 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackchannel Detection and Agreement Estimation from Video with Transformer Networks
Jun 02, 2023
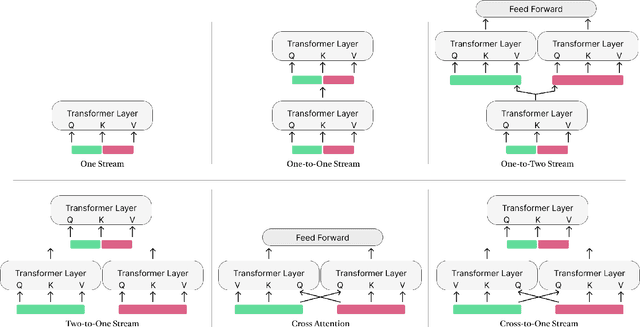


Listeners use short interjections, so-called backchannels, to signify attention or express agreement. The automatic analysis of this behavior is of key importance for human conversation analysis and interactive conversational agents. Current state-of-the-art approaches for backchannel analysis from visual behavior make use of two types of features: features based on body pose and features based on facial behavior. At the same time, transformer neural networks have been established as an effective means to fuse input from different data sources, but they have not yet been applied to backchannel analysis. In this work, we conduct a comprehensive evaluation of multi-modal transformer architectures for automatic backchannel analysis based on pose and facial information. We address both the detection of backchannels as well as the task of estimating the agreement expressed in a backchannel. In evaluations on the MultiMediate'22 backchannel detection challenge, we reach 66.4% accuracy with a one-layer transformer architecture, outperforming the previous state of the art. With a two-layer transformer architecture, we furthermore set a new state of the art (0.0604 MSE) on the task of estimating the amount of agreement expressed in a backchannel.