 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecarps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025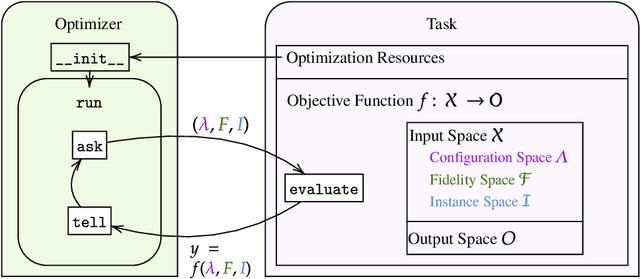

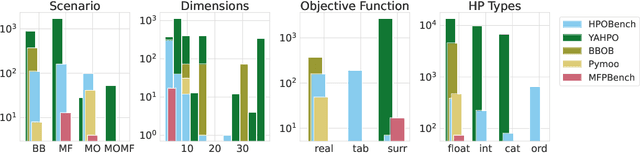
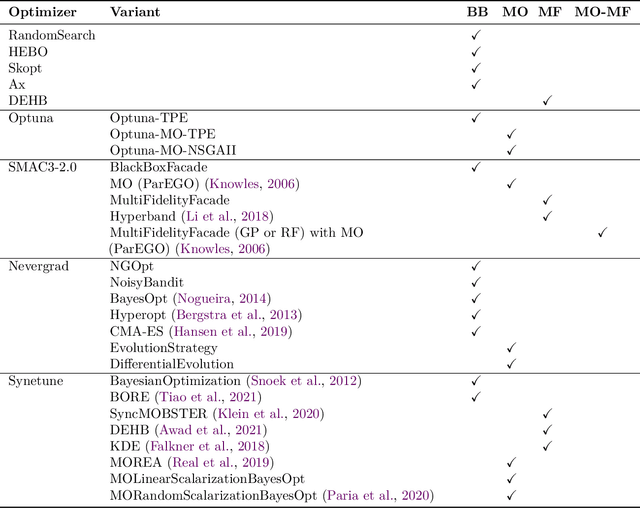
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Don't Waste Your Time: Early Stopping Cross-Validation
May 06, 2024


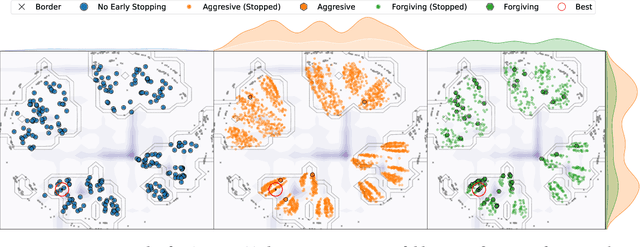
State-of-the-art automated machine learning systems for tabular data often employ cross-validation; ensuring that measured performances generalize to unseen data, or that subsequent ensembling does not overfit. However, using k-fold cross-validation instead of holdout validation drastically increases the computational cost of validating a single configuration. While ensuring better generalization and, by extension, better performance, the additional cost is often prohibitive for effective model selection within a time budget. We aim to make model selection with cross-validation more effective. Therefore, we study early stopping the process of cross-validation during model selection. We investigate the impact of early stopping on random search for two algorithms, MLP and random forest, across 36 classification datasets. We further analyze the impact of the number of folds by considering 3-, 5-, and 10-folds. In addition, we investigate the impact of early stopping with Bayesian optimization instead of random search and also repeated cross-validation. Our exploratory study shows that even a simple-to-understand and easy-to-implement method consistently allows model selection to converge faster; in ~94% of all datasets, on average by ~214%. Moreover, stopping cross-validation enables model selection to explore the search space more exhaustively by considering +167% configurations on average within one hour, while also obtaining better overall performance.
In-Context Freeze-Thaw Bayesian Optimization for Hyperparameter Optimization
Apr 25, 2024



With the increasing computational costs associated with deep learning, automated hyperparameter optimization methods, strongly relying on black-box Bayesian optimization (BO), face limitations. Freeze-thaw BO offers a promising grey-box alternative, strategically allocating scarce resources incrementally to different configurations. However, the frequent surrogate model updates inherent to this approach pose challenges for existing methods, requiring retraining or fine-tuning their neural network surrogates online, introducing overhead, instability, and hyper-hyperparameters. In this work, we propose FT-PFN, a novel surrogate for Freeze-thaw style BO. FT-PFN is a prior-data fitted network (PFN) that leverages the transformers' in-context learning ability to efficiently and reliably do Bayesian learning curve extrapolation in a single forward pass. Our empirical analysis across three benchmark suites shows that the predictions made by FT-PFN are more accurate and 10-100 times faster than those of the deep Gaussian process and deep ensemble surrogates used in previous work. Furthermore, we show that, when combined with our novel acquisition mechanism (MFPI-random), the resulting in-context freeze-thaw BO method (ifBO), yields new state-of-the-art performance in the same three families of deep learning HPO benchmarks considered in prior work.
Fast Benchmarking of Asynchronous Multi-Fidelity Optimization on Zero-Cost Benchmarks
Mar 04, 2024While deep learning has celebrated many successes, its results often hinge on the meticulous selection of hyperparameters (HPs). However, the time-consuming nature of deep learning training makes HP optimization (HPO) a costly endeavor, slowing down the development of efficient HPO tools. While zero-cost benchmarks, which provide performance and runtime without actual training, offer a solution for non-parallel setups, they fall short in parallel setups as each worker must communicate its queried runtime to return its evaluation in the exact order. This work addresses this challenge by introducing a user-friendly Python package that facilitates efficient parallel HPO with zero-cost benchmarks. Our approach calculates the exact return order based on the information stored in file system, eliminating the need for long waiting times and enabling much faster HPO evaluations. We first verify the correctness of our approach through extensive testing and the experiments with 6 popular HPO libraries show its applicability to diverse libraries and its ability to achieve over 1000x speedup compared to a traditional approach. Our package can be installed via pip install mfhpo-simulator.
PriorBand: Practical Hyperparameter Optimization in the Age of Deep Learning
Jun 21, 2023
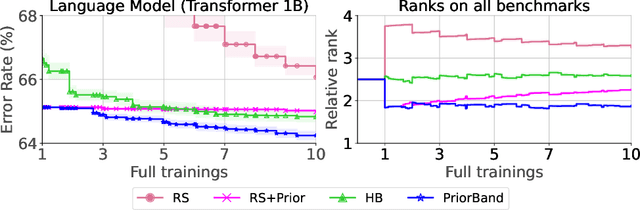


Hyperparameters of Deep Learning (DL) pipelines are crucial for their downstream performance. While a large number of methods for Hyperparameter Optimization (HPO) have been developed, their incurred costs are often untenable for modern DL. Consequently, manual experimentation is still the most prevalent approach to optimize hyperparameters, relying on the researcher's intuition, domain knowledge, and cheap preliminary explorations. To resolve this misalignment between HPO algorithms and DL researchers, we propose PriorBand, an HPO algorithm tailored to DL, able to utilize both expert beliefs and cheap proxy tasks. Empirically, we demonstrate PriorBand's efficiency across a range of DL benchmarks and show its gains under informative expert input and robustness against poor expert beliefs
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Mind the Gap: Measuring Generalization Performance Across Multiple Objectives
Dec 08, 2022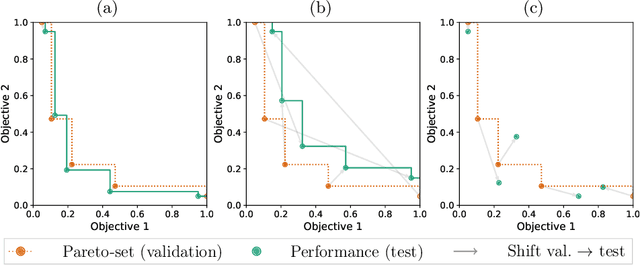
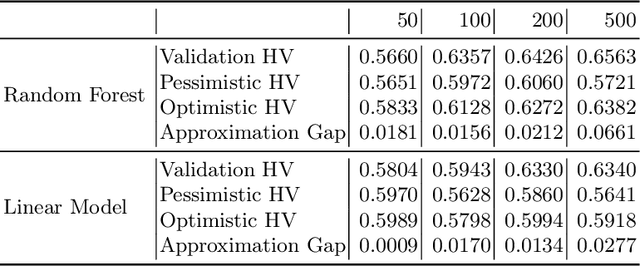
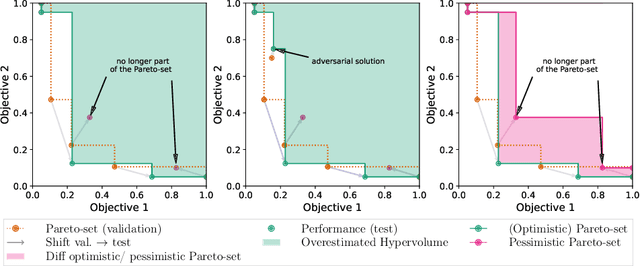
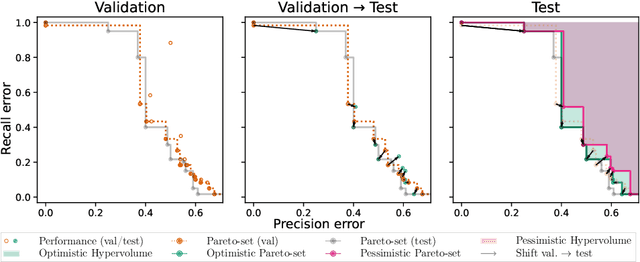
Modern machine learning models are often constructed taking into account multiple objectives, e.g., to minimize inference time while also maximizing accuracy. Multi-objective hyperparameter optimization (MHPO) algorithms return such candidate models and the approximation of the Pareto front is used to assess their performance. However, when estimating generalization performance of an approximation of a Pareto front found on a validation set by computing the performance of the individual models on the test set, models might no longer be Pareto-optimal. This makes it unclear how to measure performance. To resolve this, we provide a novel evaluation protocol that allows measuring the generalization performance of MHPO methods and to study its capabilities for comparing two optimization experiments.
Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]
Jun 23, 2020![Figure 1 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F3-Figure3-1.png&w=640&q=75)
![Figure 4 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F4-Figure4-1.png&w=640&q=75)
Automated per-instance algorithm selection often outperforms single learners. Key to algorithm selection via meta-learning is often the (meta) features, which sometimes though do not provide enough information to train a meta-learner effectively. We propose a Siamese Neural Network architecture for automated algorithm selection that focuses more on 'alike performing' instances than meta-features. Our work includes a novel performance metric and method for selecting training samples. We introduce further the concept of 'Algorithm Performance Personas' that describe instances for which the single algorithms perform alike. The concept of 'alike performing algorithms' as ground truth for selecting training samples is novel and provides a huge potential as we believe. In this proposal, we outline our ideas in detail and provide the first evidence that our proposed metric is better suitable for training sample selection that standard performance metrics such as absolute errors.