 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan you see how I learn? Human observers' inferences about Reinforcement Learning agents' learning processes
Jun 16, 2025
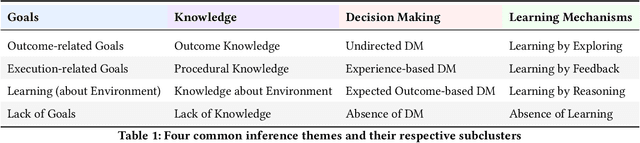
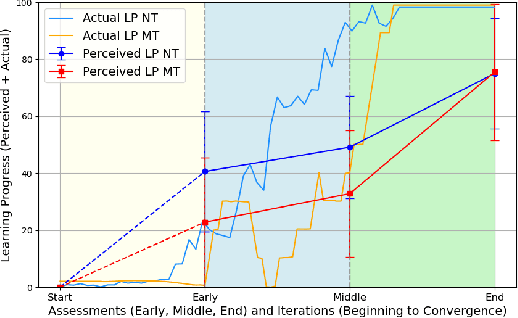

Reinforcement Learning (RL) agents often exhibit learning behaviors that are not intuitively interpretable by human observers, which can result in suboptimal feedback in collaborative teaching settings. Yet, how humans perceive and interpret RL agent's learning behavior is largely unknown. In a bottom-up approach with two experiments, this work provides a data-driven understanding of the factors of human observers' understanding of the agent's learning process. A novel, observation-based paradigm to directly assess human inferences about agent learning was developed. In an exploratory interview study (\textit{N}=9), we identify four core themes in human interpretations: Agent Goals, Knowledge, Decision Making, and Learning Mechanisms. A second confirmatory study (\textit{N}=34) applied an expanded version of the paradigm across two tasks (navigation/manipulation) and two RL algorithms (tabular/function approximation). Analyses of 816 responses confirmed the reliability of the paradigm and refined the thematic framework, revealing how these themes evolve over time and interrelate. Our findings provide a human-centered understanding of how people make sense of agent learning, offering actionable insights for designing interpretable RL systems and improving transparency in Human-Robot Interaction.
Reasoning with Large Language Models, a Survey
Jul 16, 2024



Scaling up language models to billions of parameters has opened up possibilities for in-context learning, allowing instruction tuning and few-shot learning on tasks that the model was not specifically trained for. This has achieved breakthrough performance on language tasks such as translation, summarization, and question-answering. Furthermore, in addition to these associative "System 1" tasks, recent advances in Chain-of-thought prompt learning have demonstrated strong "System 2" reasoning abilities, answering a question in the field of artificial general intelligence whether LLMs can reason. The field started with the question whether LLMs can solve grade school math word problems. This paper reviews the rapidly expanding field of prompt-based reasoning with LLMs. Our taxonomy identifies different ways to generate, evaluate, and control multi-step reasoning. We provide an in-depth coverage of core approaches and open problems, and we propose a research agenda for the near future. Finally, we highlight the relation between reasoning and prompt-based learning, and we discuss the relation between reasoning, sequential decision processes, and reinforcement learning. We find that self-improvement, self-reflection, and some metacognitive abilities of the reasoning processes are possible through the judicious use of prompts. True self-improvement and self-reasoning, to go from reasoning with LLMs to reasoning by LLMs, remains future work.
Fine-grained Affective Processing Capabilities Emerging from Large Language Models
Sep 04, 2023Large language models, in particular generative pre-trained transformers (GPTs), show impressive results on a wide variety of language-related tasks. In this paper, we explore ChatGPT's zero-shot ability to perform affective computing tasks using prompting alone. We show that ChatGPT a) performs meaningful sentiment analysis in the Valence, Arousal and Dominance dimensions, b) has meaningful emotion representations in terms of emotion categories and these affective dimensions, and c) can perform basic appraisal-based emotion elicitation of situations based on a prompt-based computational implementation of the OCC appraisal model. These findings are highly relevant: First, they show that the ability to solve complex affect processing tasks emerges from language-based token prediction trained on extensive data sets. Second, they show the potential of large language models for simulating, processing and analyzing human emotions, which has important implications for various applications such as sentiment analysis, socially interactive agents, and social robotics.
A Valid Self-Report is Never Late, Nor is it Early: On Considering the "Right" Temporal Distance for Assessing Emotional Experience
Jan 27, 2023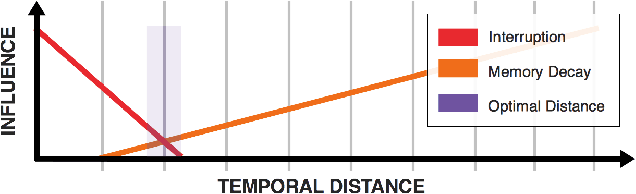
Developing computational models for automatic affect prediction requires valid self-reports about individuals' emotional interpretations of stimuli. In this article, we highlight the important influence of the temporal distance between a stimulus event and the moment when its experience is reported on the provided information's validity. This influence stems from the time-dependent and time-demanding nature of the involved cognitive processes. As such, reports can be collected too late: forgetting is a widely acknowledged challenge for accurate descriptions of past experience. For this reason, methods striving for assessment as early as possible have become increasingly popular. However, here we argue that collection may also occur too early: descriptions about very recent stimuli might be collected before emotional processing has fully converged. Based on these notions, we champion the existence of a temporal distance for each type of stimulus that maximizes the validity of self-reports -- a "right" time. Consequently, we recommend future research to (1) consciously consider the potential influence of temporal distance on affective self-reports when planning data collection, (2) document the temporal distance of affective self-reports wherever possible as part of corpora for computational modelling, and finally (3) and explore the effect of temporal distance on self-reports across different types of stimuli.
A Blast From the Past: Personalizing Predictions of Video-Induced Emotions using Personal Memories as Context
Aug 27, 2020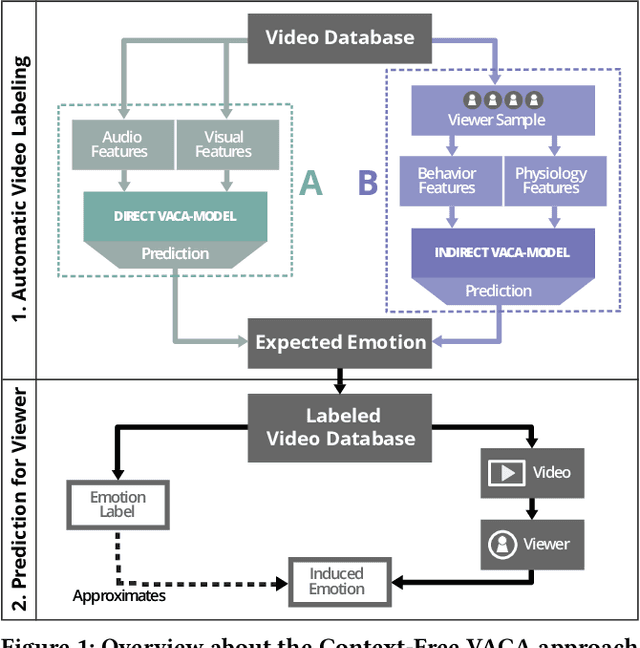
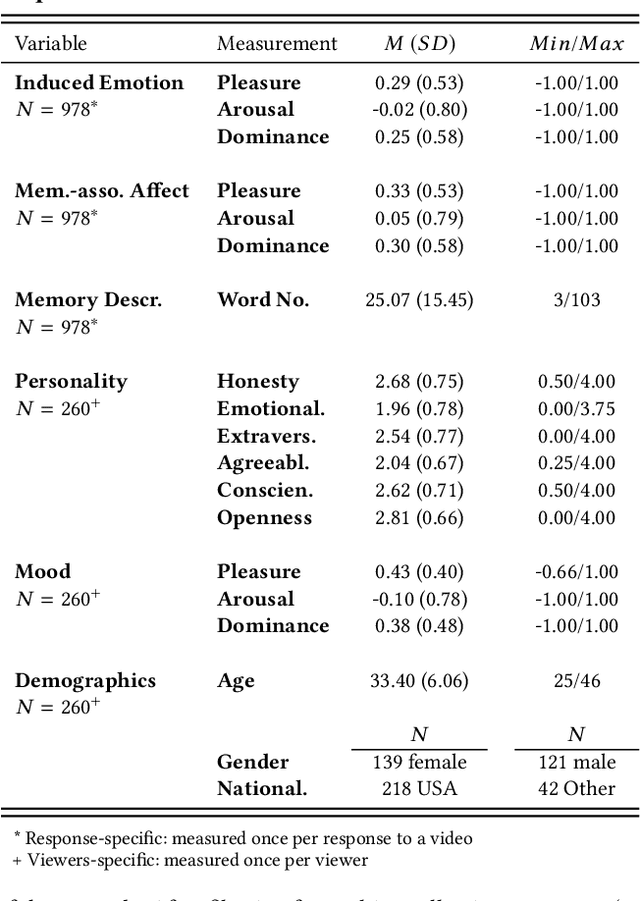

A key challenge in the accurate prediction of viewers' emotional responses to video stimuli in real-world applications is accounting for person- and situation-specific variation. An important contextual influence shaping individuals' subjective experience of a video is the personal memories that it triggers in them. Prior research has found that this memory influence explains more variation in video-induced emotions than other contextual variables commonly used for personalizing predictions, such as viewers' demographics or personality. In this article, we show that (1) automatic analysis of text describing their video-triggered memories can account for variation in viewers' emotional responses, and (2) that combining such an analysis with that of a video's audiovisual content enhances the accuracy of automatic predictions. We discuss the relevance of these findings for improving on state of the art approaches to automated affective video analysis in personalized contexts.
A Framework for Reinforcement Learning and Planning
Jul 02, 2020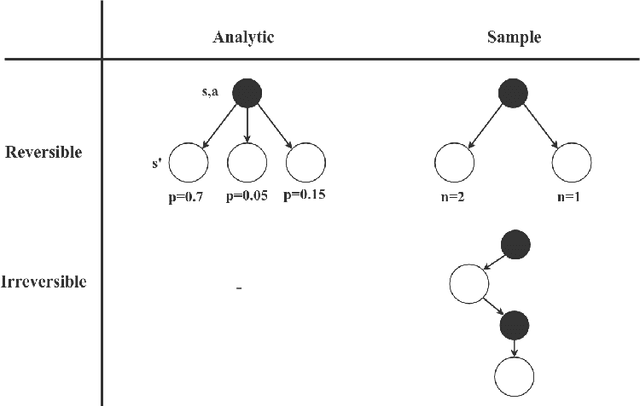



Sequential decision making, commonly formalized as Markov Decision Process optimization, is a key challenge in artificial intelligence. Two successful approaches to MDP optimization are planning and reinforcement learning. Both research fields largely have their own research communities. However, if both research fields solve the same problem, then we should be able to disentangle the common factors in their solution approaches. Therefore, this paper presents a unifying framework for reinforcement learning and planning (FRAP), which identifies the underlying dimensions on which any planning or learning algorithm has to decide. At the end of the paper, we compare - in a single table - a variety of well-known planning, model-free and model-based RL algorithms along the dimensions of our framework, illustrating the validity of the framework. Altogether, FRAP provides deeper insight into the algorithmic space of planning and reinforcement learning, and also suggests new approaches to integration of both fields.
Model-based Reinforcement Learning: A Survey
Jun 30, 2020
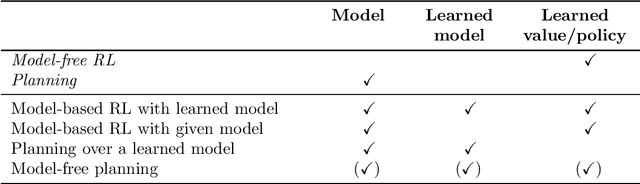


Sequential decision making, commonly formalized as Markov Decision Process (MDP) optimization, is a key challenge in artificial intelligence. Two key approaches to this problem are reinforcement learning (RL) and planning. This paper presents a survey of the integration of both fields, better known as model-based reinforcement learning. Model-based RL has two main steps. First, we systematically cover approaches to dynamics model learning, including challenges like dealing with stochasticity, uncertainty, partial observability, and temporal abstraction. Second, we present a systematic categorization of planning-learning integration, including aspects like: where to start planning, what budgets to allocate to planning and real data collection, how to plan, and how to integrate planning in the learning and acting loop. After these two key sections, we also discuss the potential benefits of model-based RL, like enhanced data efficiency, targeted exploration, and improved stability. Along the survey, we also draw connections to several related RL fields, like hierarchical RL and transfer, and other research disciplines, like behavioural psychology. Altogether, the survey presents a broad conceptual overview of planning-learning combinations for MDP optimization.
The Second Type of Uncertainty in Monte Carlo Tree Search
May 19, 2020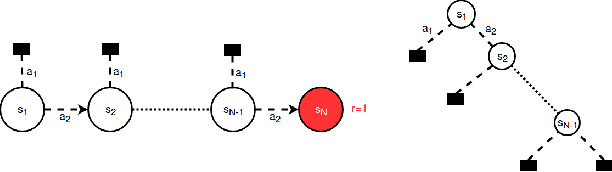
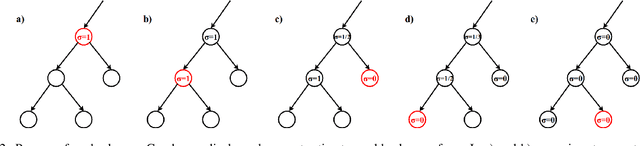
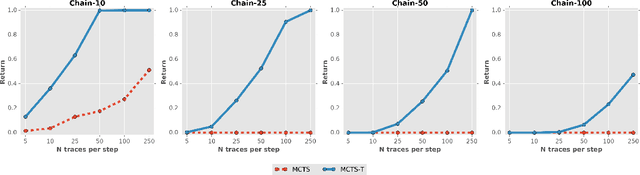

Monte Carlo Tree Search (MCTS) efficiently balances exploration and exploitation in tree search based on count-derived uncertainty. However, these local visit counts ignore a second type of uncertainty induced by the size of the subtree below an action. We first show how, due to the lack of this second uncertainty type, MCTS may completely fail in well-known sparse exploration problems, known from the reinforcement learning community. We then introduce a new algorithm, which estimates the size of the subtree below an action, and leverages this information in the UCB formula to better direct exploration. Subsequently, we generalize these ideas by showing that loops, i.e., the repeated occurrence of (approximately) the same state in the same trace, are actually a special case of subtree depth variation. Testing on a variety of tasks shows that our algorithms increase sample efficiency, especially when the planning budget per timestep is small.
Think Too Fast Nor Too Slow: The Computational Trade-off Between Planning And Reinforcement Learning
May 15, 2020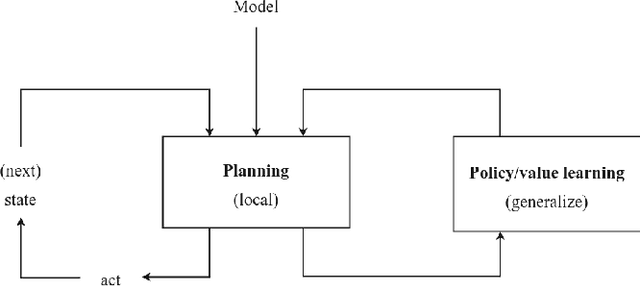

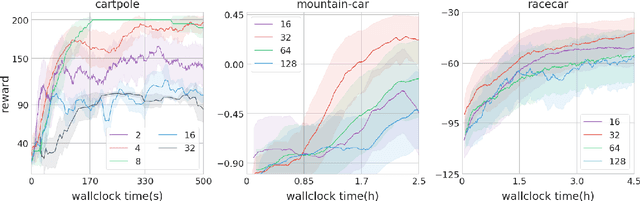
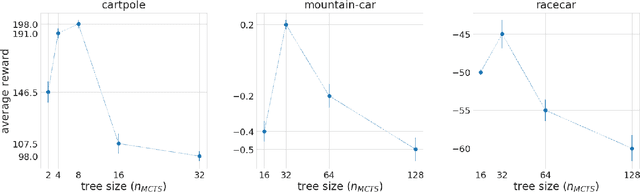
Planning and reinforcement learning are two key approaches to sequential decision making. Multi-step approximate real-time dynamic programming, a recently successful algorithm class of which AlphaZero [Silver et al., 2018] is an example, combines both by nesting planning within a learning loop. However, the combination of planning and learning introduces a new question: how should we balance time spend on planning, learning and acting? The importance of this trade-off has not been explicitly studied before. We show that it is actually of key importance, with computational results indicating that we should neither plan too long nor too short. Conceptually, we identify a new spectrum of planning-learning algorithms which ranges from exhaustive search (long planning) to model-free RL (no planning), with optimal performance achieved midway.
A Temporal Difference Reinforcement Learning Theory of Emotion: unifying emotion, cognition and adaptive behavior
Jul 24, 2018
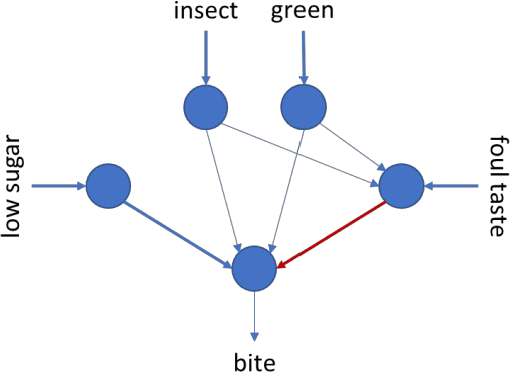

Emotions are intimately tied to motivation and the adaptation of behavior, and many animal species show evidence of emotions in their behavior. Therefore, emotions must be related to powerful mechanisms that aid survival, and, emotions must be evolutionary continuous phenomena. How and why did emotions evolve in nature, how do events get emotionally appraised, how do emotions relate to cognitive complexity, and, how do they impact behavior and learning? In this article I propose that all emotions are manifestations of reward processing, in particular Temporal Difference (TD) error assessment. Reinforcement Learning (RL) is a powerful computational model for the learning of goal oriented tasks by exploration and feedback. Evidence indicates that RL-like processes exist in many animal species. Key in the processing of feedback in RL is the notion of TD error, the assessment of how much better or worse a situation just became, compared to what was previously expected (or, the estimated gain or loss of utility - or well-being - resulting from new evidence). I propose a TDRL Theory of Emotion and discuss its ramifications for our understanding of emotions in humans, animals and machines, and present psychological, neurobiological and computational evidence in its support.