 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCAVE: An Interactive Analysis Tool for Automated Machine Learning
Jun 07, 2022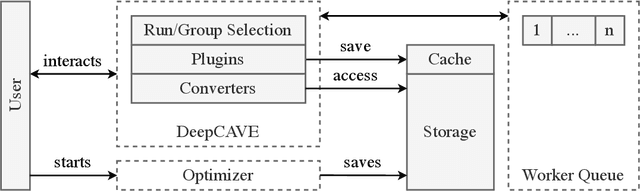
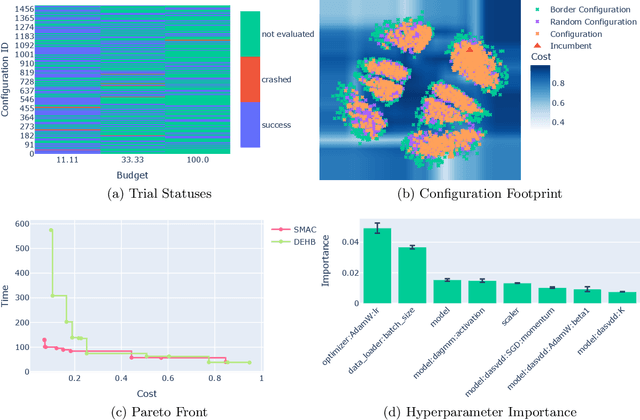
Automated Machine Learning (AutoML) is used more than ever before to support users in determining efficient hyperparameters, neural architectures, or even full machine learning pipelines. However, users tend to mistrust the optimization process and its results due to a lack of transparency, making manual tuning still widespread. We introduce DeepCAVE, an interactive framework to analyze and monitor state-of-the-art optimization procedures for AutoML easily and ad hoc. By aiming for full and accessible transparency, DeepCAVE builds a bridge between users and AutoML and contributes to establishing trust. Our framework's modular and easy-to-extend nature provides users with automatically generated text, tables, and graphic visualizations. We show the value of DeepCAVE in an exemplary use-case of outlier detection, in which our framework makes it easy to identify problems, compare multiple runs and interpret optimization processes. The package is freely available on GitHub https://github.com/automl/DeepCAVE.
SMAC3: A Versatile Bayesian Optimization Package for Hyperparameter Optimization
Sep 20, 2021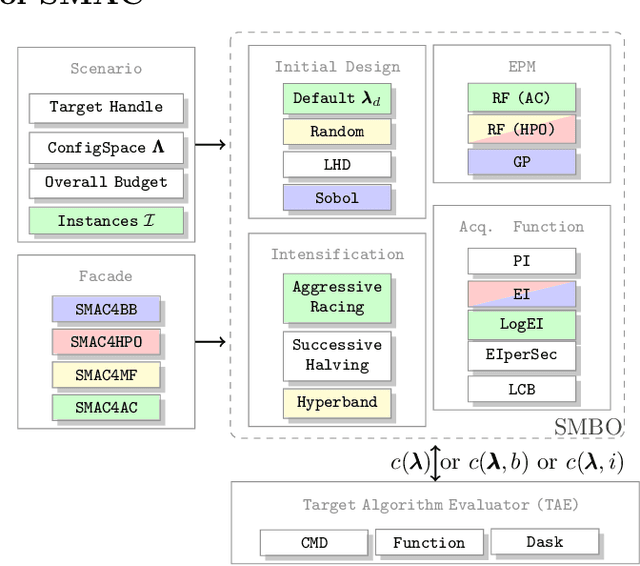
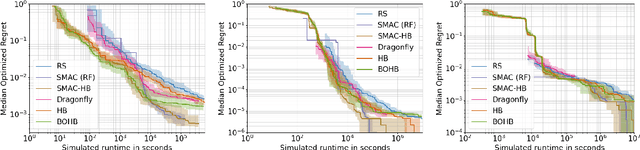
Algorithm parameters, in particular hyperparameters of machine learning algorithms, can substantially impact their performance. To support users in determining well-performing hyperparameter configurations for their algorithms, datasets and applications at hand, SMAC3 offers a robust and flexible framework for Bayesian Optimization, which can improve performance within a few evaluations. It offers several facades and pre-sets for typical use cases, such as optimizing hyperparameters, solving low dimensional continuous (artificial) global optimization problems and configuring algorithms to perform well across multiple problem instances. The SMAC3 package is available under a permissive BSD-license at https://github.com/automl/SMAC3.
HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO
Sep 14, 2021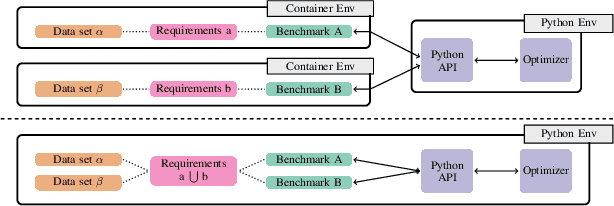
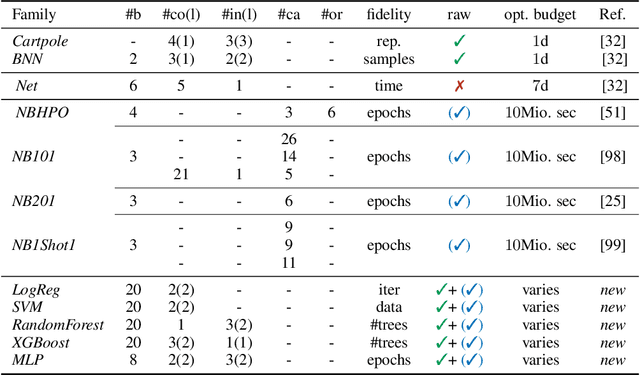

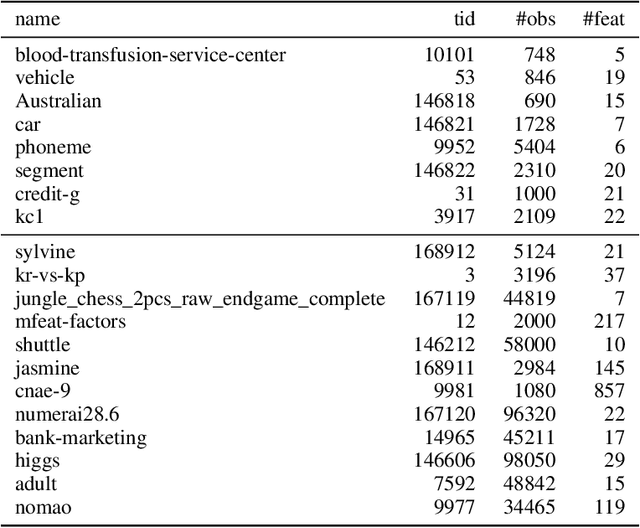
To achieve peak predictive performance, hyperparameter optimization (HPO) is a crucial component of machine learning and its applications. Over the last years,the number of efficient algorithms and tools for HPO grew substantially. At the same time, the community is still lacking realistic, diverse, computationally cheap,and standardized benchmarks. This is especially the case for multi-fidelity HPO methods. To close this gap, we propose HPOBench, which includes 7 existing and 5 new benchmark families, with in total more than 100 multi-fidelity benchmark problems. HPOBench allows to run this extendable set of multi-fidelity HPO benchmarks in a reproducible way by isolating and packaging the individual benchmarks in containers. It also provides surrogate and tabular benchmarks for computationally affordable yet statistically sound evaluations. To demonstrate the broad compatibility of HPOBench and its usefulness, we conduct an exemplary large-scale study evaluating 6 well known multi-fidelity HPO tools.
Risk Assessment for Machine Learning Models
Nov 09, 2020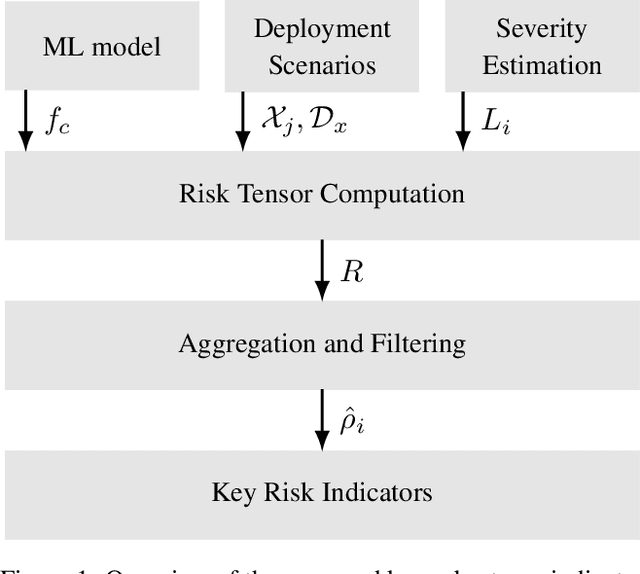
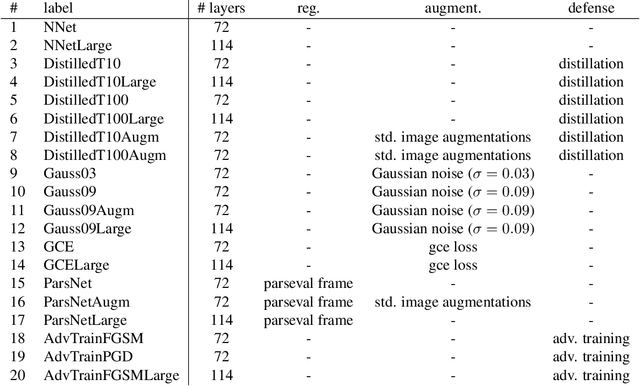
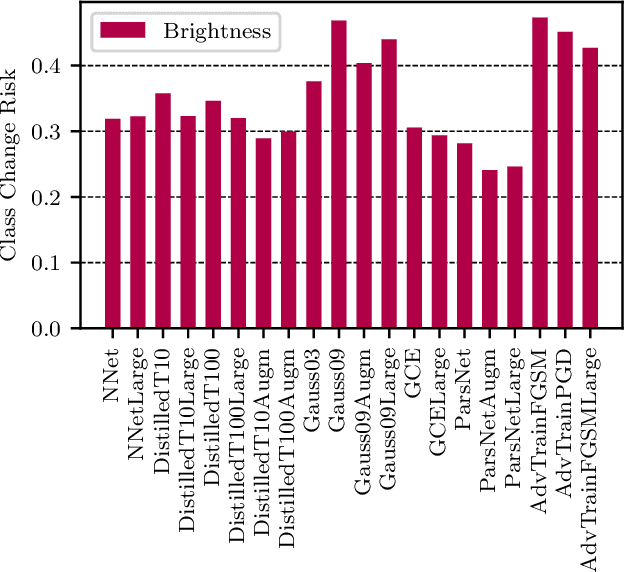
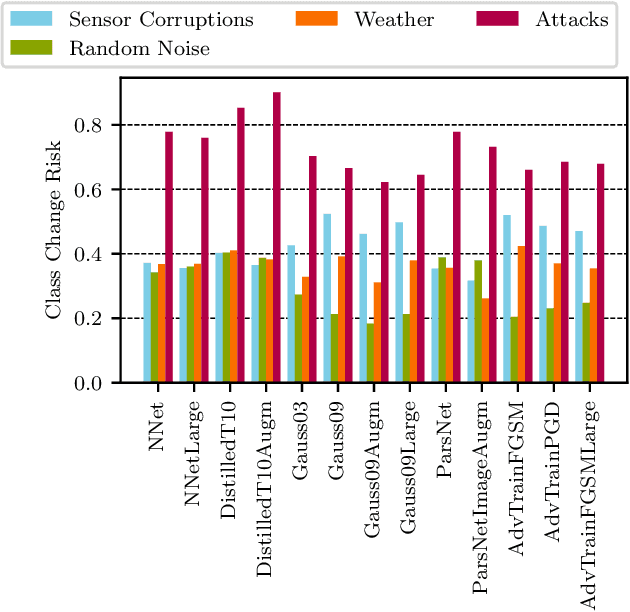
In this paper we propose a framework for assessing the risk associated with deploying a machine learning model in a specified environment. For that we carry over the risk definition from decision theory to machine learning. We develop and implement a method that allows to define deployment scenarios, test the machine learning model under the conditions specified in each scenario, and estimate the damage associated with the output of the machine learning model under test. Using the likelihood of each scenario together with the estimated damage we define \emph{key risk indicators} of a machine learning model. The definition of scenarios and weighting by their likelihood allows for standardized risk assessment in machine learning throughout multiple domains of application. In particular, in our framework, the robustness of a machine learning model to random input corruptions, distributional shifts caused by a changing environment, and adversarial perturbations can be assessed.