 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairPFN: A Tabular Foundation Model for Causal Fairness
Jun 08, 2025Machine learning (ML) systems are utilized in critical sectors, such as healthcare, law enforcement, and finance. However, these systems are often trained on historical data that contains demographic biases, leading to ML decisions that perpetuate or exacerbate existing social inequalities. Causal fairness provides a transparent, human-in-the-loop framework to mitigate algorithmic discrimination, aligning closely with legal doctrines of direct and indirect discrimination. However, current causal fairness frameworks hold a key limitation in that they assume prior knowledge of the correct causal model, restricting their applicability in complex fairness scenarios where causal models are unknown or difficult to identify. To bridge this gap, we propose FairPFN, a tabular foundation model pre-trained on synthetic causal fairness data to identify and mitigate the causal effects of protected attributes in its predictions. FairPFN's key contribution is that it requires no knowledge of the causal model and still demonstrates strong performance in identifying and removing protected causal effects across a diverse set of hand-crafted and real-world scenarios relative to robust baseline methods. FairPFN paves the way for promising future research, making causal fairness more accessible to a wider variety of complex fairness problems.
A Llama walks into the 'Bar': Efficient Supervised Fine-Tuning for Legal Reasoning in the Multi-state Bar Exam
Apr 07, 2025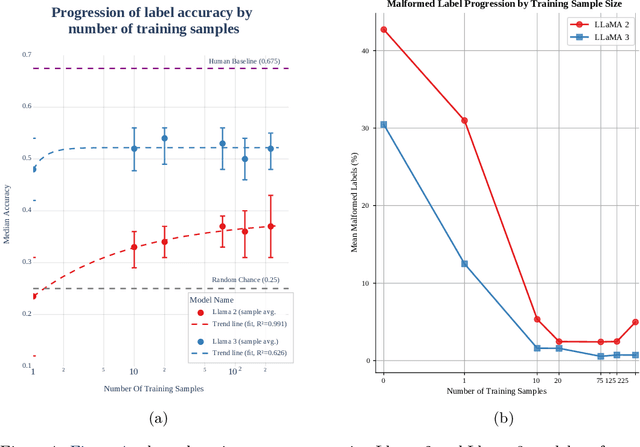
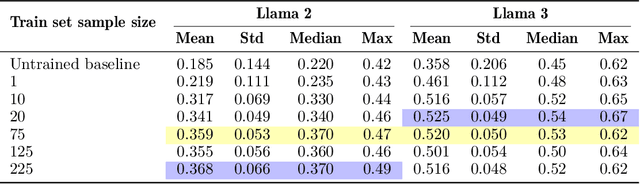
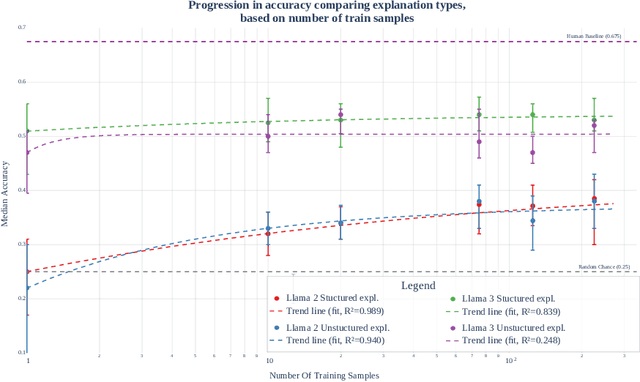
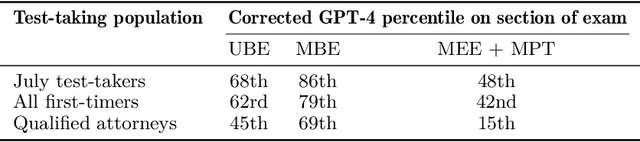
Legal reasoning tasks present unique challenges for large language models (LLMs) due to the complexity of domain-specific knowledge and reasoning processes. This paper investigates how effectively smaller language models (Llama 2 7B and Llama 3 8B) can be fine-tuned with a limited dataset of 1,514 Multi-state Bar Examination (MBE) questions to improve legal question answering accuracy. We evaluate these models on the 2022 MBE questions licensed from JD Advising, the same dataset used in the 'GPT-4 passes the Bar exam' study. Our methodology involves collecting approximately 200 questions per legal domain across 7 domains. We distill the dataset using Llama 3 (70B) to transform explanations into a structured IRAC (Issue, Rule, Application, Conclusion) format as a guided reasoning process to see if it results in better performance over the non-distilled dataset. We compare the non-fine-tuned models against their supervised fine-tuned (SFT) counterparts, trained for different sample sizes per domain, to study the effect on accuracy and prompt adherence. We also analyse option selection biases and their mitigation following SFT. In addition, we consolidate the performance across multiple variables: prompt type (few-shot vs zero-shot), answer ordering (chosen-option first vs generated-explanation first), response format (Numbered list vs Markdown vs JSON), and different decoding temperatures. Our findings show that domain-specific SFT helps some model configurations achieve close to human baseline performance, despite limited computational resources and a relatively small dataset. We release both the gathered SFT dataset and the family of Supervised Fine-tuned (SFT) adapters optimised for MBE performance. This establishes a practical lower bound on resources needed towards achieving effective legal question answering in smaller LLMs.
A Human-in-the-Loop Fairness-Aware Model Selection Framework for Complex Fairness Objective Landscapes
Oct 17, 2024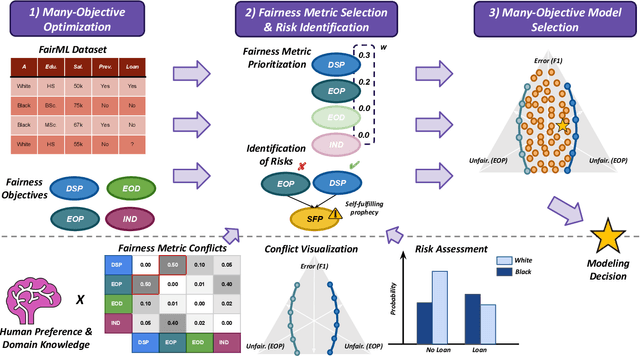
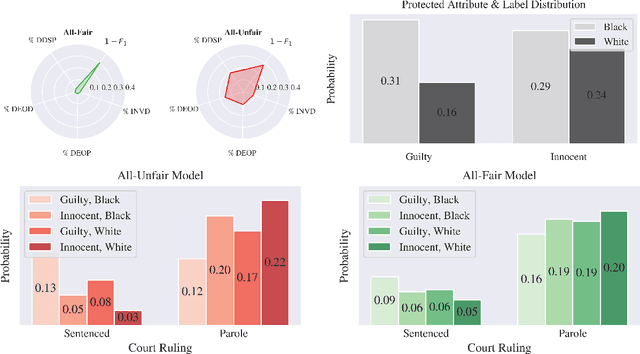

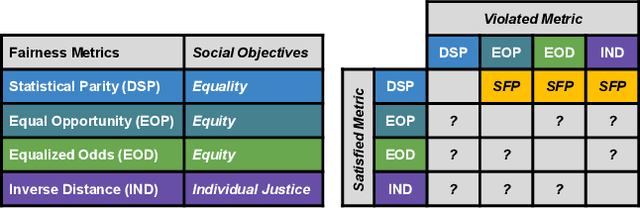
Fairness-aware Machine Learning (FairML) applications are often characterized by complex social objectives and legal requirements, frequently involving multiple, potentially conflicting notions of fairness. Despite the well-known Impossibility Theorem of Fairness and extensive theoretical research on the statistical and socio-technical trade-offs between fairness metrics, many FairML tools still optimize or constrain for a single fairness objective. However, this one-sided optimization can inadvertently lead to violations of other relevant notions of fairness. In this socio-technical and empirical study, we frame fairness as a many-objective (MaO) problem by treating fairness metrics as conflicting objectives. We introduce ManyFairHPO, a human-in-the-loop, fairness-aware model selection framework that enables practitioners to effectively navigate complex and nuanced fairness objective landscapes. ManyFairHPO aids in the identification, evaluation, and balancing of fairness metric conflicts and their related social consequences, leading to more informed and socially responsible model-selection decisions. Through a comprehensive empirical evaluation and a case study on the Law School Admissions problem, we demonstrate the effectiveness of ManyFairHPO in balancing multiple fairness objectives, mitigating risks such as self-fulfilling prophecies, and providing interpretable insights to guide stakeholders in making fairness-aware modeling decisions.
CANDID DAC: Leveraging Coupled Action Dimensions with Importance Differences in DAC
Jul 08, 2024



High-dimensional action spaces remain a challenge for dynamic algorithm configuration (DAC). Interdependencies and varying importance between action dimensions are further known key characteristics of DAC problems. We argue that these Coupled Action Dimensions with Importance Differences (CANDID) represent aspects of the DAC problem that are not yet fully explored. To address this gap, we introduce a new white-box benchmark within the DACBench suite that simulates the properties of CANDID. Further, we propose sequential policies as an effective strategy for managing these properties. Such policies factorize the action space and mitigate exponential growth by learning a policy per action dimension. At the same time, these policies accommodate the interdependence of action dimensions by fostering implicit coordination. We show this in an experimental study of value-based policies on our new benchmark. This study demonstrates that sequential policies significantly outperform independent learning of factorized policies in CANDID action spaces. In addition, they overcome the scalability limitations associated with learning a single policy across all action dimensions. The code used for our experiments is available under https://github.com/PhilippBordne/candidDAC.
FairPFN: Transformers Can do Counterfactual Fairness
Jul 08, 2024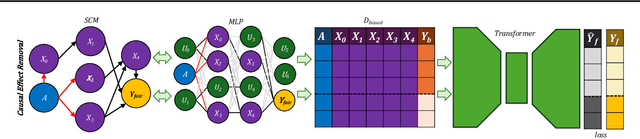
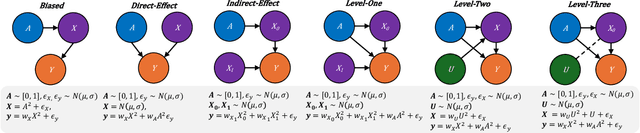
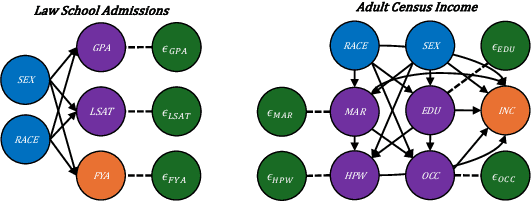
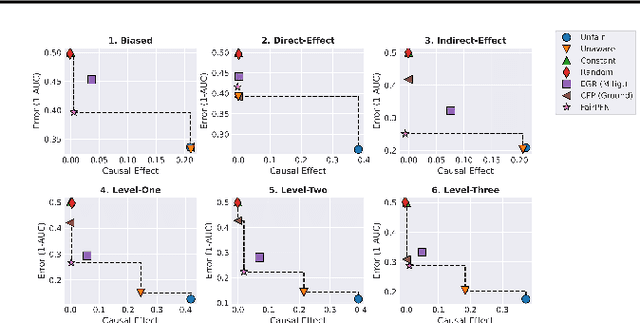
Machine Learning systems are increasingly prevalent across healthcare, law enforcement, and finance but often operate on historical data, which may carry biases against certain demographic groups. Causal and counterfactual fairness provides an intuitive way to define fairness that closely aligns with legal standards. Despite its theoretical benefits, counterfactual fairness comes with several practical limitations, largely related to the reliance on domain knowledge and approximate causal discovery techniques in constructing a causal model. In this study, we take a fresh perspective on counterfactually fair prediction, building upon recent work in in context learning (ICL) and prior fitted networks (PFNs) to learn a transformer called FairPFN. This model is pretrained using synthetic fairness data to eliminate the causal effects of protected attributes directly from observational data, removing the requirement of access to the correct causal model in practice. In our experiments, we thoroughly assess the effectiveness of FairPFN in eliminating the causal impact of protected attributes on a series of synthetic case studies and real world datasets. Our findings pave the way for a new and promising research area: transformers for causal and counterfactual fairness.
Inferring Behavior-Specific Context Improves Zero-Shot Generalization in Reinforcement Learning
Apr 15, 2024In this work, we address the challenge of zero-shot generalization (ZSG) in Reinforcement Learning (RL), where agents must adapt to entirely novel environments without additional training. We argue that understanding and utilizing contextual cues, such as the gravity level of the environment, is critical for robust generalization, and we propose to integrate the learning of context representations directly with policy learning. Our algorithm demonstrates improved generalization on various simulated domains, outperforming prior context-learning techniques in zero-shot settings. By jointly learning policy and context, our method acquires behavior-specific context representations, enabling adaptation to unseen environments and marks progress towards reinforcement learning systems that generalize across diverse real-world tasks. Our code and experiments are available at https://github.com/tidiane-camaret/contextual_rl_zero_shot.
MO-DEHB: Evolutionary-based Hyperband for Multi-Objective Optimization
May 11, 2023Hyperparameter optimization (HPO) is a powerful technique for automating the tuning of machine learning (ML) models. However, in many real-world applications, accuracy is only one of multiple performance criteria that must be considered. Optimizing these objectives simultaneously on a complex and diverse search space remains a challenging task. In this paper, we propose MO-DEHB, an effective and flexible multi-objective (MO) optimizer that extends the recent evolutionary Hyperband method DEHB. We validate the performance of MO-DEHB using a comprehensive suite of 15 benchmarks consisting of diverse and challenging MO problems, including HPO, neural architecture search (NAS), and joint NAS and HPO, with objectives including accuracy, latency and algorithmic fairness. A comparative study against state-of-the-art MO optimizers demonstrates that MO-DEHB clearly achieves the best performance across our 15 benchmarks.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Automated Dynamic Algorithm Configuration
May 27, 2022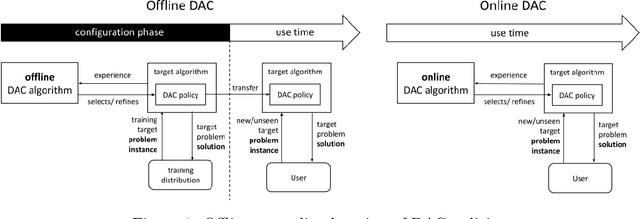

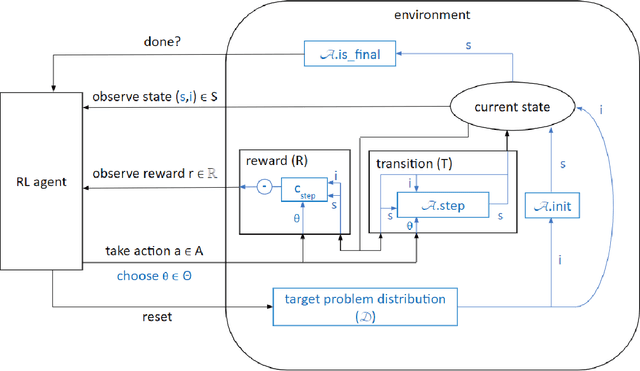
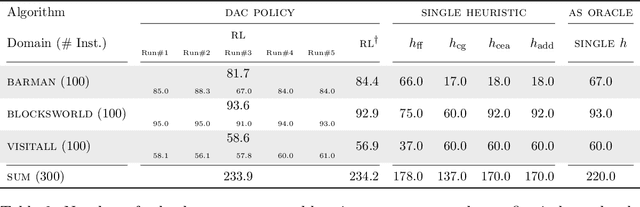
The performance of an algorithm often critically depends on its parameter configuration. While a variety of automated algorithm configuration methods have been proposed to relieve users from the tedious and error-prone task of manually tuning parameters, there is still a lot of untapped potential as the learned configuration is static, i.e., parameter settings remain fixed throughout the run. However, it has been shown that some algorithm parameters are best adjusted dynamically during execution, e.g., to adapt to the current part of the optimization landscape. Thus far, this is most commonly achieved through hand-crafted heuristics. A promising recent alternative is to automatically learn such dynamic parameter adaptation policies from data. In this article, we give the first comprehensive account of this new field of automated dynamic algorithm configuration (DAC), present a series of recent advances, and provide a solid foundation for future research in this field. Specifically, we (i) situate DAC in the broader historical context of AI research; (ii) formalize DAC as a computational problem; (iii) identify the methods used in prior-art to tackle this problem; (iv) conduct empirical case studies for using DAC in evolutionary optimization, AI planning, and machine learning.
HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO
Sep 14, 2021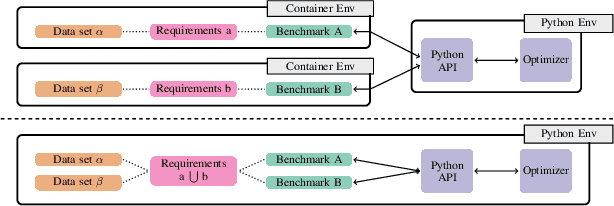
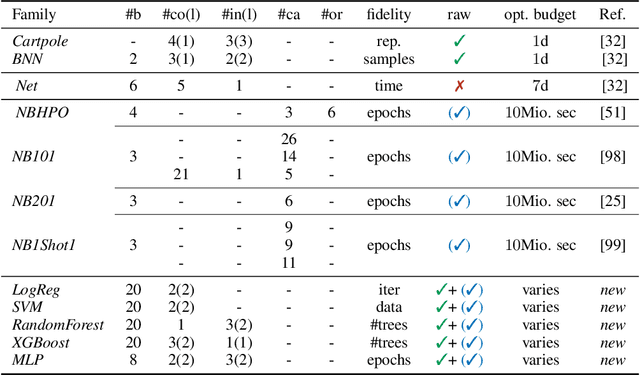

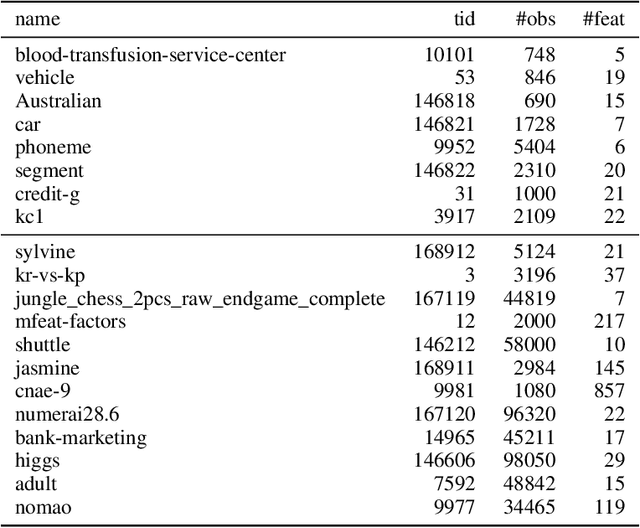
To achieve peak predictive performance, hyperparameter optimization (HPO) is a crucial component of machine learning and its applications. Over the last years,the number of efficient algorithms and tools for HPO grew substantially. At the same time, the community is still lacking realistic, diverse, computationally cheap,and standardized benchmarks. This is especially the case for multi-fidelity HPO methods. To close this gap, we propose HPOBench, which includes 7 existing and 5 new benchmark families, with in total more than 100 multi-fidelity benchmark problems. HPOBench allows to run this extendable set of multi-fidelity HPO benchmarks in a reproducible way by isolating and packaging the individual benchmarks in containers. It also provides surrogate and tabular benchmarks for computationally affordable yet statistically sound evaluations. To demonstrate the broad compatibility of HPOBench and its usefulness, we conduct an exemplary large-scale study evaluating 6 well known multi-fidelity HPO tools.