 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Keyword Spotting with Speaker Information
Nov 06, 2023



Keyword spotting systems often struggle to generalize to a diverse population with various accents and age groups. To address this challenge, we propose a novel approach that integrates speaker information into keyword spotting using Feature-wise Linear Modulation (FiLM), a recent method for learning from multiple sources of information. We explore both Text-Dependent and Text-Independent speaker recognition systems to extract speaker information, and we experiment on extracting this information from both the input audio and pre-enrolled user audio. We evaluate our systems on a diverse dataset and achieve a substantial improvement in keyword detection accuracy, particularly among underrepresented speaker groups. Moreover, our proposed approach only requires a small 1% increase in the number of parameters, with a minimum impact on latency and computational cost, which makes it a practical solution for real-world applications.
Locale Encoding For Scalable Multilingual Keyword Spotting Models
Feb 25, 2023



A Multilingual Keyword Spotting (KWS) system detects spokenkeywords over multiple locales. Conventional monolingual KWSapproaches do not scale well to multilingual scenarios because ofhigh development/maintenance costs and lack of resource sharing.To overcome this limit, we propose two locale-conditioned universalmodels with locale feature concatenation and feature-wise linearmodulation (FiLM). We compare these models with two baselinemethods: locale-specific monolingual KWS, and a single universalmodel trained over all data. Experiments over 10 localized languagedatasets show that locale-conditioned models substantially improveaccuracy over baseline methods across all locales in different noiseconditions.FiLMperformed the best, improving on average FRRby 61% (relative) compared to monolingual KWS models of similarsizes.
Exploring Sequence-to-Sequence Transformer-Transducer Models for Keyword Spotting
Nov 11, 2022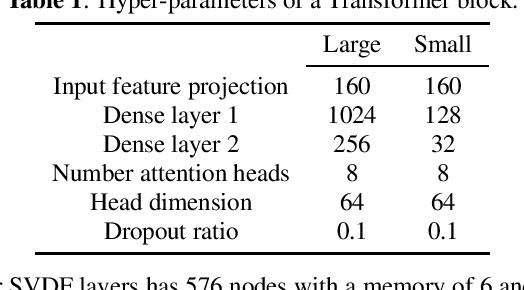
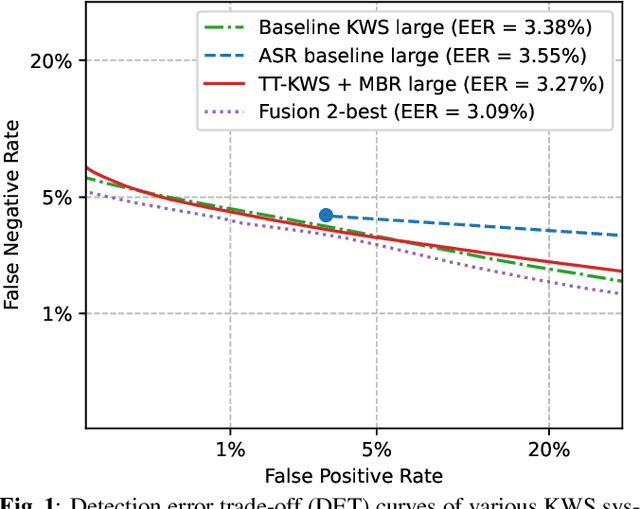
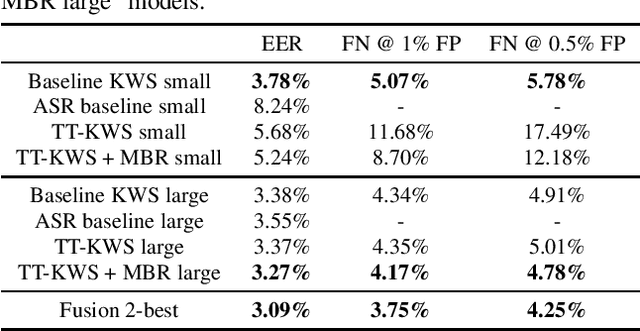
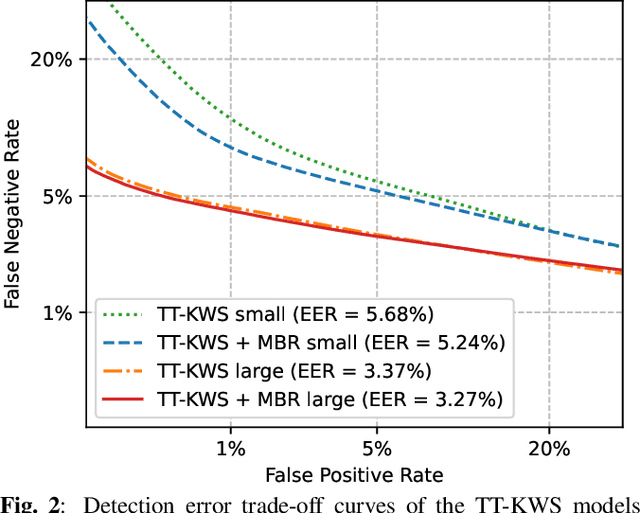
In this paper, we present a novel approach to adapt a sequence-to-sequence Transformer-Transducer ASR system to the keyword spotting (KWS) task. We achieve this by replacing the keyword in the text transcription with a special token <kw> and training the system to detect the <kw> token in an audio stream. At inference time, we create a decision function inspired by conventional KWS approaches, to make our approach more suitable for the KWS task. Furthermore, we introduce a specific keyword spotting loss by adapting the sequence-discriminative Minimum Bayes-Risk training technique. We find that our approach significantly outperforms ASR based KWS systems. When compared with a conventional keyword spotting system, our proposal has similar performance while bringing the advantages and flexibility of sequence-to-sequence training. Additionally, when combined with the conventional KWS system, our approach can improve the performance at any operation point.