 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Boost the Performance of Decision Trees on Tabular Data across Sample Sizes
Feb 06, 2025Large language models (LLMs) perform remarkably well on tabular datasets in zero- and few-shot settings, since they can extract meaning from natural language column headers that describe features and labels. Similarly, TabPFN, a recent non-LLM transformer pretrained on numerous tables for in-context learning, has demonstrated excellent performance for dataset sizes up to a thousand samples. In contrast, gradient-boosted decision trees (GBDTs) are typically trained from scratch on each dataset without benefiting from pretraining data and must learn the relationships between columns from their entries alone since they lack natural language understanding. LLMs and TabPFN excel on small tabular datasets where a strong prior is essential, yet they are not competitive with GBDTs on medium or large datasets, since their context lengths are limited. In this paper, we propose a simple and lightweight approach for fusing large language models and TabPFN with gradient-boosted decision trees, which allows scalable GBDTs to benefit from the natural language capabilities and pretraining of transformers. We name our fusion methods LLM-Boost and PFN-Boost, respectively. While matching or surpassing the performance of the transformer at sufficiently small dataset sizes and GBDTs at sufficiently large sizes, LLM-Boost and PFN-Boost outperform both standalone components on a wide range of dataset sizes in between. We demonstrate state-of-the-art performance against numerous baselines and ensembling algorithms. We find that PFN-Boost achieves the best average performance among all methods we test for all but very small dataset sizes. We release our code at http://github.com/MayukaJ/LLM-Boost .
Improving LLM Group Fairness on Tabular Data via In-Context Learning
Dec 05, 2024Large language models (LLMs) have been shown to be effective on tabular prediction tasks in the low-data regime, leveraging their internal knowledge and ability to learn from instructions and examples. However, LLMs can fail to generate predictions that satisfy group fairness, that is, produce equitable outcomes across groups. Critically, conventional debiasing approaches for natural language tasks do not directly translate to mitigating group unfairness in tabular settings. In this work, we systematically investigate four empirical approaches to improve group fairness of LLM predictions on tabular datasets, including fair prompt optimization, soft prompt tuning, strategic selection of few-shot examples, and self-refining predictions via chain-of-thought reasoning. Through experiments on four tabular datasets using both open-source and proprietary LLMs, we show the effectiveness of these methods in enhancing demographic parity while maintaining high overall performance. Our analysis provides actionable insights for practitioners in selecting the most suitable approach based on their specific requirements and constraints.
Talking Nonsense: Probing Large Language Models' Understanding of Adversarial Gibberish Inputs
Apr 29, 2024



Large language models (LLMs) exhibit excellent ability to understand human languages, but do they also understand their own language that appears gibberish to us? In this work we delve into this question, aiming to uncover the mechanisms underlying such behavior in LLMs. We employ the Greedy Coordinate Gradient optimizer to craft prompts that compel LLMs to generate coherent responses from seemingly nonsensical inputs. We call these inputs LM Babel and this work systematically studies the behavior of LLMs manipulated by these prompts. We find that the manipulation efficiency depends on the target text's length and perplexity, with the Babel prompts often located in lower loss minima compared to natural prompts. We further examine the structure of the Babel prompts and evaluate their robustness. Notably, we find that guiding the model to generate harmful texts is not more difficult than into generating benign texts, suggesting lack of alignment for out-of-distribution prompts.
TuneTables: Context Optimization for Scalable Prior-Data Fitted Networks
Feb 17, 2024



While tabular classification has traditionally relied on from-scratch training, a recent breakthrough called prior-data fitted networks (PFNs) challenges this approach. Similar to large language models, PFNs make use of pretraining and in-context learning to achieve strong performance on new tasks in a single forward pass. However, current PFNs have limitations that prohibit their widespread adoption. Notably, TabPFN achieves very strong performance on small tabular datasets but is not designed to make predictions for datasets of size larger than 1000. In this work, we overcome these limitations and substantially improve the performance of PFNs by developing context optimization techniques for PFNs. Specifically, we propose TuneTables, a novel prompt-tuning strategy that compresses large datasets into a smaller learned context. TuneTables scales TabPFN to be competitive with state-of-the-art tabular classification methods on larger datasets, while having a substantially lower inference time than TabPFN. Furthermore, we show that TuneTables can be used as an interpretability tool and can even be used to mitigate biases by optimizing a fairness objective.
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
Jan 22, 2024



Detecting text generated by modern large language models is thought to be hard, as both LLMs and humans can exhibit a wide range of complex behaviors. However, we find that a score based on contrasting two closely related language models is highly accurate at separating human-generated and machine-generated text. Based on this mechanism, we propose a novel LLM detector that only requires simple calculations using a pair of pre-trained LLMs. The method, called Binoculars, achieves state-of-the-art accuracy without any training data. It is capable of spotting machine text from a range of modern LLMs without any model-specific modifications. We comprehensively evaluate Binoculars on a number of text sources and in varied situations. Over a wide range of document types, Binoculars detects over 90% of generated samples from ChatGPT (and other LLMs) at a false positive rate of 0.01%, despite not being trained on any ChatGPT data.
A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
Nov 10, 2023



Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent overfitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. Motivated by the increasing popularity of tabular deep learning, we construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of Lasso for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
Transfer Learning with Deep Tabular Models
Jun 30, 2022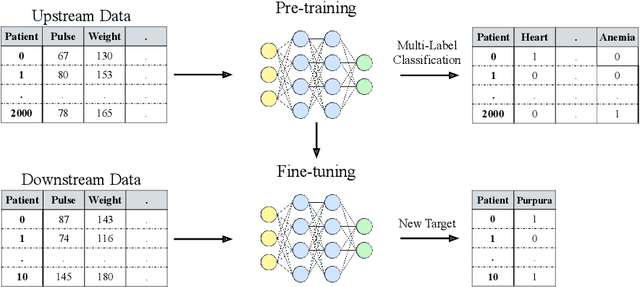

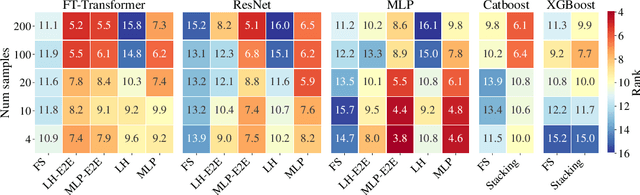

Recent work on deep learning for tabular data demonstrates the strong performance of deep tabular models, often bridging the gap between gradient boosted decision trees and neural networks. Accuracy aside, a major advantage of neural models is that they learn reusable features and are easily fine-tuned in new domains. This property is often exploited in computer vision and natural language applications, where transfer learning is indispensable when task-specific training data is scarce. In this work, we demonstrate that upstream data gives tabular neural networks a decisive advantage over widely used GBDT models. We propose a realistic medical diagnosis benchmark for tabular transfer learning, and we present a how-to guide for using upstream data to boost performance with a variety of tabular neural network architectures. Finally, we propose a pseudo-feature method for cases where the upstream and downstream feature sets differ, a tabular-specific problem widespread in real-world applications. Our code is available at https://github.com/LevinRoman/tabular-transfer-learning .
A Deep Dive into Dataset Imbalance and Bias in Face Identification
Mar 15, 2022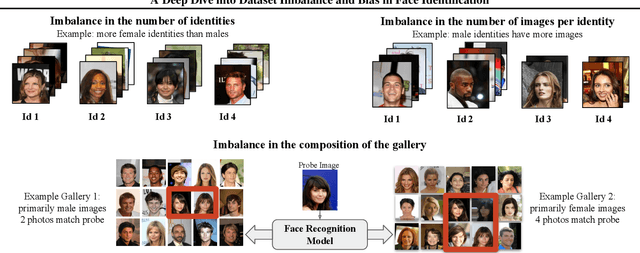



As the deployment of automated face recognition (FR) systems proliferates, bias in these systems is not just an academic question, but a matter of public concern. Media portrayals often center imbalance as the main source of bias, i.e., that FR models perform worse on images of non-white people or women because these demographic groups are underrepresented in training data. Recent academic research paints a more nuanced picture of this relationship. However, previous studies of data imbalance in FR have focused exclusively on the face verification setting, while the face identification setting has been largely ignored, despite being deployed in sensitive applications such as law enforcement. This is an unfortunate omission, as 'imbalance' is a more complex matter in identification; imbalance may arise in not only the training data, but also the testing data, and furthermore may affect the proportion of identities belonging to each demographic group or the number of images belonging to each identity. In this work, we address this gap in the research by thoroughly exploring the effects of each kind of imbalance possible in face identification, and discuss other factors which may impact bias in this setting.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021
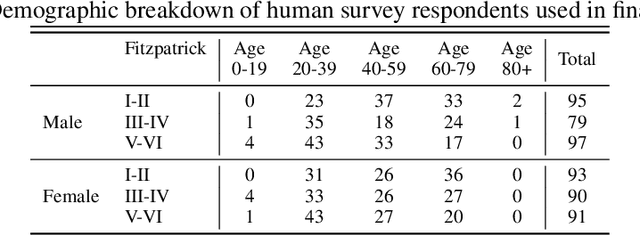

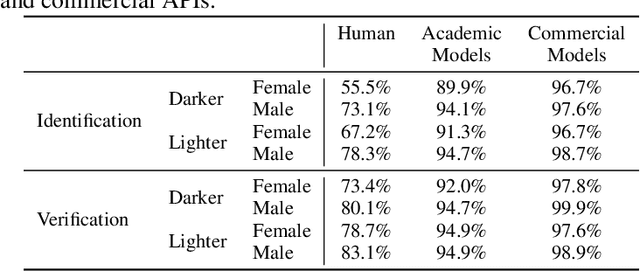
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.
MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data
Jun 17, 2021
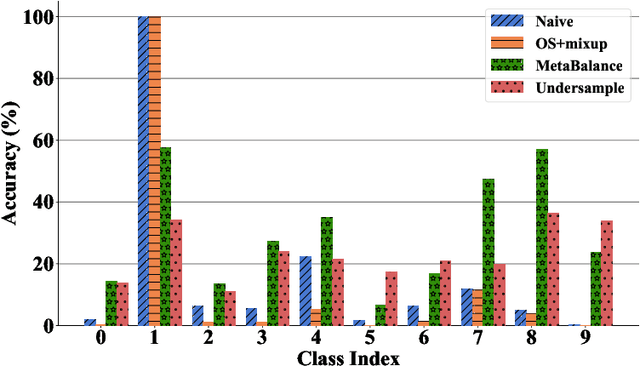
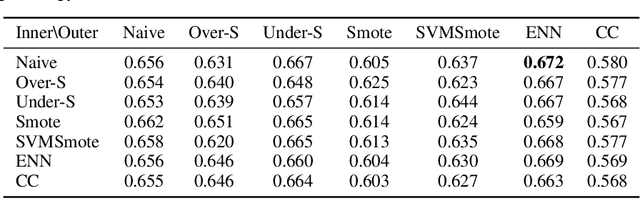
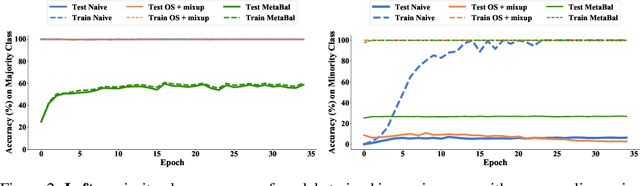
Class-imbalanced data, in which some classes contain far more samples than others, is ubiquitous in real-world applications. Standard techniques for handling class-imbalance usually work by training on a re-weighted loss or on re-balanced data. Unfortunately, training overparameterized neural networks on such objectives causes rapid memorization of minority class data. To avoid this trap, we harness meta-learning, which uses both an ''outer-loop'' and an ''inner-loop'' loss, each of which may be balanced using different strategies. We evaluate our method, MetaBalance, on image classification, credit-card fraud detection, loan default prediction, and facial recognition tasks with severely imbalanced data, and we find that MetaBalance outperforms a wide array of popular re-sampling strategies.