 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiarizationLM: Speaker Diarization Post-Processing with Large Language Models
Jan 16, 2024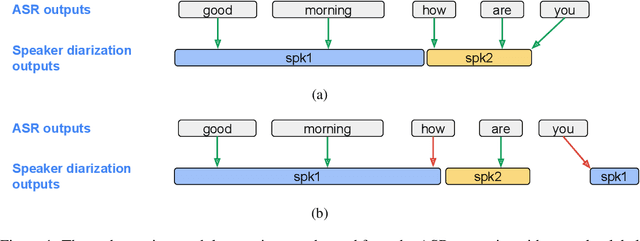



In this paper, we introduce DiarizationLM, a framework to leverage large language models (LLM) to post-process the outputs from a speaker diarization system. Various goals can be achieved with the proposed framework, such as improving the readability of the diarized transcript, or reducing the word diarization error rate (WDER). In this framework, the outputs of the automatic speech recognition (ASR) and speaker diarization systems are represented as a compact textual format, which is included in the prompt to an optionally finetuned LLM. The outputs of the LLM can be used as the refined diarization results with the desired enhancement. As a post-processing step, this framework can be easily applied to any off-the-shelf ASR and speaker diarization systems without retraining existing components. Our experiments show that a finetuned PaLM 2-S model can reduce the WDER by rel. 55.5% on the Fisher telephone conversation dataset, and rel. 44.9% on the Callhome English dataset.
Personalizing Keyword Spotting with Speaker Information
Nov 06, 2023



Keyword spotting systems often struggle to generalize to a diverse population with various accents and age groups. To address this challenge, we propose a novel approach that integrates speaker information into keyword spotting using Feature-wise Linear Modulation (FiLM), a recent method for learning from multiple sources of information. We explore both Text-Dependent and Text-Independent speaker recognition systems to extract speaker information, and we experiment on extracting this information from both the input audio and pre-enrolled user audio. We evaluate our systems on a diverse dataset and achieve a substantial improvement in keyword detection accuracy, particularly among underrepresented speaker groups. Moreover, our proposed approach only requires a small 1% increase in the number of parameters, with a minimum impact on latency and computational cost, which makes it a practical solution for real-world applications.
Towards Word-Level End-to-End Neural Speaker Diarization with Auxiliary Network
Sep 15, 2023



While standard speaker diarization attempts to answer the question "who spoken when", most of relevant applications in reality are more interested in determining "who spoken what". Whether it is the conventional modularized approach or the more recent end-to-end neural diarization (EEND), an additional automatic speech recognition (ASR) model and an orchestration algorithm are required to associate the speaker labels with recognized words. In this paper, we propose Word-level End-to-End Neural Diarization (WEEND) with auxiliary network, a multi-task learning algorithm that performs end-to-end ASR and speaker diarization in the same neural architecture. That is, while speech is being recognized, speaker labels are predicted simultaneously for each recognized word. Experimental results demonstrate that WEEND outperforms the turn-based diarization baseline system on all 2-speaker short-form scenarios and has the capability to generalize to audio lengths of 5 minutes. Although 3+speaker conversations are harder, we find that with enough in-domain training data, WEEND has the potential to deliver high quality diarized text.
USM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Augmenting Transformer-Transducer Based Speaker Change Detection With Token-Level Training Loss
Nov 11, 2022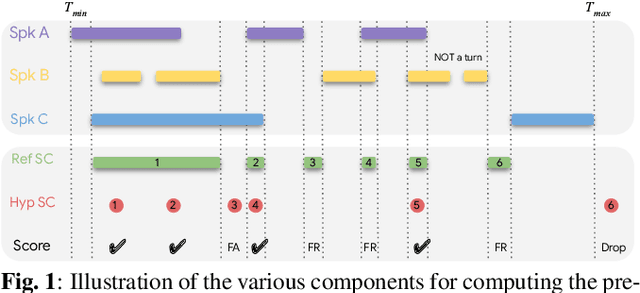
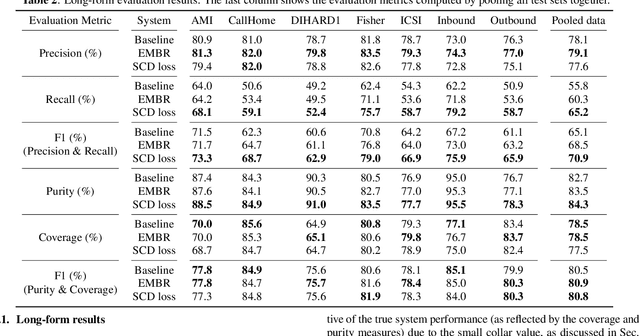
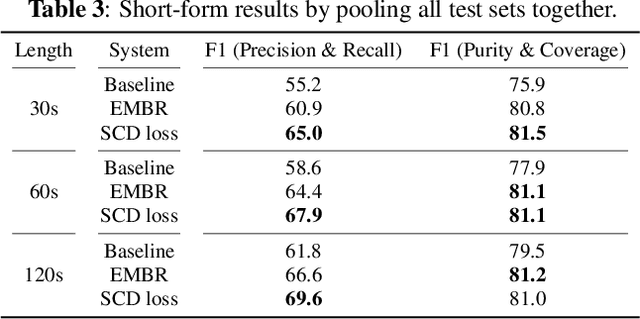
In this work we propose a novel token-based training strategy that improves Transformer-Transducer (T-T) based speaker change detection (SCD) performance. The conventional T-T based SCD model loss optimizes all output tokens equally. Due to the sparsity of the speaker changes in the training data, the conventional T-T based SCD model loss leads to sub-optimal detection accuracy. To mitigate this issue, we use a customized edit-distance algorithm to estimate the token-level SCD false accept (FA) and false reject (FR) rates during training and optimize model parameters to minimize a weighted combination of the FA and FR, focusing the model on accurately predicting speaker changes. We also propose a set of evaluation metrics that align better with commercial use cases. Experiments on a group of challenging real-world datasets show that the proposed training method can significantly improve the overall performance of the SCD model with the same number of parameters.
Exploring Sequence-to-Sequence Transformer-Transducer Models for Keyword Spotting
Nov 11, 2022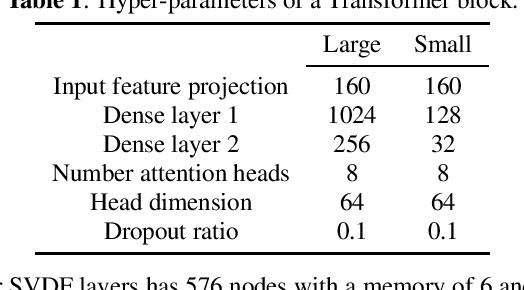
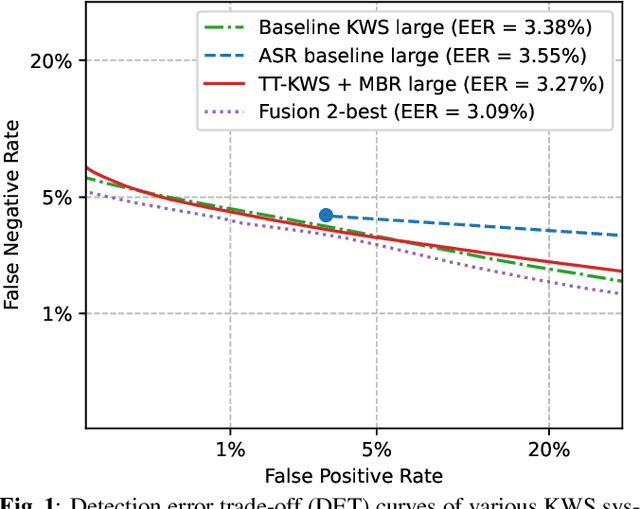
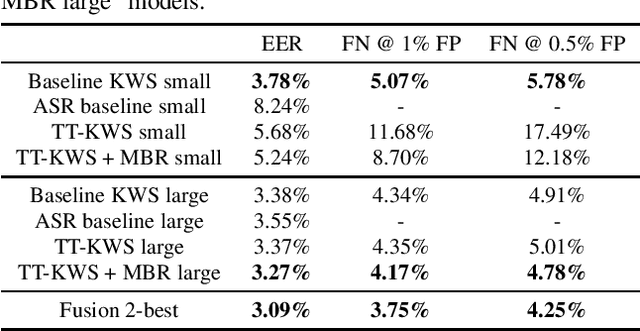
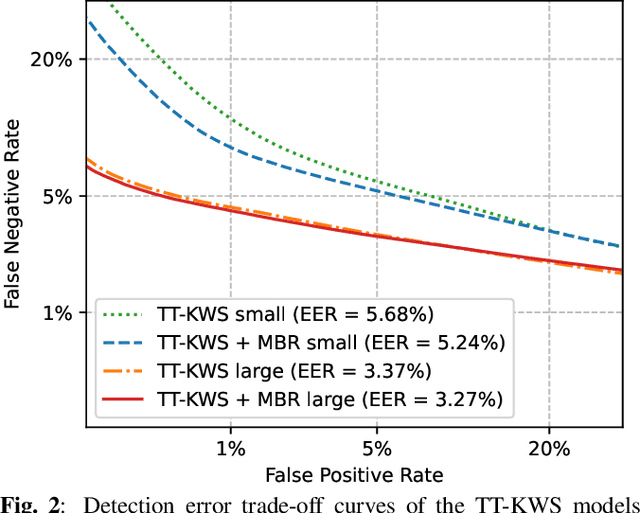
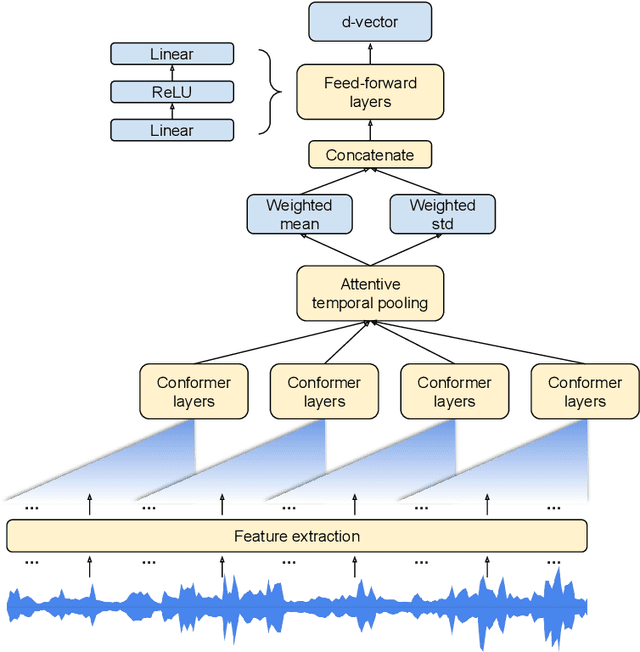
In this paper, we present a novel approach to adapt a sequence-to-sequence Transformer-Transducer ASR system to the keyword spotting (KWS) task. We achieve this by replacing the keyword in the text transcription with a special token <kw> and training the system to detect the <kw> token in an audio stream. At inference time, we create a decision function inspired by conventional KWS approaches, to make our approach more suitable for the KWS task. Furthermore, we introduce a specific keyword spotting loss by adapting the sequence-discriminative Minimum Bayes-Risk training technique. We find that our approach significantly outperforms ASR based KWS systems. When compared with a conventional keyword spotting system, our proposal has similar performance while bringing the advantages and flexibility of sequence-to-sequence training. Additionally, when combined with the conventional KWS system, our approach can improve the performance at any operation point.
Highly Efficient Real-Time Streaming and Fully On-Device Speaker Diarization with Multi-Stage Clustering
Oct 25, 2022
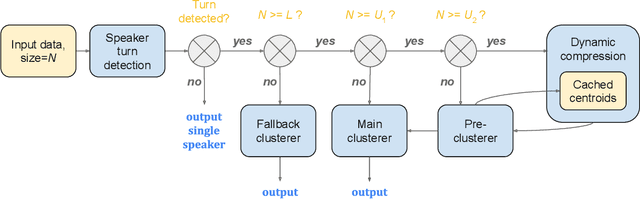
While recent research advances in speaker diarization mostly focus on improving the quality of diarization results, there is also an increasing interest in improving the efficiency of diarization systems. In this paper, we propose a multi-stage clustering strategy, that uses different clustering algorithms for input of different lengths. Specifically, a fallback clusterer is used to handle short-form inputs; a main clusterer is used to handle medium-length inputs; and a pre-clusterer is used to compress long-form inputs before they are processed by the main clusterer. Both the main clusterer and the pre-clusterer can be configured with an upper bound of the computational complexity to adapt to devices with different constraints. This multi-stage clustering strategy is critical for streaming on-device speaker diarization systems, where the budgets of CPU, memory and battery are tight.
LSTM Acoustic Models Learn to Align and Pronounce with Graphemes
Aug 13, 2020

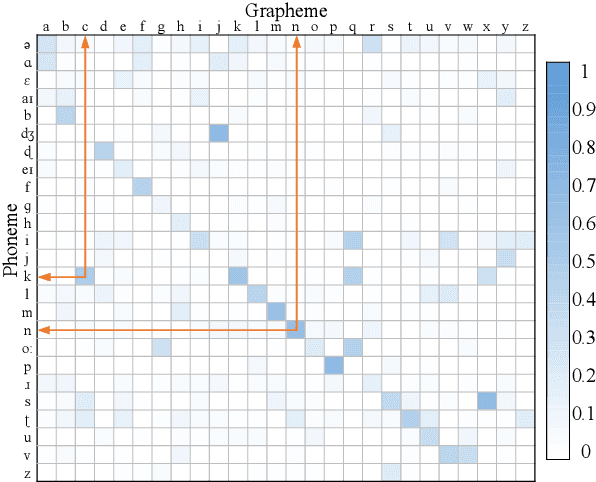
Automated speech recognition coverage of the world's languages continues to expand. However, standard phoneme based systems require handcrafted lexicons that are difficult and expensive to obtain. To address this problem, we propose a training methodology for a grapheme-based speech recognizer that can be trained in a purely data-driven fashion. Built with LSTM networks and trained with the cross-entropy loss, the grapheme-output acoustic models we study are also extremely practical for real-world applications as they can be decoded with conventional ASR stack components such as language models and FST decoders, and produce good quality audio-to-grapheme alignments that are useful in many speech applications. We show that the grapheme models are competitive in WER with their phoneme-output counterparts when trained on large datasets, with the advantage that grapheme models do not require explicit linguistic knowledge as an input. We further compare the alignments generated by the phoneme and grapheme models to demonstrate the quality of the pronunciations learnt by them using four Indian languages that vary linguistically in spoken and written forms.
Improved Techniques for Learning to Dehaze and Beyond: A Collective Study
Jul 30, 2018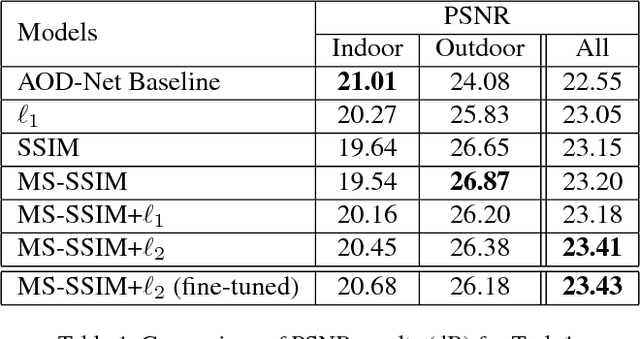
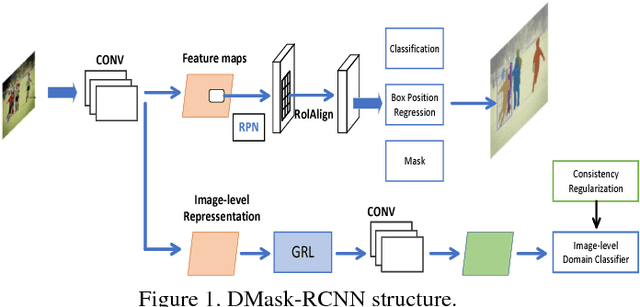
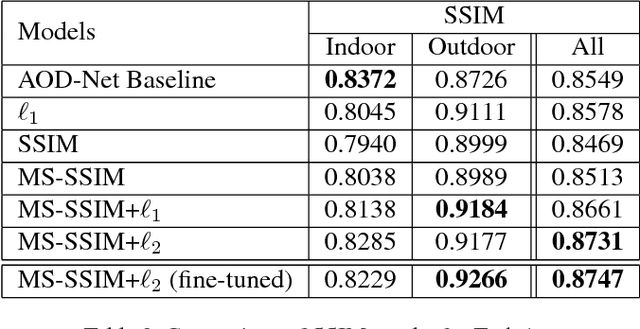
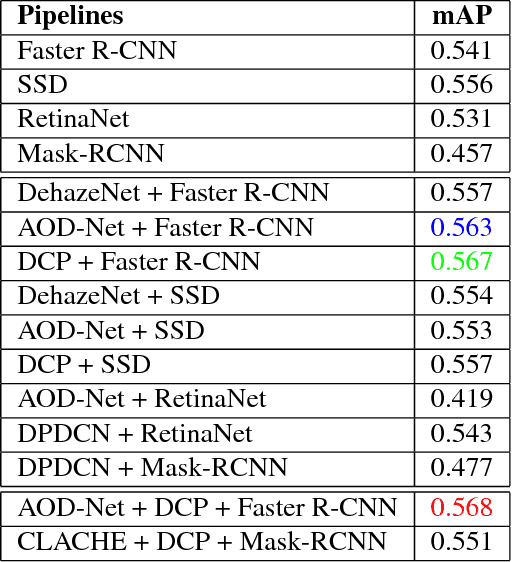
Here we explore two related but important tasks based on the recently released REalistic Single Image DEhazing (RESIDE) benchmark dataset: (i) single image dehazing as a low-level image restoration problem; and (ii) high-level visual understanding (e.g., object detection) of hazy images. For the first task, we investigated a variety of loss functions and show that perception-driven loss significantly improves dehazing performance. In the second task, we provide multiple solutions including using advanced modules in the dehazing-detection cascade and domain-adaptive object detectors. In both tasks, our proposed solutions significantly improve performance. GitHub repository URL is: https://github.com/guanlongzhao/dehaze
PAD-Net: A Perception-Aided Single Image Dehazing Network
May 08, 2018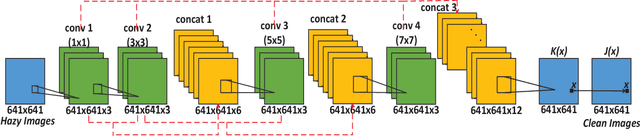
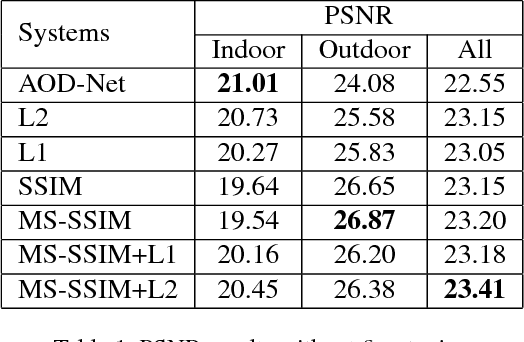
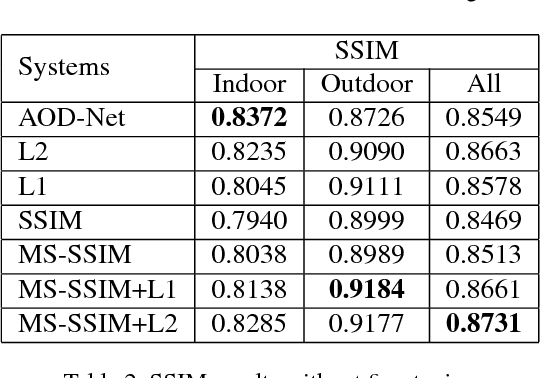
In this work, we investigate the possibility of replacing the $\ell_2$ loss with perceptually derived loss functions (SSIM, MS-SSIM, etc.) in training an end-to-end dehazing neural network. Objective experimental results suggest that by merely changing the loss function we can obtain significantly higher PSNR and SSIM scores on the SOTS set in the RESIDE dataset, compared with a state-of-the-art end-to-end dehazing neural network (AOD-Net) that uses the $\ell_2$ loss. The best PSNR we obtained was 23.50 (4.2% relative improvement), and the best SSIM we obtained was 0.8747 (2.3% relative improvement.)