 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatar Visual Similarity for Social HCI: Increasing Self-Awareness
Aug 23, 2024



Self-awareness is a critical factor in social human-human interaction and, hence, in social HCI interaction. Increasing self-awareness through mirrors or video recordings is common in face-to-face trainings, since it influences antecedents of self-awareness like explicit identification and implicit affective identification (affinity). However, increasing self-awareness has been scarcely examined in virtual trainings with virtual avatars, which allow for adjusting the similarity, e.g. to avoid negative effects of self-consciousness. Automatic visual similarity in avatars is an open issue related to high costs. It is important to understand which features need to be manipulated and which degree of similarity is necessary for self-awareness to leverage the added value of using avatars for self-awareness. This article examines the relationship between avatar visual similarity and increasing self-awareness in virtual training environments. We define visual similarity based on perceptually important facial features for human-human identification and develop a theory-based methodology to systematically manipulate visual similarity of virtual avatars and support self-awareness. Three personalized versions of virtual avatars with varying degrees of visual similarity to participants were created (weak, medium and strong facial features manipulation). In a within-subject study (N=33), we tested effects of degree of similarity on perceived similarity, explicit identification and implicit affective identification (affinity). Results show significant differences between the weak similarity manipulation, and both the strong manipulation and the random avatar for all three antecedents of self-awareness. An increasing degree of avatar visual similarity influences antecedents of self-awareness in virtual environments.
Backchannel Detection and Agreement Estimation from Video with Transformer Networks
Jun 02, 2023
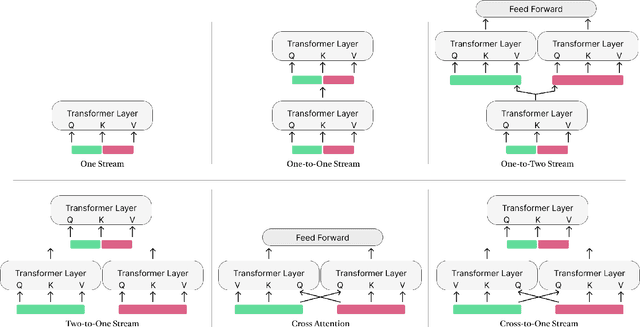


Listeners use short interjections, so-called backchannels, to signify attention or express agreement. The automatic analysis of this behavior is of key importance for human conversation analysis and interactive conversational agents. Current state-of-the-art approaches for backchannel analysis from visual behavior make use of two types of features: features based on body pose and features based on facial behavior. At the same time, transformer neural networks have been established as an effective means to fuse input from different data sources, but they have not yet been applied to backchannel analysis. In this work, we conduct a comprehensive evaluation of multi-modal transformer architectures for automatic backchannel analysis based on pose and facial information. We address both the detection of backchannels as well as the task of estimating the agreement expressed in a backchannel. In evaluations on the MultiMediate'22 backchannel detection challenge, we reach 66.4% accuracy with a one-layer transformer architecture, outperforming the previous state of the art. With a two-layer transformer architecture, we furthermore set a new state of the art (0.0604 MSE) on the task of estimating the amount of agreement expressed in a backchannel.