Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecute Order 66: Targeted Data Poisoning for Reinforcement Learning
Paper and Code
Jan 03, 2022
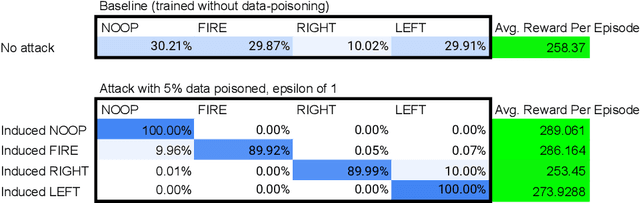

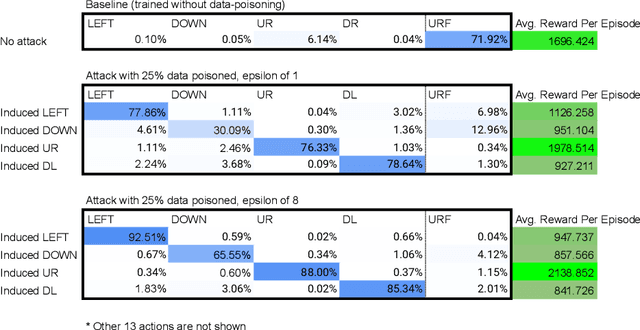
Data poisoning for reinforcement learning has historically focused on general performance degradation, and targeted attacks have been successful via perturbations that involve control of the victim's policy and rewards. We introduce an insidious poisoning attack for reinforcement learning which causes agent misbehavior only at specific target states - all while minimally modifying a small fraction of training observations without assuming any control over policy or reward. We accomplish this by adapting a recent technique, gradient alignment, to reinforcement learning. We test our method and demonstrate success in two Atari games of varying difficulty.
* Workshop on Safe and Robust Control of Uncertain Systems at the 35th
Conference on Neural Information Processing Systems
View paper on