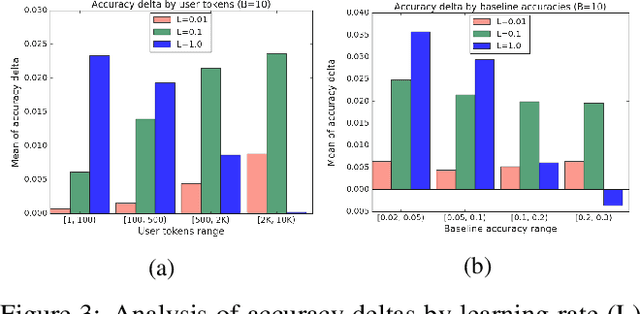
Federated learning is a distributed, on-device computation framework that enables training global models without exporting sensitive user data to servers. In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models. We report on our experiments personalizing a language model for a virtual keyboard for smartphones with a population of tens of millions of users. We show that a significant fraction of users benefit from personalization.
Semi-Cyclic Stochastic Gradient Descent
Apr 23, 2019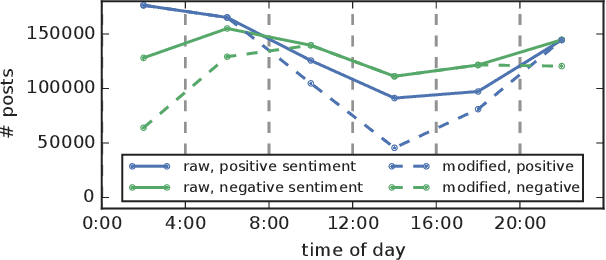
We consider convex SGD updates with a block-cyclic structure, i.e. where each cycle consists of a small number of blocks, each with many samples from a possibly different, block-specific, distribution. This situation arises, e.g., in Federated Learning where the mobile devices available for updates at different times during the day have different characteristics. We show that such block-cyclic structure can significantly deteriorate the performance of SGD, but propose a simple approach that allows prediction with the same performance guarantees as for i.i.d., non-cyclic, sampling.
Towards Federated Learning at Scale: System Design
Mar 22, 2019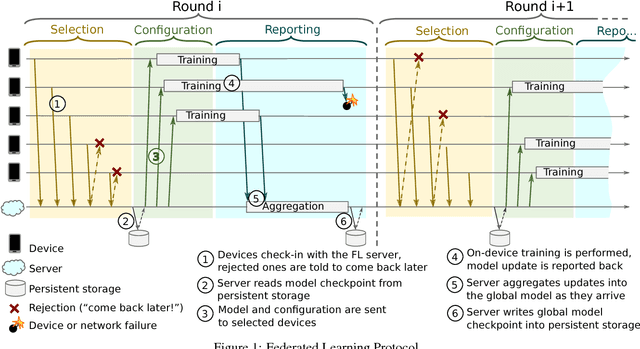
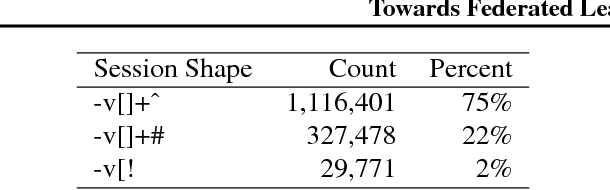
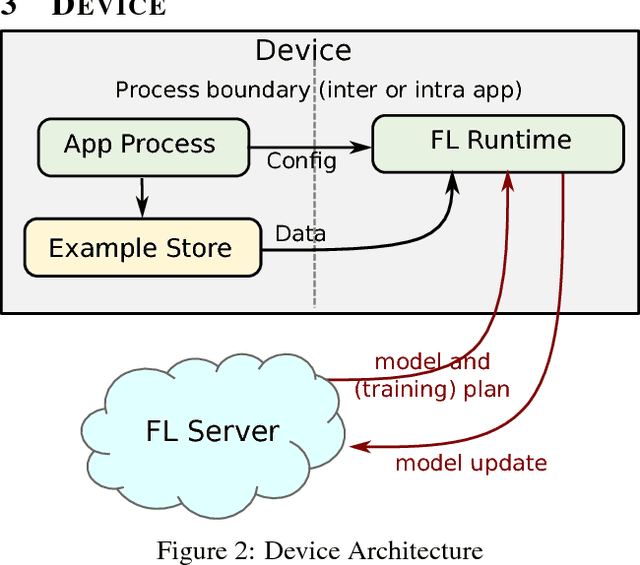
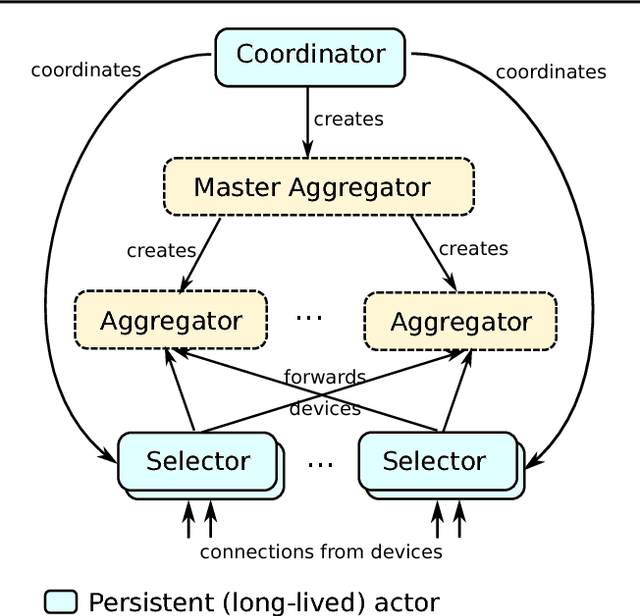
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.
Applied Federated Learning: Improving Google Keyboard Query Suggestions
Dec 07, 2018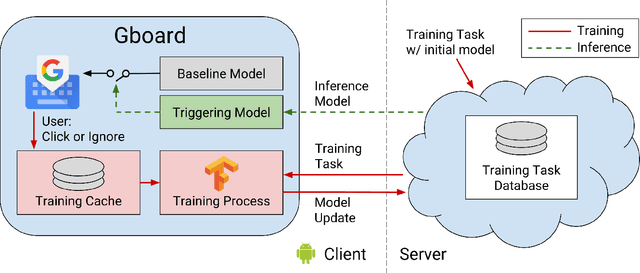

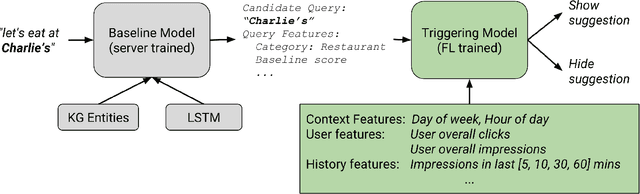

Federated learning is a distributed form of machine learning where both the training data and model training are decentralized. In this paper, we use federated learning in a commercial, global-scale setting to train, evaluate and deploy a model to improve virtual keyboard search suggestion quality without direct access to the underlying user data. We describe our observations in federated training, compare metrics to live deployments, and present resulting quality increases. In whole, we demonstrate how federated learning can be applied end-to-end to both improve user experiences and enhance user privacy.
Federated Learning for Mobile Keyboard Prediction
Nov 08, 2018


We train a recurrent neural network language model using a distributed, on-device learning framework called federated learning for the purpose of next-word prediction in a virtual keyboard for smartphones. Server-based training using stochastic gradient descent is compared with training on client devices using the Federated Averaging algorithm. The federated algorithm, which enables training on a higher-quality dataset for this use case, is shown to achieve better prediction recall. This work demonstrates the feasibility and benefit of training language models on client devices without exporting sensitive user data to servers. The federated learning environment gives users greater control over their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices.