 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecute Order 66: Targeted Data Poisoning for Reinforcement Learning
Jan 03, 2022
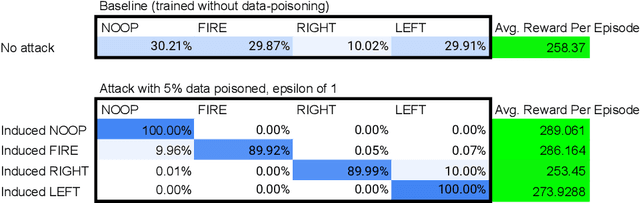

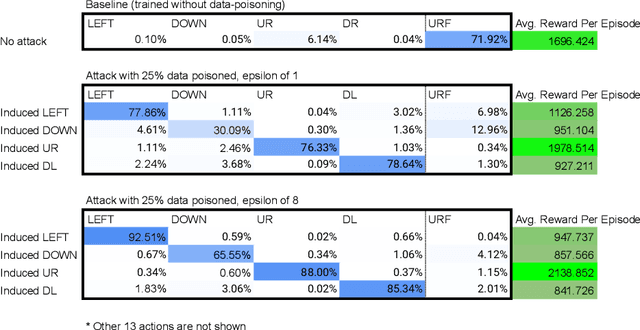
Data poisoning for reinforcement learning has historically focused on general performance degradation, and targeted attacks have been successful via perturbations that involve control of the victim's policy and rewards. We introduce an insidious poisoning attack for reinforcement learning which causes agent misbehavior only at specific target states - all while minimally modifying a small fraction of training observations without assuming any control over policy or reward. We accomplish this by adapting a recent technique, gradient alignment, to reinforcement learning. We test our method and demonstrate success in two Atari games of varying difficulty.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

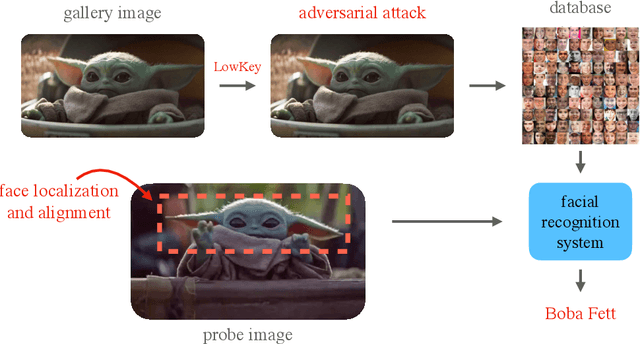
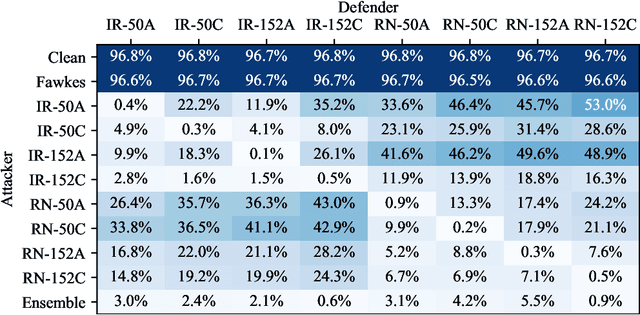
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.