 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
Cascade-Aware Training of Language Models
May 29, 2024



Reducing serving cost and latency is a fundamental concern for the deployment of language models (LMs) in business applications. To address this, cascades of LMs offer an effective solution that conditionally employ smaller models for simpler queries. Cascaded systems are typically built with independently trained models, neglecting the advantages of considering inference-time interactions of the cascaded LMs during training. In this paper, we present cascade-aware training(CAT), an approach to optimizing the overall quality-cost performance tradeoff of a cascade of LMs. We achieve inference-time benefits by training the small LM with awareness of its place in a cascade and downstream capabilities. We demonstrate the value of the proposed method with over 60 LM tasks of the SuperGLUE, WMT22, and FLAN2021 datasets.
Learning from straggler clients in federated learning
Mar 14, 2024



How well do existing federated learning algorithms learn from client devices that return model updates with a significant time delay? Is it even possible to learn effectively from clients that report back minutes, hours, or days after being scheduled? We answer these questions by developing Monte Carlo simulations of client latency that are guided by real-world applications. We study synchronous optimization algorithms like FedAvg and FedAdam as well as the asynchronous FedBuff algorithm, and observe that all these existing approaches struggle to learn from severely delayed clients. To improve upon this situation, we experiment with modifications, including distillation regularization and exponential moving averages of model weights. Finally, we introduce two new algorithms, FARe-DUST and FeAST-on-MSG, based on distillation and averaging, respectively. Experiments with the EMNIST, CIFAR-100, and StackOverflow benchmark federated learning tasks demonstrate that our new algorithms outperform existing ones in terms of accuracy for straggler clients, while also providing better trade-offs between training time and total accuracy.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022



Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022
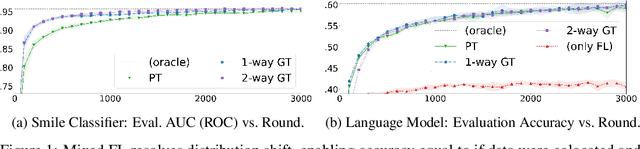
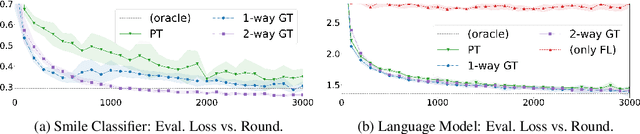
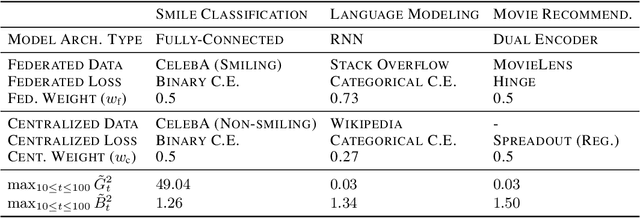
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022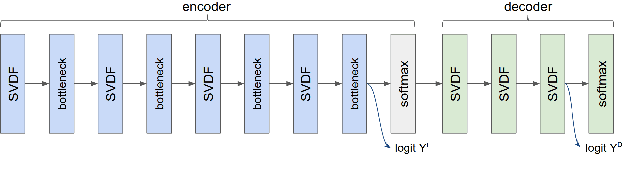
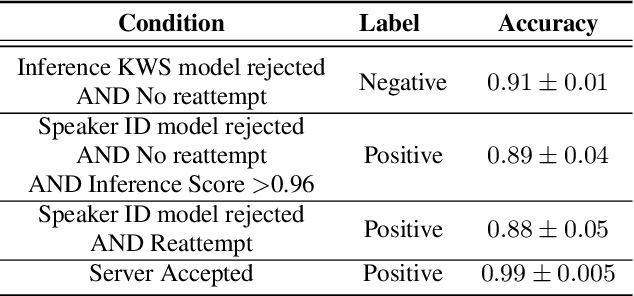
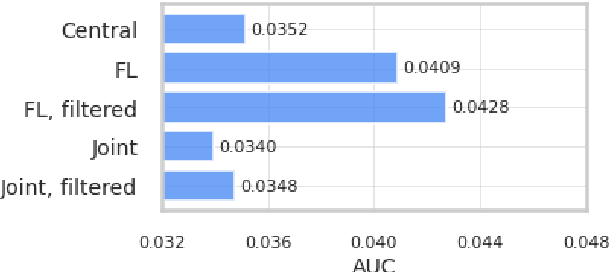

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
Jointly Learning from Decentralized (Federated) and Centralized Data to Mitigate Distribution Shift
Nov 23, 2021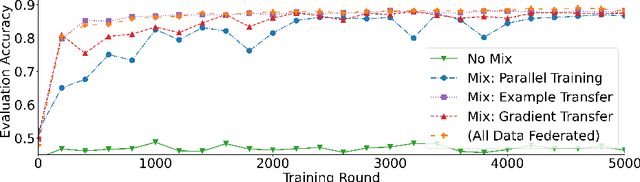
With privacy as a motivation, Federated Learning (FL) is an increasingly used paradigm where learning takes place collectively on edge devices, each with a cache of user-generated training examples that remain resident on the local device. These on-device training examples are gathered in situ during the course of users' interactions with their devices, and thus are highly reflective of at least part of the inference data distribution. Yet a distribution shift may still exist; the on-device training examples may lack for some data inputs expected to be encountered at inference time. This paper proposes a way to mitigate this shift: selective usage of datacenter data, mixed in with FL. By mixing decentralized (federated) and centralized (datacenter) data, we can form an effective training data distribution that better matches the inference data distribution, resulting in more useful models while still meeting the private training data access constraints imposed by FL.
Generative Models for Effective ML on Private, Decentralized Datasets
Nov 15, 2019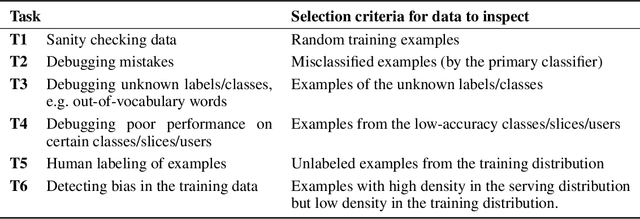
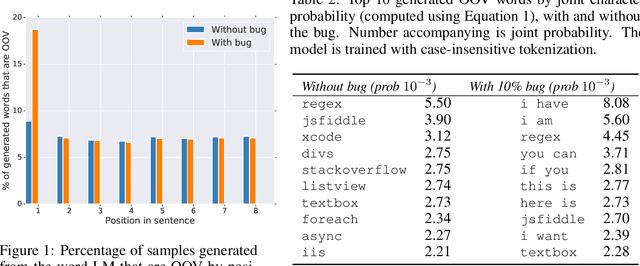
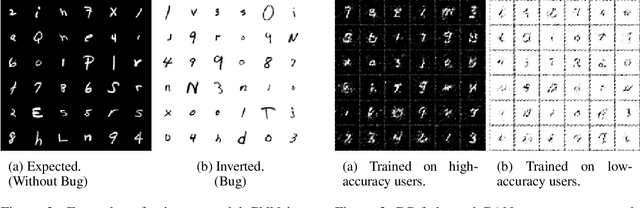
To improve real-world applications of machine learning, experienced modelers develop intuition about their datasets, their models, and how the two interact. Manual inspection of raw data - of representative samples, of outliers, of misclassifications - is an essential tool in a) identifying and fixing problems in the data, b) generating new modeling hypotheses, and c) assigning or refining human-provided labels. However, manual data inspection is problematic for privacy sensitive datasets, such as those representing the behavior of real-world individuals. Furthermore, manual data inspection is impossible in the increasingly important setting of federated learning, where raw examples are stored at the edge and the modeler may only access aggregated outputs such as metrics or model parameters. This paper demonstrates that generative models - trained using federated methods and with formal differential privacy guarantees - can be used effectively to debug many commonly occurring data issues even when the data cannot be directly inspected. We explore these methods in applications to text with differentially private federated RNNs and to images using a novel algorithm for differentially private federated GANs.
Federated Learning for Mobile Keyboard Prediction
Nov 08, 2018

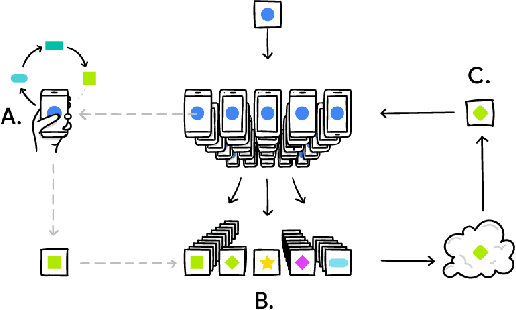

We train a recurrent neural network language model using a distributed, on-device learning framework called federated learning for the purpose of next-word prediction in a virtual keyboard for smartphones. Server-based training using stochastic gradient descent is compared with training on client devices using the Federated Averaging algorithm. The federated algorithm, which enables training on a higher-quality dataset for this use case, is shown to achieve better prediction recall. This work demonstrates the feasibility and benefit of training language models on client devices without exporting sensitive user data to servers. The federated learning environment gives users greater control over their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices.