 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Hierarchical Optimization with Large Language Models
Jan 20, 2026Despite their widespread adoption in various domains, especially due to their powerful reasoning capabilities, Large Language Models (LLMs) are not the off-the-shelf choice to drive multi-objective optimization yet. Conventional strategies rank high in benchmarks due to their intrinsic capabilities to handle numerical inputs and careful modelling choices that balance exploration and Pareto-front exploitation, as well as handle multiple (conflicting) objectives. In this paper, we close this gap by leveraging LLMs as surrogate models and candidate samplers inside a structured hierarchical search strategy. By adaptively partitioning the input space into disjoint hyperrectangular regions and ranking them with a composite score function, we restrict the generative process of the LLM to specific, high-potential sub-spaces, hence making the problem easier to solve as the LLM doesn't have to reason about the global structure of the problem, but only locally instead. We show that under standard regularity assumptions, our algorithm generates candidate solutions that converge to the true Pareto set in Hausdorff distance. Empirically, it consistently outperforms the global LLM-based multi-objective optimizer and is on par with standard evolutionary and Bayesian optimization algorithm on synthetic and real-world benchmarks.
Causal Data Augmentation for Robust Fine-Tuning of Tabular Foundation Models
Jan 07, 2026Fine-tuning tabular foundation models (TFMs) under data scarcity is challenging, as early stopping on even scarcer validation data often fails to capture true generalization performance. We propose CausalMixFT, a method that enhances fine-tuning robustness and downstream performance by generating structurally consistent synthetic samples using Structural Causal Models (SCMs) fitted on the target dataset. This approach augments limited real data with causally informed synthetic examples, preserving feature dependencies while expanding training diversity. Evaluated across 33 classification datasets from TabArena and over 2300 fine-tuning runs, our CausalMixFT method consistently improves median normalized ROC-AUC from 0.10 (standard fine-tuning) to 0.12, outperforming purely statistical generators such as CTGAN (-0.01), TabEBM (-0.04), and TableAugment (-0.09). Moreover, it narrows the median validation-test performance correlation gap from 0.67 to 0.30, enabling more reliable validation-based early stopping, a key step toward improving fine-tuning stability under data scarcity. These results demonstrate that incorporating causal structure into data augmentation provides an effective and principled route to fine-tuning tabular foundation models in low-data regimes.
Generalization Can Emerge in Tabular Foundation Models From a Single Table
Nov 12, 2025



Deep tabular modelling increasingly relies on in-context learning where, during inference, a model receives a set of $(x,y)$ pairs as context and predicts labels for new inputs without weight updates. We challenge the prevailing view that broad generalization here requires pre-training on large synthetic corpora (e.g., TabPFN priors) or a large collection of real data (e.g., TabDPT training datasets), discovering that a relatively small amount of data suffices for generalization. We find that simple self-supervised pre-training on just a \emph{single} real table can produce surprisingly strong transfer across heterogeneous benchmarks. By systematically pre-training and evaluating on many diverse datasets, we analyze what aspects of the data are most important for building a Tabular Foundation Model (TFM) generalizing across domains. We then connect this to the pre-training procedure shared by most TFMs and show that the number and quality of \emph{tasks} one can construct from a dataset is key to downstream performance.
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025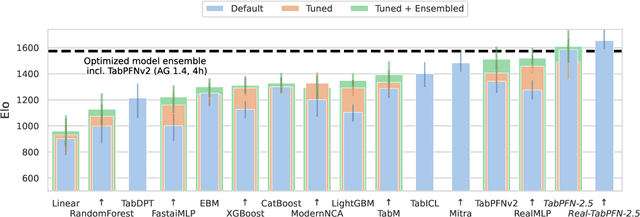
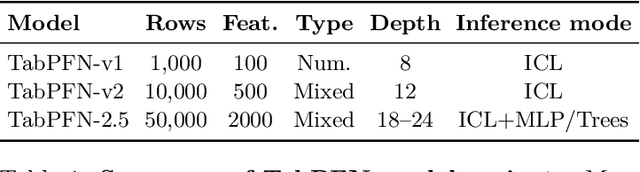
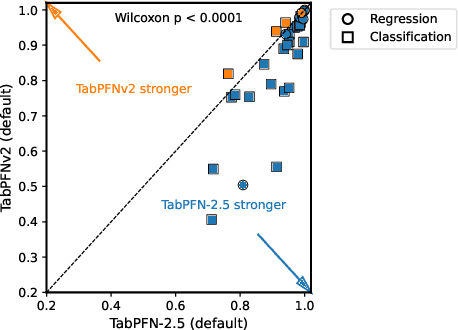
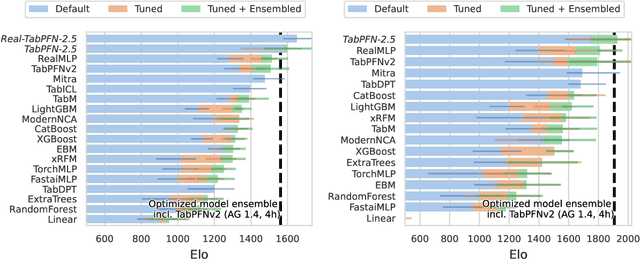
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Does TabPFN Understand Causal Structures?
Nov 10, 2025Causal discovery is fundamental for multiple scientific domains, yet extracting causal information from real world data remains a significant challenge. Given the recent success on real data, we investigate whether TabPFN, a transformer-based tabular foundation model pre-trained on synthetic datasets generated from structural causal models, encodes causal information in its internal representations. We develop an adapter framework using a learnable decoder and causal tokens that extract causal signals from TabPFN's frozen embeddings and decode them into adjacency matrices for causal discovery. Our evaluations demonstrate that TabPFN's embeddings contain causal information, outperforming several traditional causal discovery algorithms, with such causal information being concentrated in mid-range layers. These findings establish a new direction for interpretable and adaptable foundation models and demonstrate the potential for leveraging pre-trained tabular models for causal discovery.
nanoTabPFN: A Lightweight and Educational Reimplementation of TabPFN
Nov 05, 2025Tabular foundation models such as TabPFN have revolutionized predictive machine learning for tabular data. At the same time, the driving factors of this revolution are hard to understand. Existing open-source tabular foundation models are implemented in complicated pipelines boasting over 10,000 lines of code, lack architecture documentation or code quality. In short, the implementations are hard to understand, not beginner-friendly, and complicated to adapt for new experiments. We introduce nanoTabPFN, a simplified and lightweight implementation of the TabPFN v2 architecture and a corresponding training loop that uses pre-generated training data. nanoTabPFN makes tabular foundation models more accessible to students and researchers alike. For example, restricted to a small data setting it achieves a performance comparable to traditional machine learning baselines within one minute of pre-training on a single GPU (160,000x faster than TabPFN v2 pretraining). This eliminated requirement of large computational resources makes pre-training tabular foundation models accessible for educational purposes. Our code is available at https://github.com/automl/nanoTabPFN.
Towards Scaling Laws for Symbolic Regression
Oct 30, 2025



Symbolic regression (SR) aims to discover the underlying mathematical expressions that explain observed data. This holds promise for both gaining scientific insight and for producing inherently interpretable and generalizable models for tabular data. In this work we focus on the basics of SR. Deep learning-based SR has recently become competitive with genetic programming approaches, but the role of scale has remained largely unexplored. Inspired by scaling laws in language modeling, we present the first systematic investigation of scaling in SR, using a scalable end-to-end transformer pipeline and carefully generated training data. Across five different model sizes and spanning three orders of magnitude in compute, we find that both validation loss and solved rate follow clear power-law trends with compute. We further identify compute-optimal hyperparameter scaling: optimal batch size and learning rate grow with model size, and a token-to-parameter ratio of $\approx$15 is optimal in our regime, with a slight upward trend as compute increases. These results demonstrate that SR performance is largely predictable from compute and offer important insights for training the next generation of SR models.
Where to Begin: Efficient Pretraining via Subnetwork Selection and Distillation
Oct 08, 2025Small Language models (SLMs) offer an efficient and accessible alternative to Large Language Models (LLMs), delivering strong performance while using far fewer resources. We introduce a simple and effective framework for pretraining SLMs that brings together three complementary ideas. First, we identify structurally sparse sub-network initializations that consistently outperform randomly initialized models of similar size under the same compute budget. Second, we use evolutionary search to automatically discover high-quality sub-network initializations, providing better starting points for pretraining. Third, we apply knowledge distillation from larger teacher models to speed up training and improve generalization. Together, these components make SLM pretraining substantially more efficient: our best model, discovered using evolutionary search and initialized with LLM weights, matches the validation perplexity of a comparable Pythia SLM while requiring 9.2x fewer pretraining tokens. We release all code and models at https://github.com/whittle-org/whittle/, offering a practical and reproducible path toward cost-efficient small language model development at scale.
Tune My Adam, Please!
Aug 28, 2025The Adam optimizer remains one of the most widely used optimizers in deep learning, and effectively tuning its hyperparameters is key to optimizing performance. However, tuning can be tedious and costly. Freeze-thaw Bayesian Optimization (BO) is a recent promising approach for low-budget hyperparameter tuning, but is limited by generic surrogates without prior knowledge of how hyperparameters affect learning. We propose Adam-PFN, a new surrogate model for Freeze-thaw BO of Adam's hyperparameters, pre-trained on learning curves from TaskSet, together with a new learning curve augmentation method, CDF-augment, which artificially increases the number of available training examples. Our approach improves both learning curve extrapolation and accelerates hyperparameter optimization on TaskSet evaluation tasks, with strong performance on out-of-distribution (OOD) tasks.
Quickly Tuning Foundation Models for Image Segmentation
Aug 24, 2025Foundation models like SAM (Segment Anything Model) exhibit strong zero-shot image segmentation performance, but often fall short on domain-specific tasks. Fine-tuning these models typically requires significant manual effort and domain expertise. In this work, we introduce QTT-SEG, a meta-learning-driven approach for automating and accelerating the fine-tuning of SAM for image segmentation. Built on the Quick-Tune hyperparameter optimization framework, QTT-SEG predicts high-performing configurations using meta-learned cost and performance models, efficiently navigating a search space of over 200 million possibilities. We evaluate QTT-SEG on eight binary and five multiclass segmentation datasets under tight time constraints. Our results show that QTT-SEG consistently improves upon SAM's zero-shot performance and surpasses AutoGluon Multimodal, a strong AutoML baseline, on most binary tasks within three minutes. On multiclass datasets, QTT-SEG delivers consistent gains as well. These findings highlight the promise of meta-learning in automating model adaptation for specialized segmentation tasks. Code available at: https://github.com/ds-brx/QTT-SEG/