 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all Blends are Equal: The BLEMORE Dataset of Blended Emotion Expressions with Relative Salience Annotations
Jan 19, 2026Humans often experience not just a single basic emotion at a time, but rather a blend of several emotions with varying salience. Despite the importance of such blended emotions, most video-based emotion recognition approaches are designed to recognize single emotions only. The few approaches that have attempted to recognize blended emotions typically cannot assess the relative salience of the emotions within a blend. This limitation largely stems from the lack of datasets containing a substantial number of blended emotion samples annotated with relative salience. To address this shortcoming, we introduce BLEMORE, a novel dataset for multimodal (video, audio) blended emotion recognition that includes information on the relative salience of each emotion within a blend. BLEMORE comprises over 3,000 clips from 58 actors, performing 6 basic emotions and 10 distinct blends, where each blend has 3 different salience configurations (50/50, 70/30, and 30/70). Using this dataset, we conduct extensive evaluations of state-of-the-art video classification approaches on two blended emotion prediction tasks: (1) predicting the presence of emotions in a given sample, and (2) predicting the relative salience of emotions in a blend. Our results show that unimodal classifiers achieve up to 29% presence accuracy and 13% salience accuracy on the validation set, while multimodal methods yield clear improvements, with ImageBind + WavLM reaching 35% presence accuracy and HiCMAE 18% salience accuracy. On the held-out test set, the best models achieve 33% presence accuracy (VideoMAEv2 + HuBERT) and 18% salience accuracy (HiCMAE). In sum, the BLEMORE dataset provides a valuable resource to advancing research on emotion recognition systems that account for the complexity and significance of blended emotion expressions.
AutoPsyC: Automatic Recognition of Psychodynamic Conflicts from Semi-structured Interviews with Large Language Models
Mar 27, 2025



Psychodynamic conflicts are persistent, often unconscious themes that shape a person's behaviour and experiences. Accurate diagnosis of psychodynamic conflicts is crucial for effective patient treatment and is commonly done via long, manually scored semi-structured interviews. Existing automated solutions for psychiatric diagnosis tend to focus on the recognition of broad disorder categories such as depression, and it is unclear to what extent psychodynamic conflicts which even the patient themselves may not have conscious access to could be automatically recognised from conversation. In this paper, we propose AutoPsyC, the first method for recognising the presence and significance of psychodynamic conflicts from full-length Operationalized Psychodynamic Diagnostics (OPD) interviews using Large Language Models (LLMs). Our approach combines recent advances in parameter-efficient fine-tuning and Retrieval-Augmented Generation (RAG) with a summarisation strategy to effectively process entire 90 minute long conversations. In evaluations on a dataset of 141 diagnostic interviews we show that AutoPsyC consistently outperforms all baselines and ablation conditions on the recognition of four highly relevant psychodynamic conflicts.
Recognizing Emotion Regulation Strategies from Human Behavior with Large Language Models
Aug 08, 2024



Human emotions are often not expressed directly, but regulated according to internal processes and social display rules. For affective computing systems, an understanding of how users regulate their emotions can be highly useful, for example to provide feedback in job interview training, or in psychotherapeutic scenarios. However, at present no method to automatically classify different emotion regulation strategies in a cross-user scenario exists. At the same time, recent studies showed that instruction-tuned Large Language Models (LLMs) can reach impressive performance across a variety of affect recognition tasks such as categorical emotion recognition or sentiment analysis. While these results are promising, it remains unclear to what extent the representational power of LLMs can be utilized in the more subtle task of classifying users' internal emotion regulation strategy. To close this gap, we make use of the recently introduced \textsc{Deep} corpus for modeling the social display of the emotion shame, where each point in time is annotated with one of seven different emotion regulation classes. We fine-tune Llama2-7B as well as the recently introduced Gemma model using Low-rank Optimization on prompts generated from different sources of information on the \textsc{Deep} corpus. These include verbal and nonverbal behavior, person factors, as well as the results of an in-depth interview after the interaction. Our results show, that a fine-tuned Llama2-7B LLM is able to classify the utilized emotion regulation strategy with high accuracy (0.84) without needing access to data from post-interaction interviews. This represents a significant improvement over previous approaches based on Bayesian Networks and highlights the importance of modeling verbal behavior in emotion regulation.
M3TCM: Multi-modal Multi-task Context Model for Utterance Classification in Motivational Interviews
Apr 04, 2024



Accurate utterance classification in motivational interviews is crucial to automatically understand the quality and dynamics of client-therapist interaction, and it can serve as a key input for systems mediating such interactions. Motivational interviews exhibit three important characteristics. First, there are two distinct roles, namely client and therapist. Second, they are often highly emotionally charged, which can be expressed both in text and in prosody. Finally, context is of central importance to classify any given utterance. Previous works did not adequately incorporate all of these characteristics into utterance classification approaches for mental health dialogues. In contrast, we present M3TCM, a Multi-modal, Multi-task Context Model for utterance classification. Our approach for the first time employs multi-task learning to effectively model both joint and individual components of therapist and client behaviour. Furthermore, M3TCM integrates information from the text and speech modality as well as the conversation context. With our novel approach, we outperform the state of the art for utterance classification on the recently introduced AnnoMI dataset with a relative improvement of 20% for the client- and by 15% for therapist utterance classification. In extensive ablation studies, we quantify the improvement resulting from each contribution.
Classification of Volatile Organic Compounds by Differential Mobility Spectrometry Based on Continuity of Alpha Curves
Jan 13, 2024Background: Classification of volatile organic compounds (VOCs) is of interest in many fields. Examples include but are not limited to medicine, detection of explosives, and food quality control. Measurements collected with electronic noses can be used for classification and analysis of VOCs. One type of electronic noses that has seen considerable development in recent years is Differential Mobility Spectrometry (DMS). DMS yields measurements that are visualized as dispersion plots that contain traces, also known as alpha curves. Current methods used for analyzing DMS dispersion plots do not usually utilize the information stored in the continuity of these traces, which suggests that alternative approaches should be investigated. Results: In this work, for the first time, dispersion plots were interpreted as a series of measurements evolving sequentially. Thus, it was hypothesized that time-series classification algorithms can be effective for classification and analysis of dispersion plots. An extensive dataset of 900 dispersion plots for five chemicals measured at five flow rates and two concentrations was collected. The data was used to analyze the classification performance of six algorithms. According to our hypothesis, the highest classification accuracy of 88\% was achieved by a Long-Short Term Memory neural network, which supports our hypothesis. Significance: A new concept for approaching classification tasks of dispersion plots is presented and compared with other well-known classification algorithms. This creates a new angle of view for analysis and classification of the dispersion plots. In addition, a new dataset of dispersion plots is openly shared to public.
NeMig -- A Bilingual News Collection and Knowledge Graph about Migration
Sep 01, 2023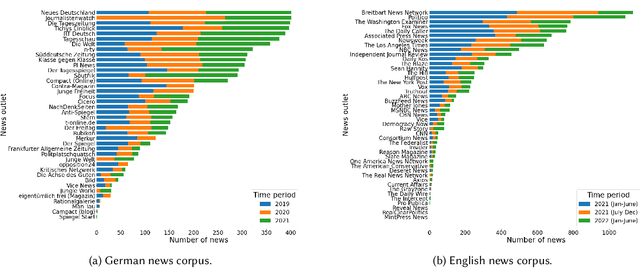

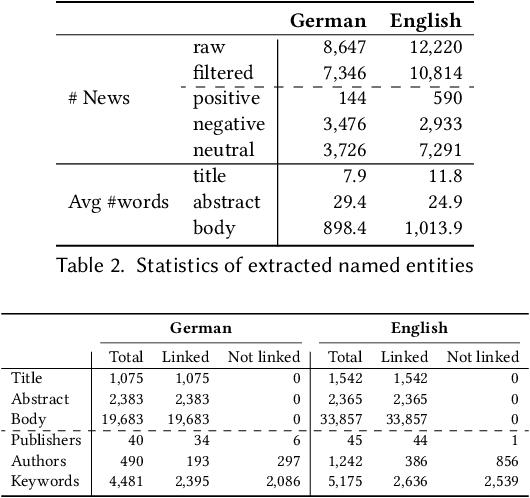
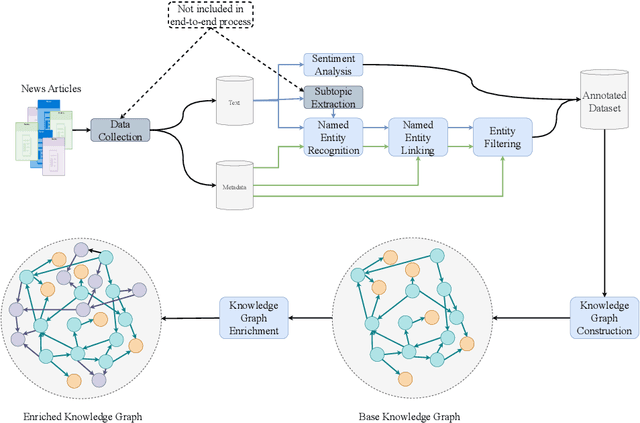
News recommendation plays a critical role in shaping the public's worldviews through the way in which it filters and disseminates information about different topics. Given the crucial impact that media plays in opinion formation, especially for sensitive topics, understanding the effects of personalized recommendation beyond accuracy has become essential in today's digital society. In this work, we present NeMig, a bilingual news collection on the topic of migration, and corresponding rich user data. In comparison to existing news recommendation datasets, which comprise a large variety of monolingual news, NeMig covers articles on a single controversial topic, published in both Germany and the US. We annotate the sentiment polarization of the articles and the political leanings of the media outlets, in addition to extracting subtopics and named entities disambiguated through Wikidata. These features can be used to analyze the effects of algorithmic news curation beyond accuracy-based performance, such as recommender biases and the creation of filter bubbles. We construct domain-specific knowledge graphs from the news text and metadata, thus encoding knowledge-level connections between articles. Importantly, while existing datasets include only click behavior, we collect user socio-demographic and political information in addition to explicit click feedback. We demonstrate the utility of NeMig through experiments on the tasks of news recommenders benchmarking, analysis of biases in recommenders, and news trends analysis. NeMig aims to provide a useful resource for the news recommendation community and to foster interdisciplinary research into the multidimensional effects of algorithmic news curation.
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023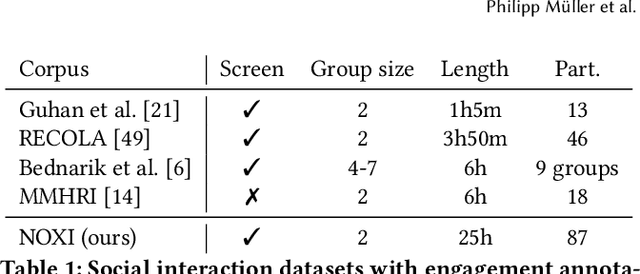
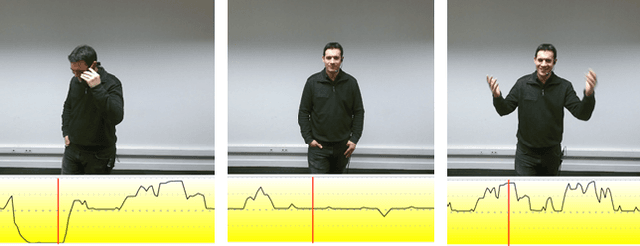

Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
Backchannel Detection and Agreement Estimation from Video with Transformer Networks
Jun 02, 2023


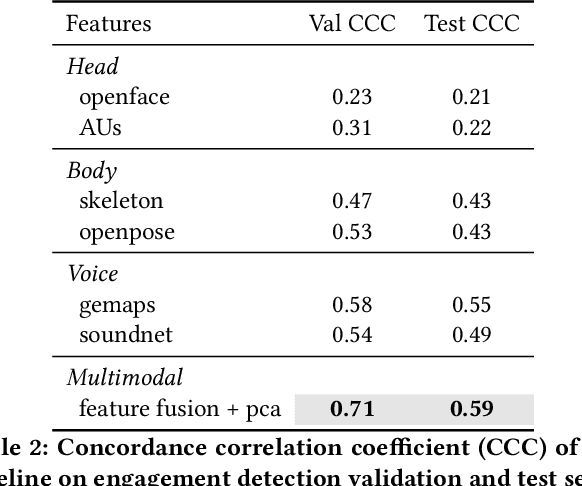
Listeners use short interjections, so-called backchannels, to signify attention or express agreement. The automatic analysis of this behavior is of key importance for human conversation analysis and interactive conversational agents. Current state-of-the-art approaches for backchannel analysis from visual behavior make use of two types of features: features based on body pose and features based on facial behavior. At the same time, transformer neural networks have been established as an effective means to fuse input from different data sources, but they have not yet been applied to backchannel analysis. In this work, we conduct a comprehensive evaluation of multi-modal transformer architectures for automatic backchannel analysis based on pose and facial information. We address both the detection of backchannels as well as the task of estimating the agreement expressed in a backchannel. In evaluations on the MultiMediate'22 backchannel detection challenge, we reach 66.4% accuracy with a one-layer transformer architecture, outperforming the previous state of the art. With a two-layer transformer architecture, we furthermore set a new state of the art (0.0604 MSE) on the task of estimating the amount of agreement expressed in a backchannel.
Flexible K Nearest Neighbors Classifier: Derivation and Application for Ion-mobility Spectrometry-based Indoor Localization
Apr 20, 2023
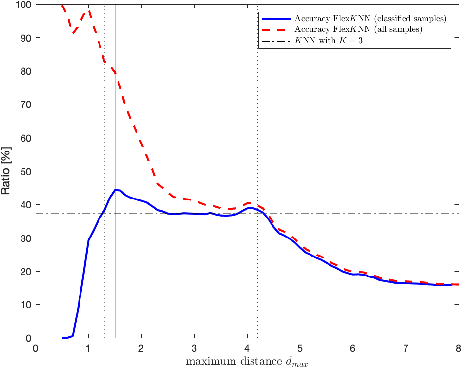

The K Nearest Neighbors (KNN) classifier is widely used in many fields such as fingerprint-based localization or medicine. It determines the class membership of unlabelled sample based on the class memberships of the K labelled samples, the so-called nearest neighbors, that are closest to the unlabelled sample. The choice of K has been the topic of various studies and proposed KNN-variants. Yet no variant has been proven to outperform all other variants. In this paper a new KNN-variant is proposed which ensures that the K nearest neighbors are indeed close to the unlabelled sample and finds K along the way. The proposed algorithm is tested and compared to the standard KNN in theoretical scenarios and for indoor localization based on ion-mobility spectrometry fingerprints. It achieves a higher classification accuracy than the KNN in the tests, while requiring having the same computational demand.
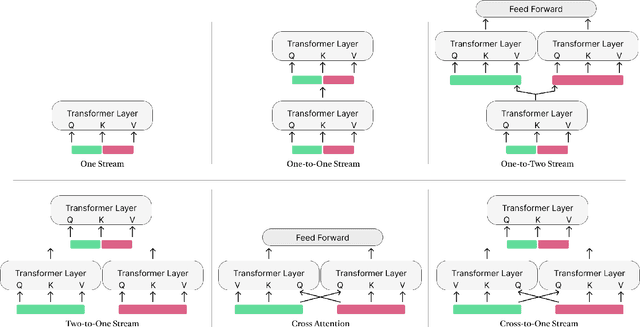
Multimodal Vision Transformers with Forced Attention for Behavior Analysis
Dec 07, 2022Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilize forced attention with a modified backbone for input encoding and a use of additional inputs. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We provide a model for a generalised feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPII Group Interaction datasets. We further provide an extensive ablation study of the proposed architecture.