 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarmstarting for Scaling Language Models
Nov 11, 2024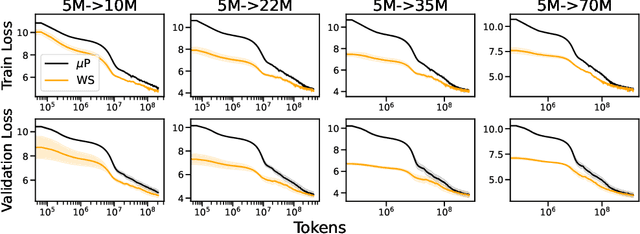
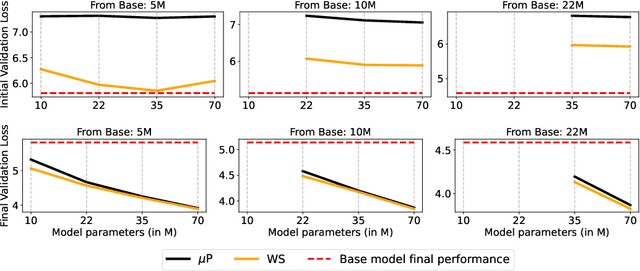
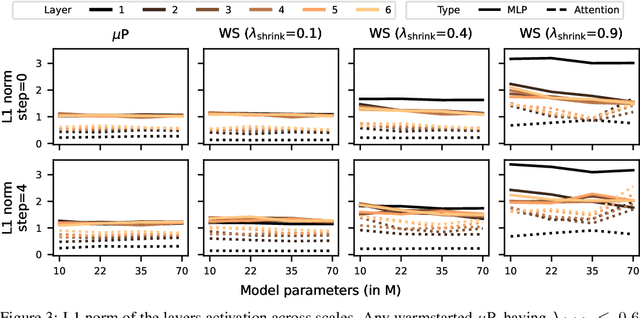
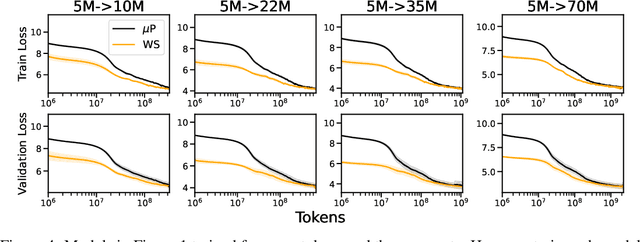
Scaling model sizes to scale performance has worked remarkably well for the current large language models paradigm. The research and empirical findings of various scaling studies led to novel scaling results and laws that guides subsequent research. High training costs for contemporary scales of data and models result in a lack of thorough understanding of how to tune and arrive at such training setups. One direction to ameliorate the cost of pretraining large models is to warmstart the large-scale training from smaller models that are cheaper to tune. In this work, we attempt to understand if the behavior of optimal hyperparameters can be retained under warmstarting for scaling. We explore simple operations that allow the application of theoretically motivated methods of zero-shot transfer of optimal hyperparameters using {\mu}Transfer. We investigate the aspects that contribute to the speedup in convergence and the preservation of stable training dynamics under warmstarting with {\mu}Transfer. We find that shrinking smaller model weights, zero-padding, and perturbing the resulting larger model with scaled initialization from {\mu}P enables effective warmstarting of $\mut{}$.
Ensembling Finetuned Language Models for Text Classification
Oct 25, 2024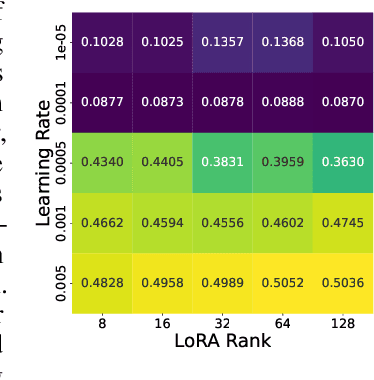

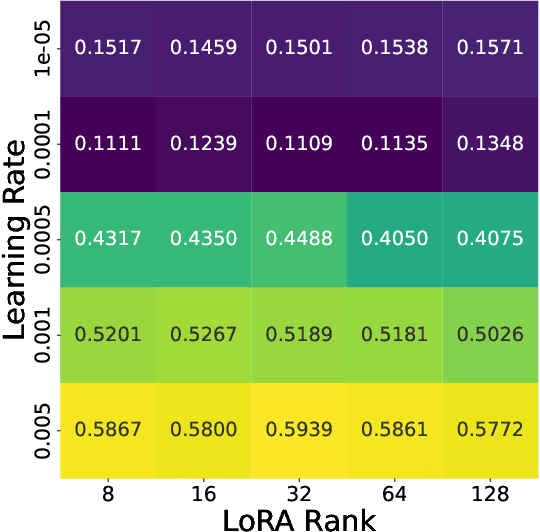
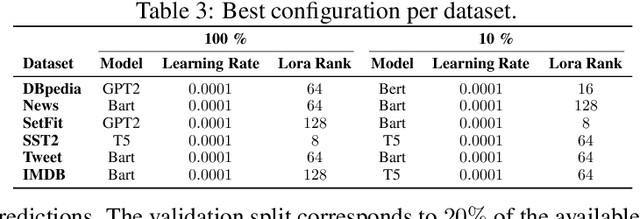
Finetuning is a common practice widespread across different communities to adapt pretrained models to particular tasks. Text classification is one of these tasks for which many pretrained models are available. On the other hand, ensembles of neural networks are typically used to boost performance and provide reliable uncertainty estimates. However, ensembling pretrained models for text classification is not a well-studied avenue. In this paper, we present a metadataset with predictions from five large finetuned models on six datasets, and report results of different ensembling strategies from these predictions. Our results shed light on how ensembling can improve the performance of finetuned text classifiers and incentivize future adoption of ensembles in such tasks.
Dynamic Post-Hoc Neural Ensemblers
Oct 06, 2024



Ensemble methods are known for enhancing the accuracy and robustness of machine learning models by combining multiple base learners. However, standard approaches like greedy or random ensembles often fall short, as they assume a constant weight across samples for the ensemble members. This can limit expressiveness and hinder performance when aggregating the ensemble predictions. In this study, we explore employing neural networks as ensemble methods, emphasizing the significance of dynamic ensembling to leverage diverse model predictions adaptively. Motivated by the risk of learning low-diversity ensembles, we propose regularizing the model by randomly dropping base model predictions during the training. We demonstrate this approach lower bounds the diversity within the ensemble, reducing overfitting and improving generalization capabilities. Our experiments showcase that the dynamic neural ensemblers yield competitive results compared to strong baselines in computer vision, natural language processing, and tabular data.
PriorBand: Practical Hyperparameter Optimization in the Age of Deep Learning
Jun 21, 2023
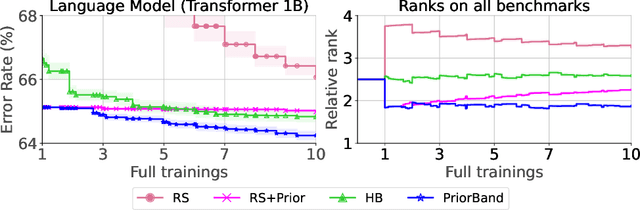


Hyperparameters of Deep Learning (DL) pipelines are crucial for their downstream performance. While a large number of methods for Hyperparameter Optimization (HPO) have been developed, their incurred costs are often untenable for modern DL. Consequently, manual experimentation is still the most prevalent approach to optimize hyperparameters, relying on the researcher's intuition, domain knowledge, and cheap preliminary explorations. To resolve this misalignment between HPO algorithms and DL researchers, we propose PriorBand, an HPO algorithm tailored to DL, able to utilize both expert beliefs and cheap proxy tasks. Empirically, we demonstrate PriorBand's efficiency across a range of DL benchmarks and show its gains under informative expert input and robustness against poor expert beliefs
Deep Power Laws for Hyperparameter Optimization
Feb 01, 2023Hyperparameter optimization is an important subfield of machine learning that focuses on tuning the hyperparameters of a chosen algorithm to achieve peak performance. Recently, there has been a stream of methods that tackle the issue of hyperparameter optimization, however, most of the methods do not exploit the scaling law property of learning curves. In this work, we propose Deep Power Laws (DPL), an ensemble of neural network models conditioned to yield predictions that follow a power-law scaling pattern. Our method dynamically decides which configurations to pause and train incrementally by making use of gray-box evaluations. We compare our method against 7 state-of-the-art competitors on 3 benchmarks related to tabular, image, and NLP datasets covering 57 diverse tasks. Our method achieves the best results across all benchmarks by obtaining the best any-time results compared to all competitors.