 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan you see how I learn? Human observers' inferences about Reinforcement Learning agents' learning processes
Jun 16, 2025
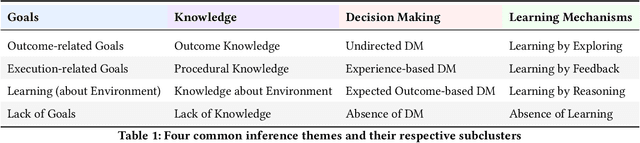
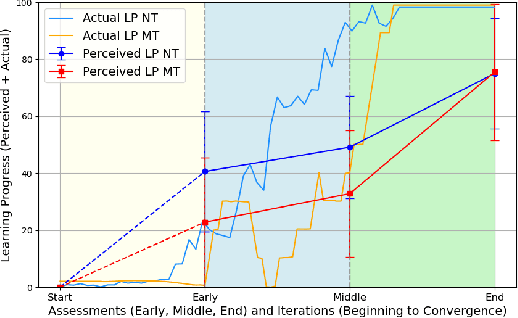

Reinforcement Learning (RL) agents often exhibit learning behaviors that are not intuitively interpretable by human observers, which can result in suboptimal feedback in collaborative teaching settings. Yet, how humans perceive and interpret RL agent's learning behavior is largely unknown. In a bottom-up approach with two experiments, this work provides a data-driven understanding of the factors of human observers' understanding of the agent's learning process. A novel, observation-based paradigm to directly assess human inferences about agent learning was developed. In an exploratory interview study (\textit{N}=9), we identify four core themes in human interpretations: Agent Goals, Knowledge, Decision Making, and Learning Mechanisms. A second confirmatory study (\textit{N}=34) applied an expanded version of the paradigm across two tasks (navigation/manipulation) and two RL algorithms (tabular/function approximation). Analyses of 816 responses confirmed the reliability of the paradigm and refined the thematic framework, revealing how these themes evolve over time and interrelate. Our findings provide a human-centered understanding of how people make sense of agent learning, offering actionable insights for designing interpretable RL systems and improving transparency in Human-Robot Interaction.
Avatar Visual Similarity for Social HCI: Increasing Self-Awareness
Aug 23, 2024



Self-awareness is a critical factor in social human-human interaction and, hence, in social HCI interaction. Increasing self-awareness through mirrors or video recordings is common in face-to-face trainings, since it influences antecedents of self-awareness like explicit identification and implicit affective identification (affinity). However, increasing self-awareness has been scarcely examined in virtual trainings with virtual avatars, which allow for adjusting the similarity, e.g. to avoid negative effects of self-consciousness. Automatic visual similarity in avatars is an open issue related to high costs. It is important to understand which features need to be manipulated and which degree of similarity is necessary for self-awareness to leverage the added value of using avatars for self-awareness. This article examines the relationship between avatar visual similarity and increasing self-awareness in virtual training environments. We define visual similarity based on perceptually important facial features for human-human identification and develop a theory-based methodology to systematically manipulate visual similarity of virtual avatars and support self-awareness. Three personalized versions of virtual avatars with varying degrees of visual similarity to participants were created (weak, medium and strong facial features manipulation). In a within-subject study (N=33), we tested effects of degree of similarity on perceived similarity, explicit identification and implicit affective identification (affinity). Results show significant differences between the weak similarity manipulation, and both the strong manipulation and the random avatar for all three antecedents of self-awareness. An increasing degree of avatar visual similarity influences antecedents of self-awareness in virtual environments.
Fine-grained Affective Processing Capabilities Emerging from Large Language Models
Sep 04, 2023Large language models, in particular generative pre-trained transformers (GPTs), show impressive results on a wide variety of language-related tasks. In this paper, we explore ChatGPT's zero-shot ability to perform affective computing tasks using prompting alone. We show that ChatGPT a) performs meaningful sentiment analysis in the Valence, Arousal and Dominance dimensions, b) has meaningful emotion representations in terms of emotion categories and these affective dimensions, and c) can perform basic appraisal-based emotion elicitation of situations based on a prompt-based computational implementation of the OCC appraisal model. These findings are highly relevant: First, they show that the ability to solve complex affect processing tasks emerges from language-based token prediction trained on extensive data sets. Second, they show the potential of large language models for simulating, processing and analyzing human emotions, which has important implications for various applications such as sentiment analysis, socially interactive agents, and social robotics.