 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocale Encoding For Scalable Multilingual Keyword Spotting Models
Feb 25, 2023



A Multilingual Keyword Spotting (KWS) system detects spokenkeywords over multiple locales. Conventional monolingual KWSapproaches do not scale well to multilingual scenarios because ofhigh development/maintenance costs and lack of resource sharing.To overcome this limit, we propose two locale-conditioned universalmodels with locale feature concatenation and feature-wise linearmodulation (FiLM). We compare these models with two baselinemethods: locale-specific monolingual KWS, and a single universalmodel trained over all data. Experiments over 10 localized languagedatasets show that locale-conditioned models substantially improveaccuracy over baseline methods across all locales in different noiseconditions.FiLMperformed the best, improving on average FRRby 61% (relative) compared to monolingual KWS models of similarsizes.
Augmenting Transformer-Transducer Based Speaker Change Detection With Token-Level Training Loss
Nov 11, 2022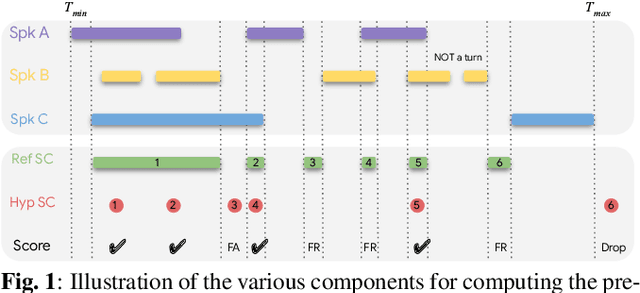
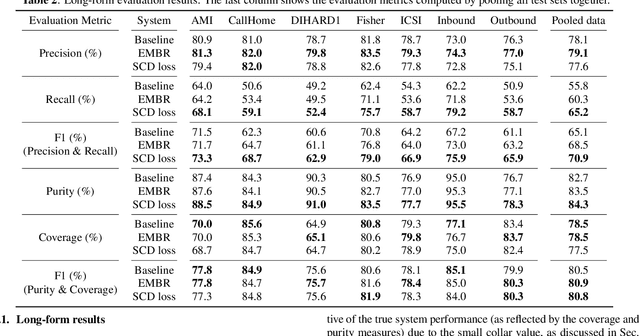
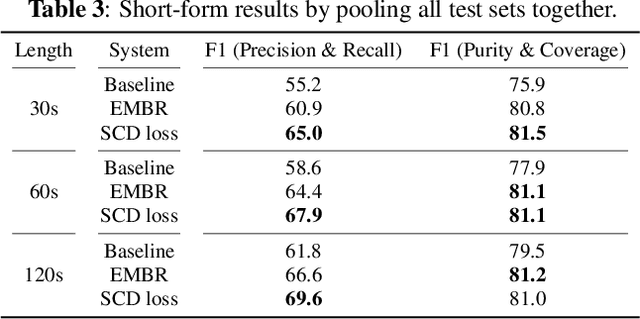
In this work we propose a novel token-based training strategy that improves Transformer-Transducer (T-T) based speaker change detection (SCD) performance. The conventional T-T based SCD model loss optimizes all output tokens equally. Due to the sparsity of the speaker changes in the training data, the conventional T-T based SCD model loss leads to sub-optimal detection accuracy. To mitigate this issue, we use a customized edit-distance algorithm to estimate the token-level SCD false accept (FA) and false reject (FR) rates during training and optimize model parameters to minimize a weighted combination of the FA and FR, focusing the model on accurately predicting speaker changes. We also propose a set of evaluation metrics that align better with commercial use cases. Experiments on a group of challenging real-world datasets show that the proposed training method can significantly improve the overall performance of the SCD model with the same number of parameters.
Highly Efficient Real-Time Streaming and Fully On-Device Speaker Diarization with Multi-Stage Clustering
Oct 25, 2022
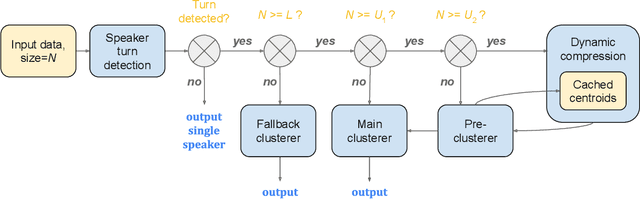
While recent research advances in speaker diarization mostly focus on improving the quality of diarization results, there is also an increasing interest in improving the efficiency of diarization systems. In this paper, we propose a multi-stage clustering strategy, that uses different clustering algorithms for input of different lengths. Specifically, a fallback clusterer is used to handle short-form inputs; a main clusterer is used to handle medium-length inputs; and a pre-clusterer is used to compress long-form inputs before they are processed by the main clusterer. Both the main clusterer and the pre-clusterer can be configured with an upper bound of the computational complexity to adapt to devices with different constraints. This multi-stage clustering strategy is critical for streaming on-device speaker diarization systems, where the budgets of CPU, memory and battery are tight.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022
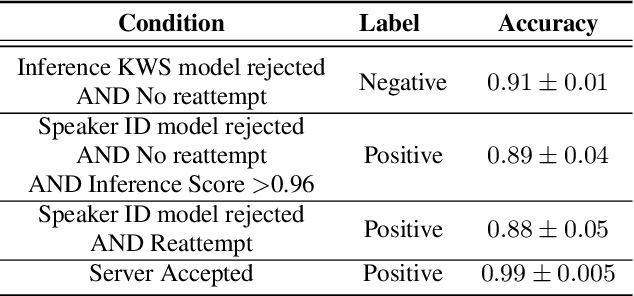
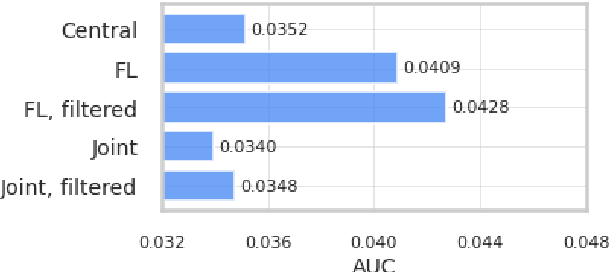

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
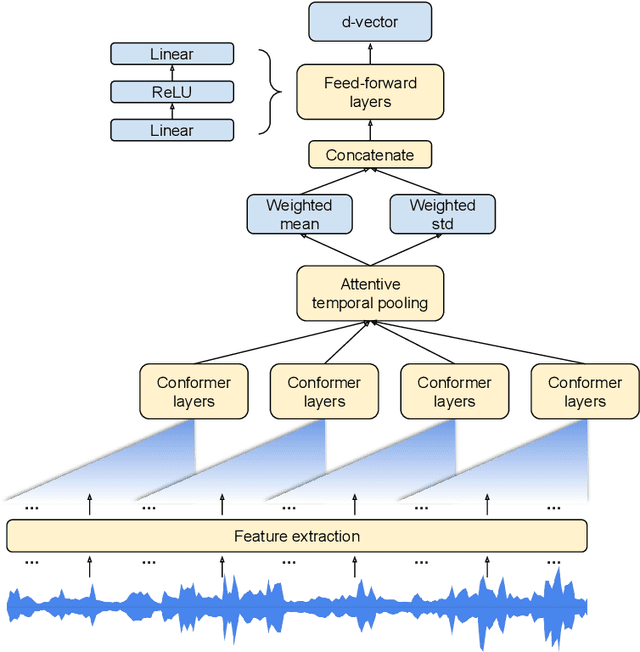
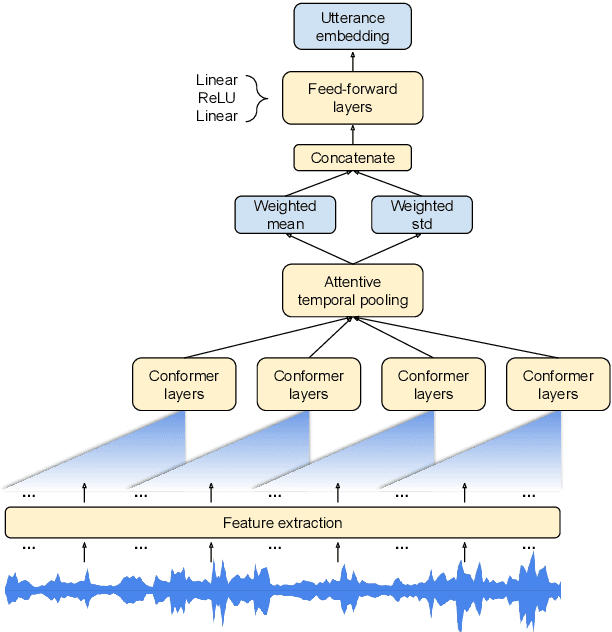
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Mar 21, 2022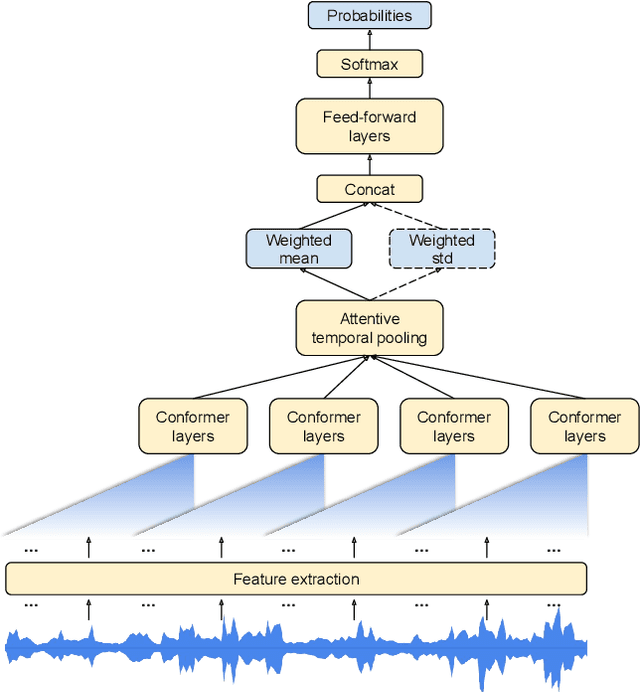
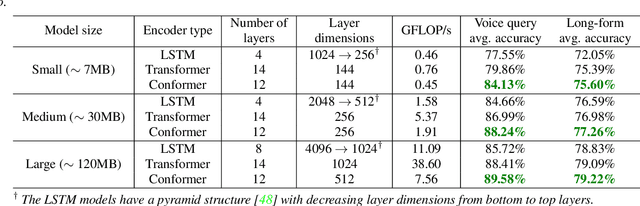
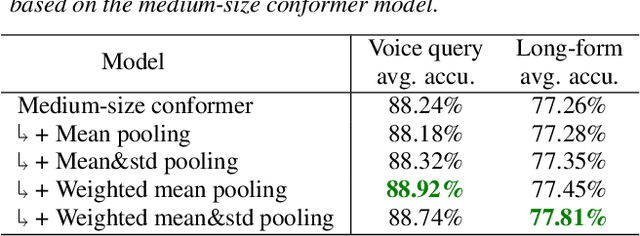
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
Parameter-Free Attentive Scoring for Speaker Verification
Mar 10, 2022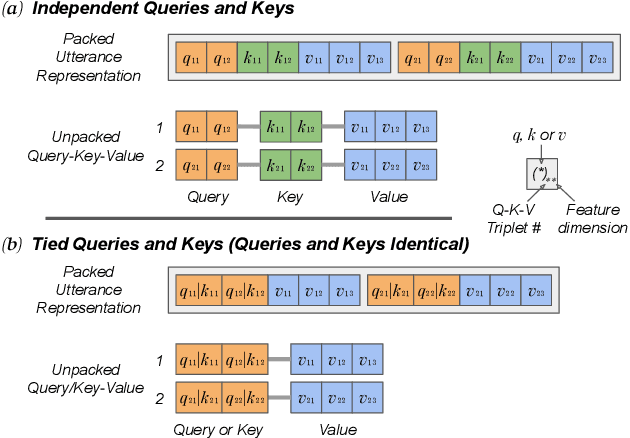
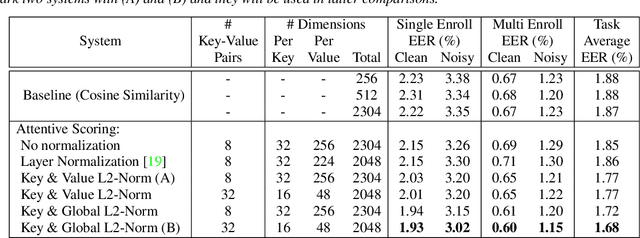
This paper presents a novel study of parameter-free attentive scoring for speaker verification. Parameter-free scoring provides the flexibility of comparing speaker representations without the need of an accompanying parametric scoring model. Inspired by the attention component in Transformer neural networks, we propose a variant of the scaled dot product attention mechanism to compare enrollment and test segment representations. In addition, this work explores the effect on performance of (i) different types of normalization, (ii) independent versus tied query/key estimation, (iii) varying the number of key-value pairs and (iv) pooling multiple enrollment utterance statistics. Experimental results for a 4 task average show that a simple parameter-free attentive scoring mechanism can improve the average EER by 10% over the best cosine similarity baseline.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Oct 05, 2021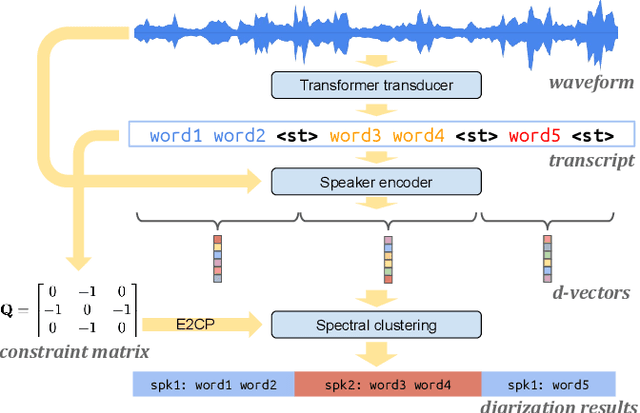

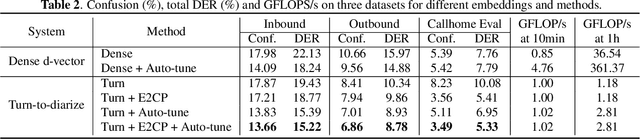
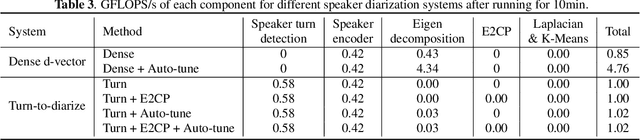
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
Noisy student-teacher training for robust keyword spotting
Jun 03, 2021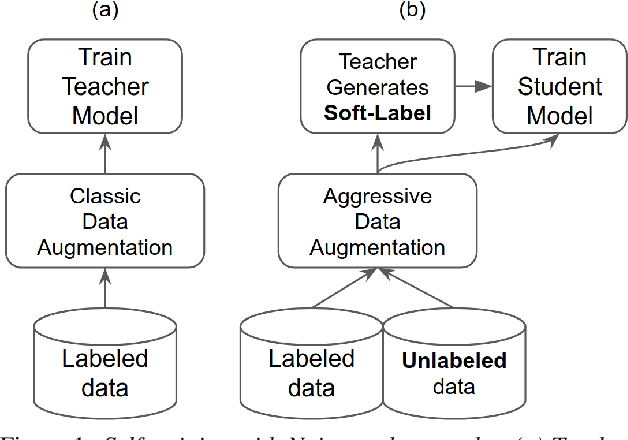

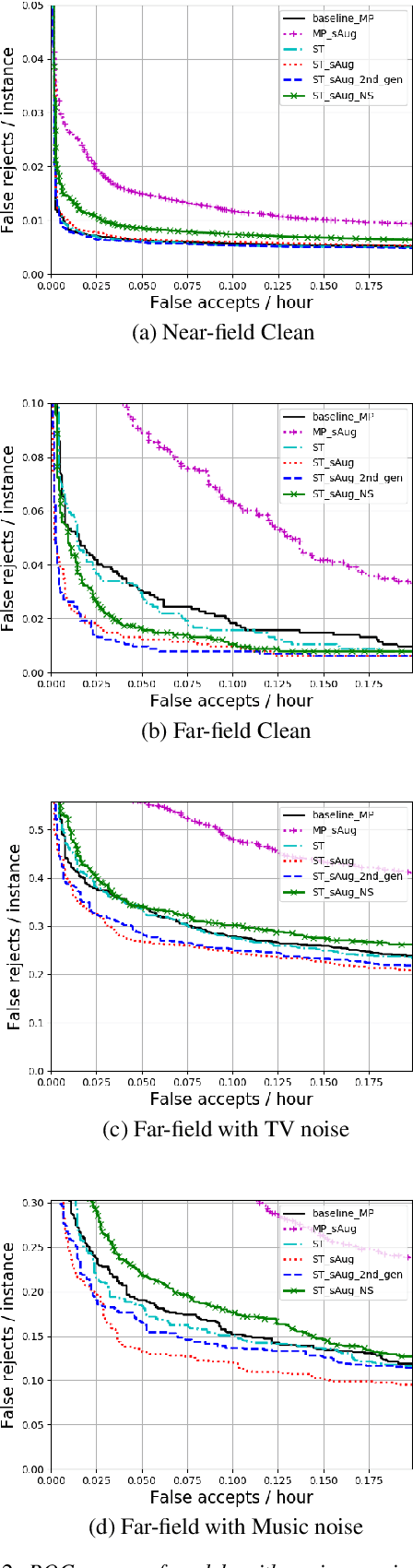
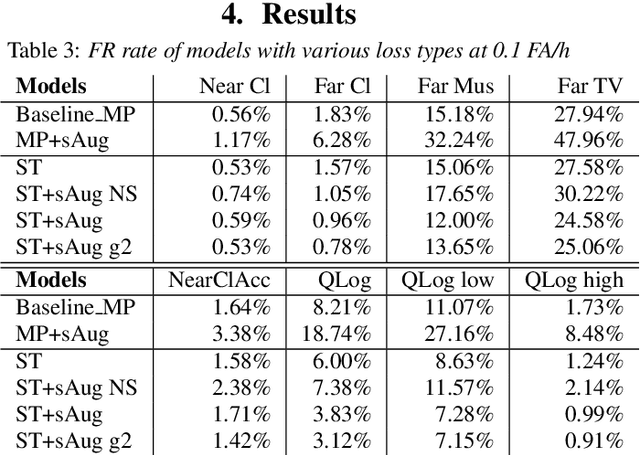
We propose self-training with noisy student-teacher approach for streaming keyword spotting, that can utilize large-scale unlabeled data and aggressive data augmentation. The proposed method applies aggressive data augmentation (spectral augmentation) on the input of both student and teacher and utilize unlabeled data at scale, which significantly boosts the accuracy of student against challenging conditions. Such aggressive augmentation usually degrades model performance when used with supervised training with hard-labeled data. Experiments show that aggressive spec augmentation on baseline supervised training method degrades accuracy, while the proposed self-training with noisy student-teacher training improves accuracy of some difficult-conditioned test sets by as much as 60%.
SpeakerStew: Scaling to Many Languages with a Triaged Multilingual Text-Dependent and Text-Independent Speaker Verification System
Apr 26, 2021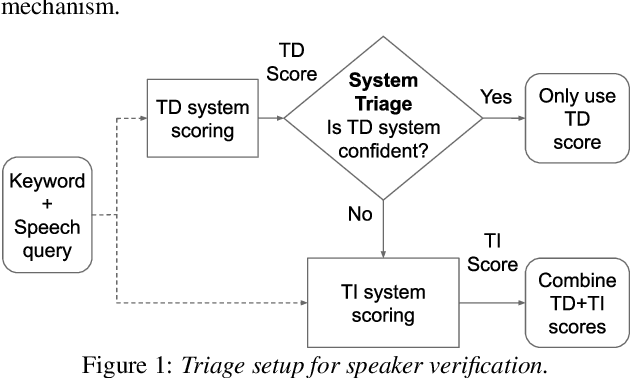
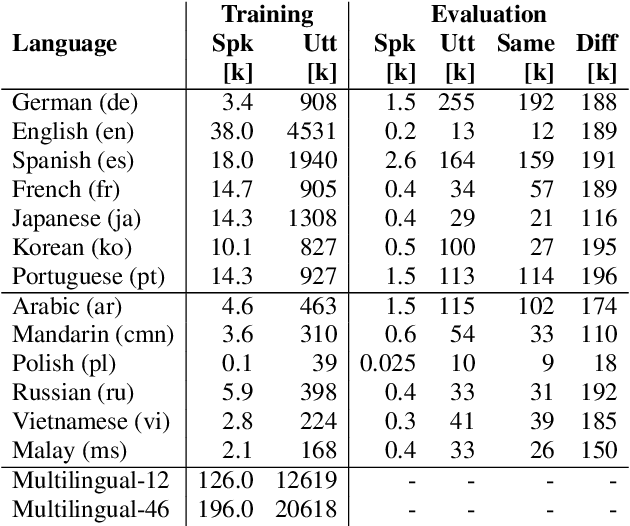
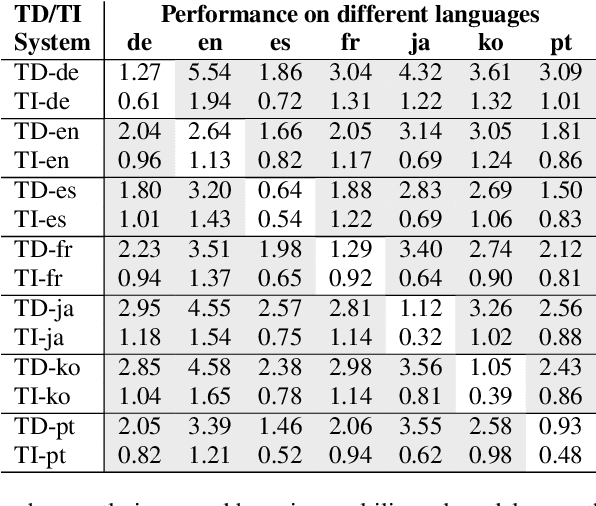
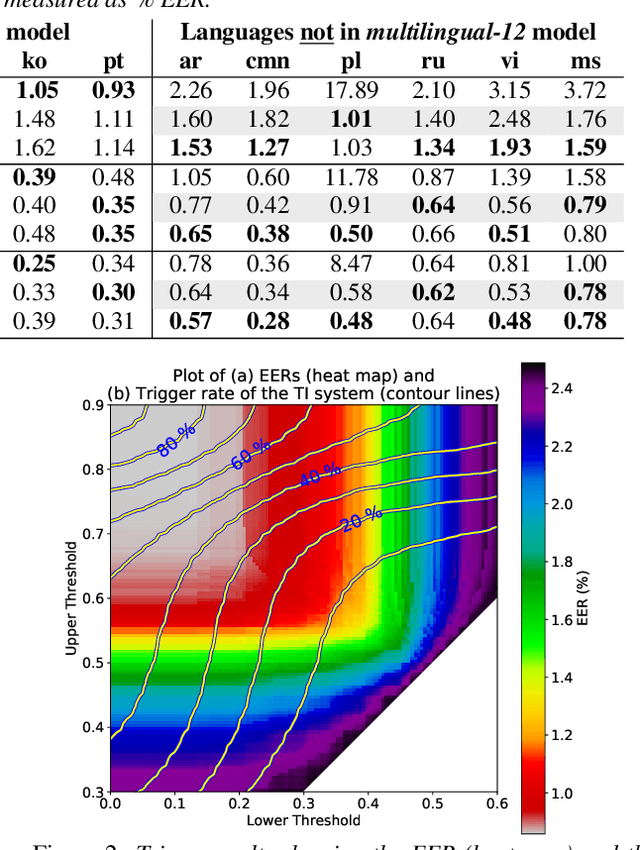
In this paper, we describe SpeakerStew - a hybrid system to perform speaker verification on 46 languages. Two core ideas were explored in this system: (1) Pooling training data of different languages together for multilingual generalization and reducing development cycles; (2) A triage mechanism between text-dependent and text-independent models to reduce runtime cost and expected latency. To the best of our knowledge, this is the first study of speaker verification systems at the scale of 46 languages. The problem is framed from the perspective of using a smart speaker device with interactions consisting of a wake-up keyword (text-dependent) followed by a speech query (text-independent).Experimental evidence suggests that training on multiple languages can generalize to unseen varieties while maintaining performance on seen varieties. We also found that it can reduce computational requirements for training models by an order of magnitude. Furthermore, during model inference on English data, we observe that leveraging a triage framework can reduce the number of calls to the more computationally expensive text-independent system by 73% (and reduce latency by 60%) while maintaining an EER no worse than the text-independent setup.
Dr-Vectors: Decision Residual Networks and an Improved Loss for Speaker Recognition
Apr 05, 2021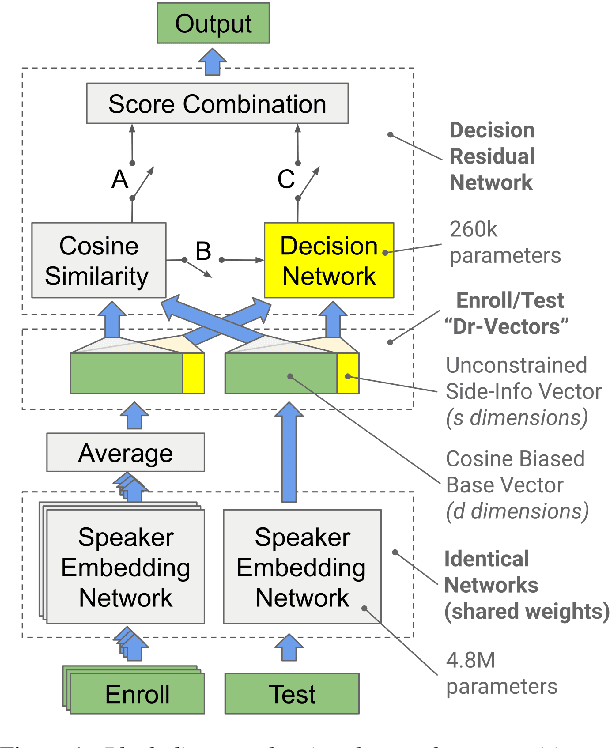
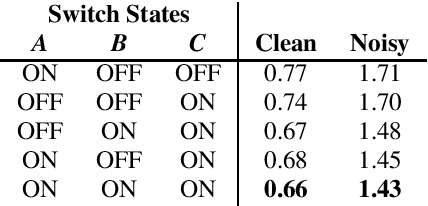
Many neural network speaker recognition systems model each speaker using a fixed-dimensional embedding vector. These embeddings are generally compared using either linear or 2nd-order scoring and, until recently, do not handle utterance-specific uncertainty. In this work we propose scoring these representations in a way that can capture uncertainty, enroll/test asymmetry and additional non-linear information. This is achieved by incorporating a 2nd-stage neural network (known as a decision network) as part of an end-to-end training regimen. In particular, we propose the concept of decision residual networks which involves the use of a compact decision network to leverage cosine scores and to model the residual signal that's needed. Additionally, we present a modification to the generalized end-to-end softmax loss function to better target the separation of same/different speaker scores. We observed significant performance gains for the two techniques.