 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian Splatting with Normal Information for Mesh Extraction and Improved Rendering
Jan 14, 2025



Differentiable 3D Gaussian splatting has emerged as an efficient and flexible rendering technique for representing complex scenes from a collection of 2D views and enabling high-quality real-time novel-view synthesis. However, its reliance on photometric losses can lead to imprecisely reconstructed geometry and extracted meshes, especially in regions with high curvature or fine detail. We propose a novel regularization method using the gradients of a signed distance function estimated from the Gaussians, to improve the quality of rendering while also extracting a surface mesh. The regularizing normal supervision facilitates better rendering and mesh reconstruction, which is crucial for downstream applications in video generation, animation, AR-VR and gaming. We demonstrate the effectiveness of our approach on datasets such as Mip-NeRF360, Tanks and Temples, and Deep-Blending. Our method scores higher on photorealism metrics compared to other mesh extracting rendering methods without compromising mesh quality.
Generating Potent Poisons and Backdoors from Scratch with Guided Diffusion
Mar 25, 2024



Modern neural networks are often trained on massive datasets that are web scraped with minimal human inspection. As a result of this insecure curation pipeline, an adversary can poison or backdoor the resulting model by uploading malicious data to the internet and waiting for a victim to scrape and train on it. Existing approaches for creating poisons and backdoors start with randomly sampled clean data, called base samples, and then modify those samples to craft poisons. However, some base samples may be significantly more amenable to poisoning than others. As a result, we may be able to craft more potent poisons by carefully choosing the base samples. In this work, we use guided diffusion to synthesize base samples from scratch that lead to significantly more potent poisons and backdoors than previous state-of-the-art attacks. Our Guided Diffusion Poisoning (GDP) base samples can be combined with any downstream poisoning or backdoor attack to boost its effectiveness. Our implementation code is publicly available at: https://github.com/hsouri/GDP .
Exploring Sequence-to-Sequence Transformer-Transducer Models for Keyword Spotting
Nov 11, 2022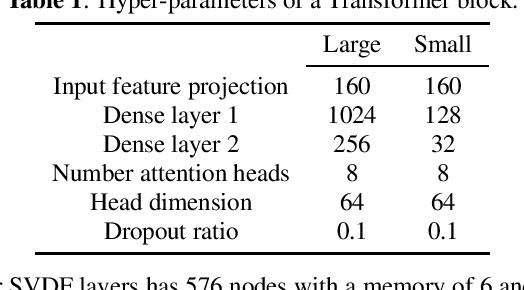
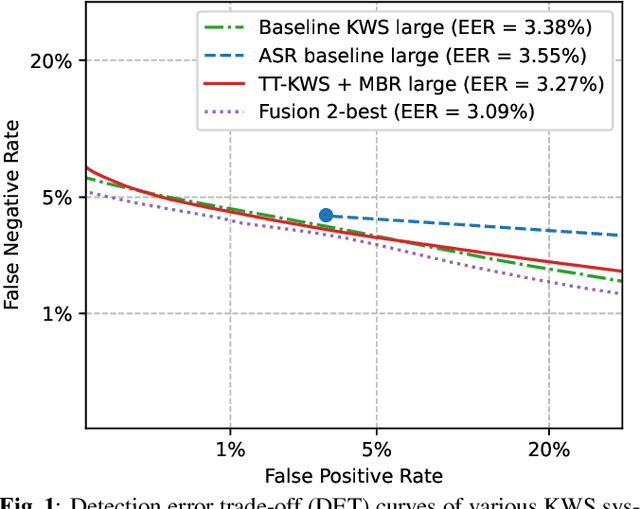
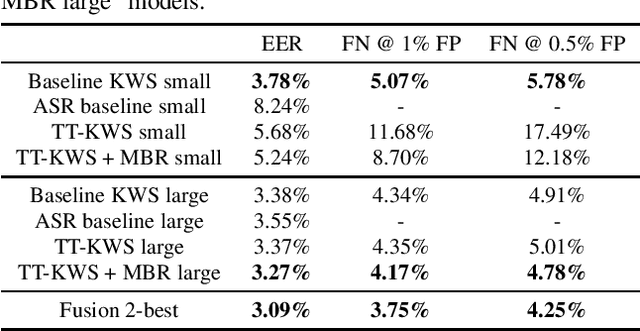
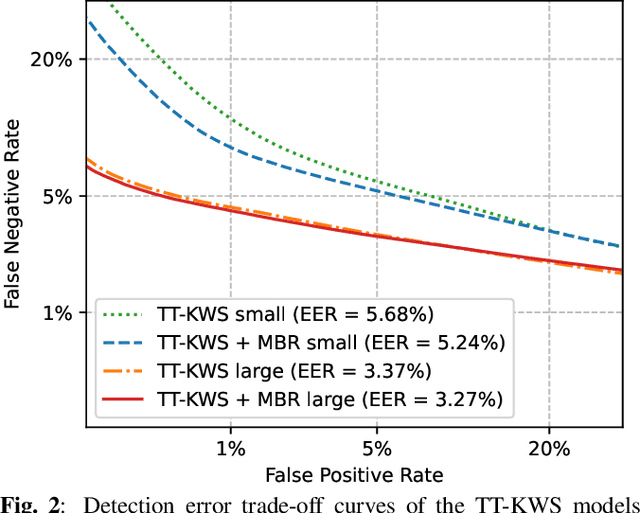
In this paper, we present a novel approach to adapt a sequence-to-sequence Transformer-Transducer ASR system to the keyword spotting (KWS) task. We achieve this by replacing the keyword in the text transcription with a special token <kw> and training the system to detect the <kw> token in an audio stream. At inference time, we create a decision function inspired by conventional KWS approaches, to make our approach more suitable for the KWS task. Furthermore, we introduce a specific keyword spotting loss by adapting the sequence-discriminative Minimum Bayes-Risk training technique. We find that our approach significantly outperforms ASR based KWS systems. When compared with a conventional keyword spotting system, our proposal has similar performance while bringing the advantages and flexibility of sequence-to-sequence training. Additionally, when combined with the conventional KWS system, our approach can improve the performance at any operation point.
Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning
Oct 17, 2022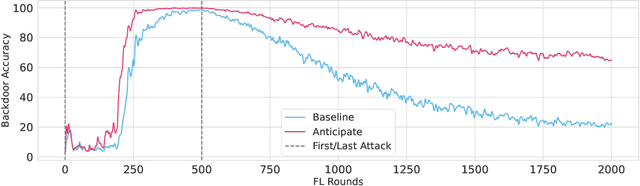
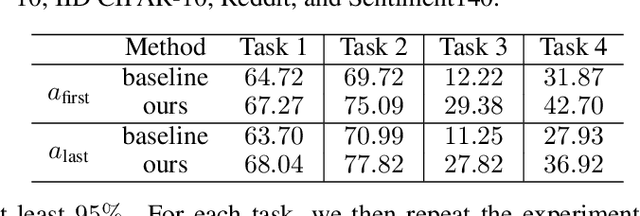
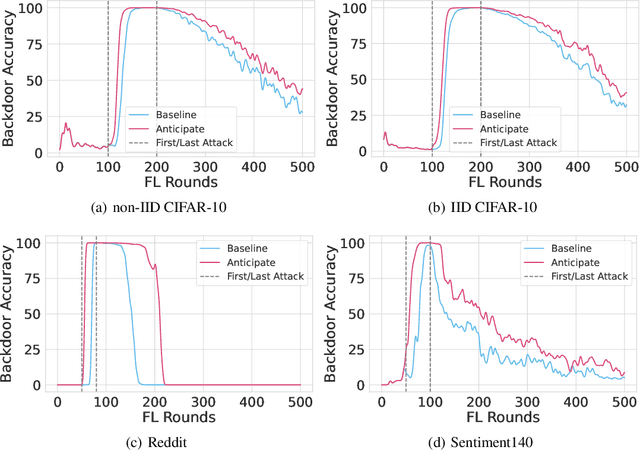
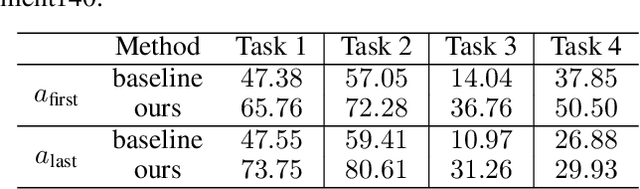
Federated learning is particularly susceptible to model poisoning and backdoor attacks because individual users have direct control over the training data and model updates. At the same time, the attack power of an individual user is limited because their updates are quickly drowned out by those of many other users. Existing attacks do not account for future behaviors of other users, and thus require many sequential updates and their effects are quickly erased. We propose an attack that anticipates and accounts for the entire federated learning pipeline, including behaviors of other clients, and ensures that backdoors are effective quickly and persist even after multiple rounds of community updates. We show that this new attack is effective in realistic scenarios where the attacker only contributes to a small fraction of randomly sampled rounds and demonstrate this attack on image classification, next-word prediction, and sentiment analysis.
Poisons that are learned faster are more effective
Apr 19, 2022
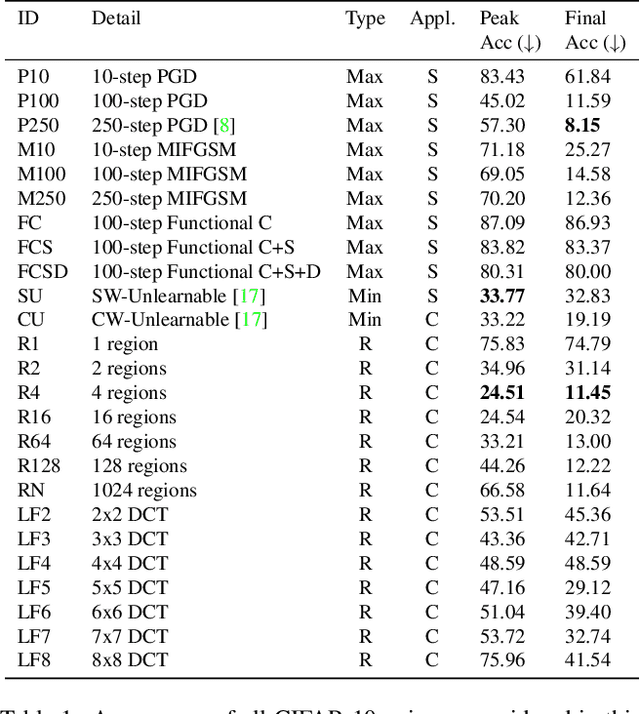
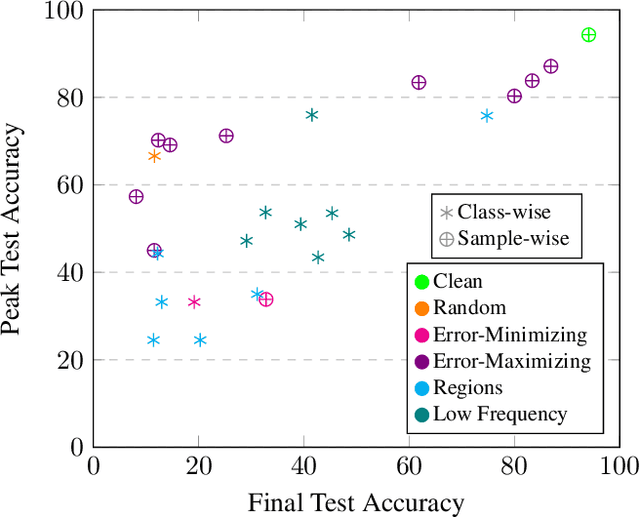

Imperceptible poisoning attacks on entire datasets have recently been touted as methods for protecting data privacy. However, among a number of defenses preventing the practical use of these techniques, early-stopping stands out as a simple, yet effective defense. To gauge poisons' vulnerability to early-stopping, we benchmark error-minimizing, error-maximizing, and synthetic poisons in terms of peak test accuracy over 100 epochs and make a number of surprising observations. First, we find that poisons that reach a low training loss faster have lower peak test accuracy. Second, we find that a current state-of-the-art error-maximizing poison is 7 times less effective when poison training is stopped at epoch 8. Third, we find that stronger, more transferable adversarial attacks do not make stronger poisons. We advocate for evaluating poisons in terms of peak test accuracy.
Can Neural Nets Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary Perspective
Mar 15, 2022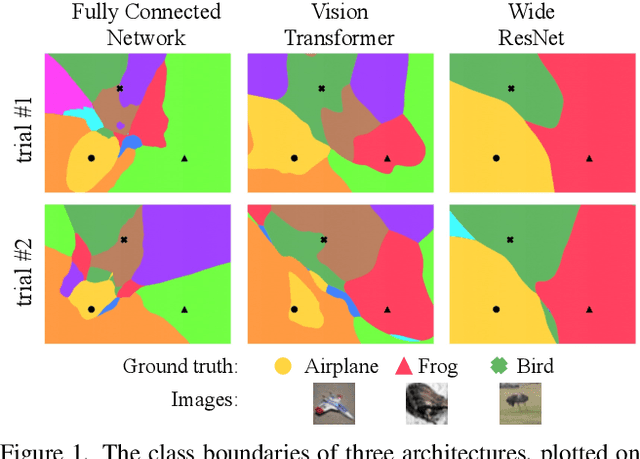
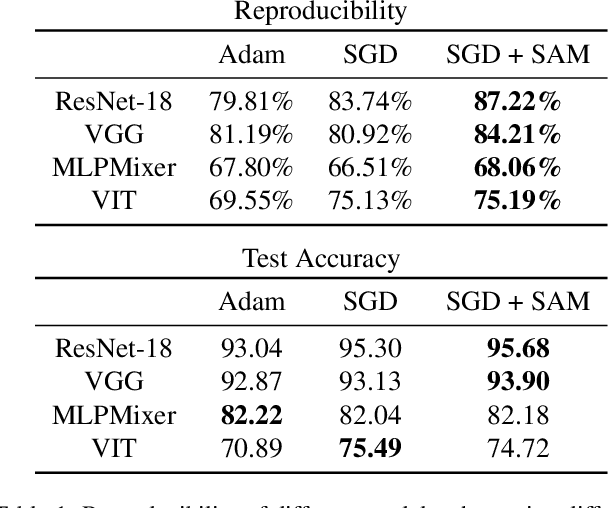
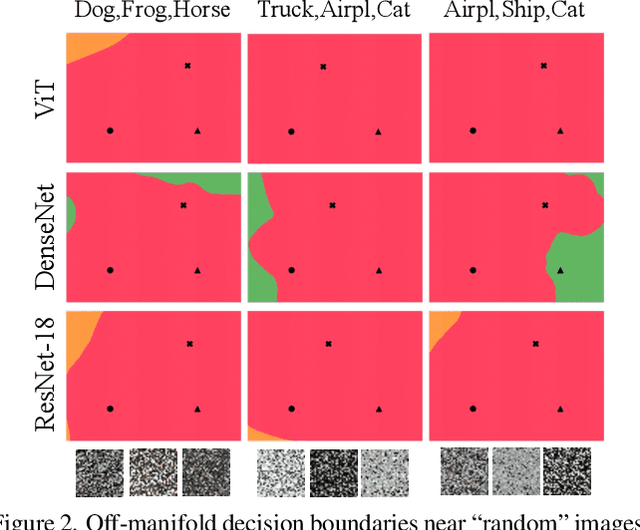

We discuss methods for visualizing neural network decision boundaries and decision regions. We use these visualizations to investigate issues related to reproducibility and generalization in neural network training. We observe that changes in model architecture (and its associate inductive bias) cause visible changes in decision boundaries, while multiple runs with the same architecture yield results with strong similarities, especially in the case of wide architectures. We also use decision boundary methods to visualize double descent phenomena. We see that decision boundary reproducibility depends strongly on model width. Near the threshold of interpolation, neural network decision boundaries become fragmented into many small decision regions, and these regions are non-reproducible. Meanwhile, very narrows and very wide networks have high levels of reproducibility in their decision boundaries with relatively few decision regions. We discuss how our observations relate to the theory of double descent phenomena in convex models. Code is available at https://github.com/somepago/dbViz
Fishing for User Data in Large-Batch Federated Learning via Gradient Magnification
Feb 01, 2022

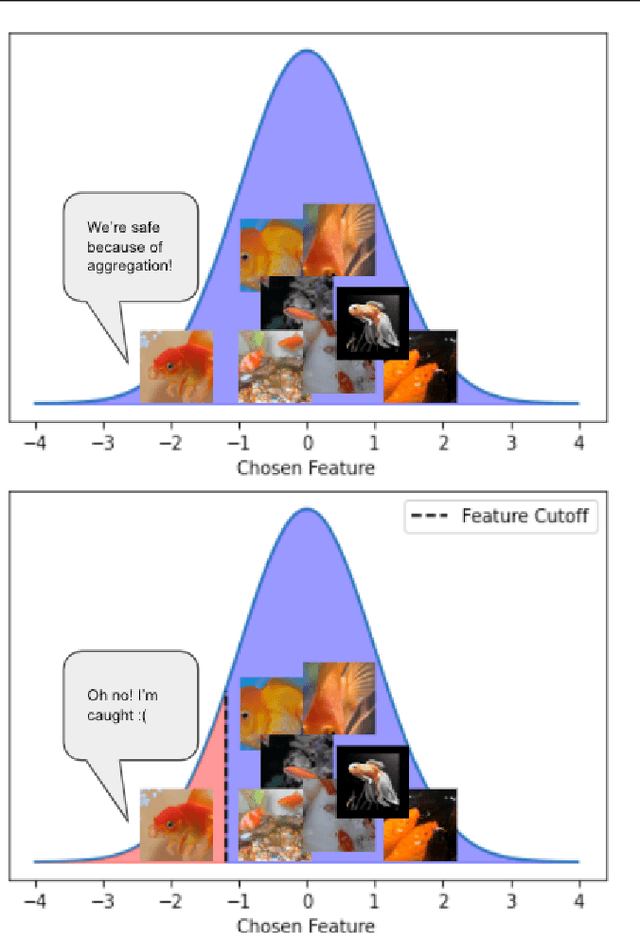

Federated learning (FL) has rapidly risen in popularity due to its promise of privacy and efficiency. Previous works have exposed privacy vulnerabilities in the FL pipeline by recovering user data from gradient updates. However, existing attacks fail to address realistic settings because they either 1) require a `toy' settings with very small batch sizes, or 2) require unrealistic and conspicuous architecture modifications. We introduce a new strategy that dramatically elevates existing attacks to operate on batches of arbitrarily large size, and without architectural modifications. Our model-agnostic strategy only requires modifications to the model parameters sent to the user, which is a realistic threat model in many scenarios. We demonstrate the strategy in challenging large-scale settings, obtaining high-fidelity data extraction in both cross-device and cross-silo federated learning.
Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language Models
Jan 29, 2022



A central tenet of Federated learning (FL), which trains models without centralizing user data, is privacy. However, previous work has shown that the gradient updates used in FL can leak user information. While the most industrial uses of FL are for text applications (e.g. keystroke prediction), nearly all attacks on FL privacy have focused on simple image classifiers. We propose a novel attack that reveals private user text by deploying malicious parameter vectors, and which succeeds even with mini-batches, multiple users, and long sequences. Unlike previous attacks on FL, the attack exploits characteristics of both the Transformer architecture and the token embedding, separately extracting tokens and positional embeddings to retrieve high-fidelity text. This work suggests that FL on text, which has historically been resistant to privacy attacks, is far more vulnerable than previously thought.
Execute Order 66: Targeted Data Poisoning for Reinforcement Learning
Jan 03, 2022
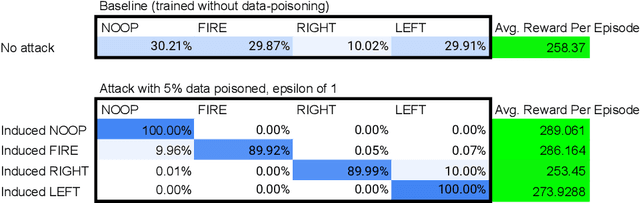

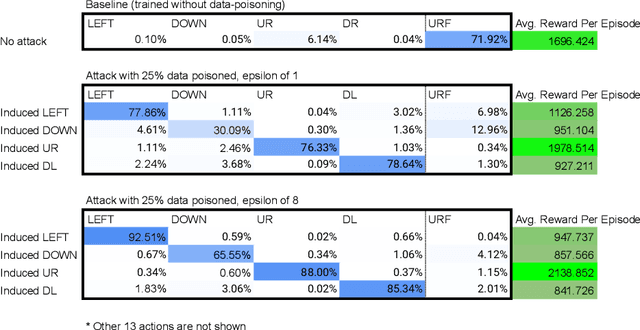
Data poisoning for reinforcement learning has historically focused on general performance degradation, and targeted attacks have been successful via perturbations that involve control of the victim's policy and rewards. We introduce an insidious poisoning attack for reinforcement learning which causes agent misbehavior only at specific target states - all while minimally modifying a small fraction of training observations without assuming any control over policy or reward. We accomplish this by adapting a recent technique, gradient alignment, to reinforcement learning. We test our method and demonstrate success in two Atari games of varying difficulty.
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models
Oct 25, 2021
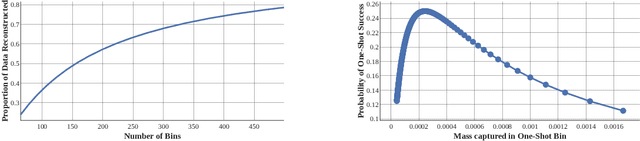


Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches -- where previous methods fail to extract meaningful content -- can be reconstructed by these minimally modified models.