 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Private is Low-Frequency Speech Audio in the Wild? An Analysis of Verbal Intelligibility by Humans and Machines
Jul 18, 2024



Low-frequency audio has been proposed as a promising privacy-preserving modality to study social dynamics in real-world settings. To this end, researchers have developed wearable devices that can record audio at frequencies as low as 1250 Hz to mitigate the automatic extraction of the verbal content of speech that may contain private details. This paper investigates the validity of this hypothesis, examining the degree to which low-frequency speech ensures verbal privacy. It includes simulating a potential privacy attack in various noise environments. Further, it explores the trade-off between the performance of voice activity detection, which is fundamental for understanding social behavior, and privacy-preservation. The evaluation incorporates subjective human intelligibility and automatic speech recognition performance, comprehensively analyzing the delicate balance between effective social behavior analysis and preserving verbal privacy.
REWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024



Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
Impact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Nov 02, 2022
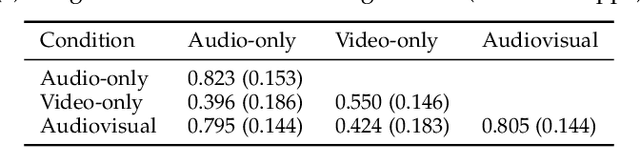
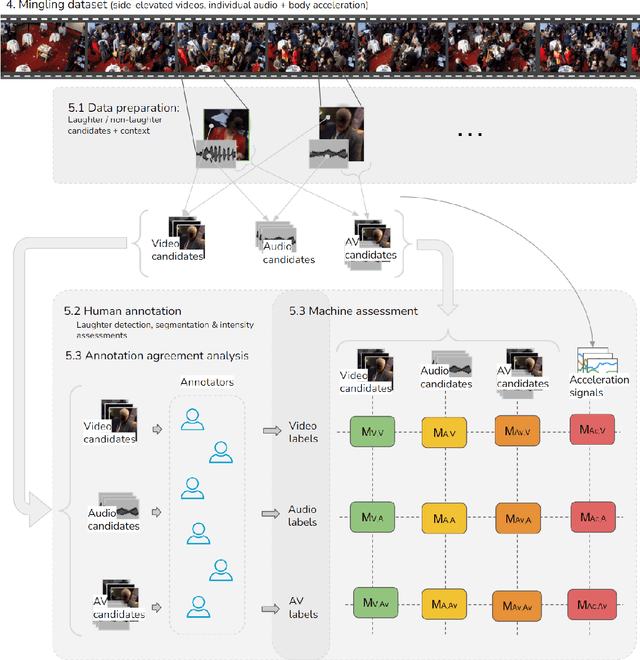
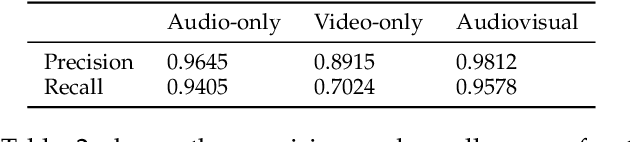
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.
No-audio speaking status detection in crowded settings via visual pose-based filtering and wearable acceleration
Nov 01, 2022Recognizing who is speaking in a crowded scene is a key challenge towards the understanding of the social interactions going on within. Detecting speaking status from body movement alone opens the door for the analysis of social scenes in which personal audio is not obtainable. Video and wearable sensors make it possible recognize speaking in an unobtrusive, privacy-preserving way. When considering the video modality, in action recognition problems, a bounding box is traditionally used to localize and segment out the target subject, to then recognize the action taking place within it. However, cross-contamination, occlusion, and the articulated nature of the human body, make this approach challenging in a crowded scene. Here, we leverage articulated body poses for subject localization and in the subsequent speech detection stage. We show that the selection of local features around pose keypoints has a positive effect on generalization performance while also significantly reducing the number of local features considered, making for a more efficient method. Using two in-the-wild datasets with different viewpoints of subjects, we investigate the role of cross-contamination in this effect. We additionally make use of acceleration measured through wearable sensors for the same task, and present a multimodal approach combining both methods.
Conversation Group Detection With Spatio-Temporal Context
Jun 02, 2022
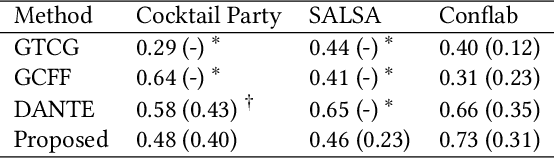

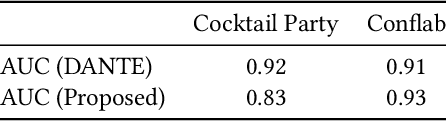
In this work, we propose an approach for detecting conversation groups in social scenarios like cocktail parties and networking events, from overhead camera recordings. We posit the detection of conversation groups as a learning problem that could benefit from leveraging the spatial context of the surroundings, and the inherent temporal context in interpersonal dynamics which is reflected in the temporal dynamics in human behavior signals, an aspect that has not been addressed in recent prior works. This motivates our approach which consists of a dynamic LSTM-based deep learning model that predicts continuous pairwise affinity values indicating how likely two people are in the same conversation group. These affinity values are also continuous in time, since relationships and group membership do not occur instantaneously, even though the ground truths of group membership are binary. Using the predicted affinity values, we apply a graph clustering method based on Dominant Set extraction to identify the conversation groups. We benchmark the proposed method against established methods on multiple social interaction datasets. Our results showed that the proposed method improves group detection performance in data that has more temporal granularity in conversation group labels. Additionally, we provide an analysis in the predicted affinity values in relation to the conversation group detection. Finally, we demonstrate the usability of the predicted affinity values in a forecasting framework to predict group membership for a given forecast horizon.
Why Did This Model Forecast This Future? Closed-Form Temporal Saliency Towards Causal Explanations of Probabilistic Forecasts
Jun 01, 2022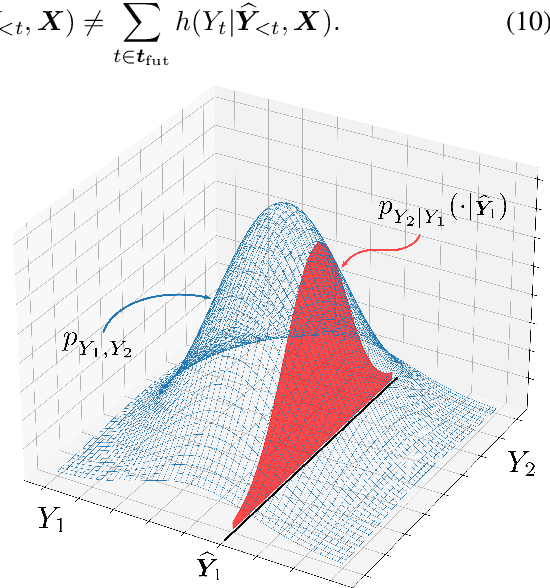
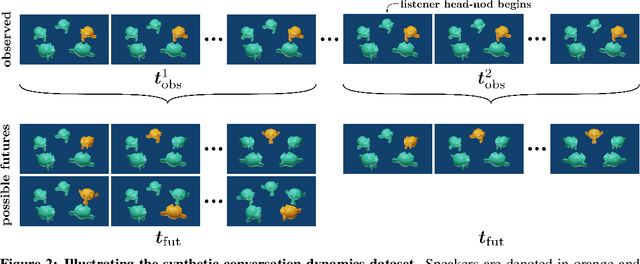

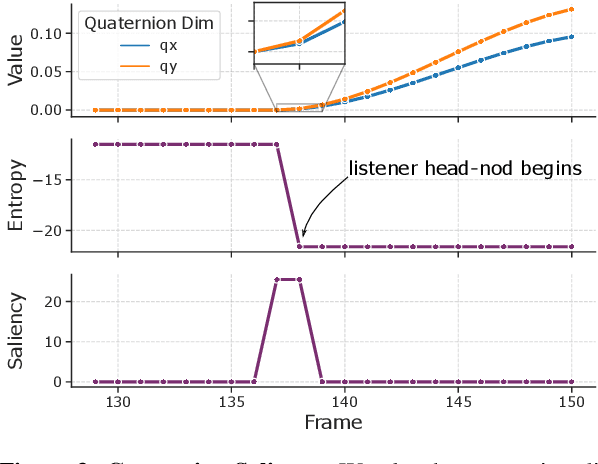
Forecasting tasks surrounding the dynamics of low-level human behavior are of significance to multiple research domains. In such settings, methods for explaining specific forecasts can enable domain experts to gain insights into the predictive relationships between behaviors. In this work, we introduce and address the following question: given a probabilistic forecasting model how can we identify observed windows that the model considers salient when making its forecasts? We build upon a general definition of information-theoretic saliency grounded in human perception and extend it to forecasting settings by leveraging a crucial attribute of the domain: a single observation can result in multiple valid futures. We propose to express the saliency of an observed window in terms of the differential entropy of the resulting predicted future distribution. In contrast to existing methods that either require explicit training of the saliency mechanism or access to the internal states of the forecasting model, we obtain a closed-form solution for the saliency map for commonly used density functions in probabilistic forecasting. We empirically demonstrate how our framework can recover salient observed windows from head pose features for the sample task of speaking-turn forecasting using a synthesized conversation dataset.
ConfLab: A Rich Multimodal Multisensor Dataset of Free-Standing Social Interactions In-the-Wild
May 10, 2022


We describe an instantiation of a new concept for multimodal multisensor data collection of real life in-the-wild free standing social interactions in the form of a Conference Living Lab (ConfLab). ConfLab contains high fidelity data of 49 people during a real-life professional networking event capturing a diverse mix of status, acquaintanceship, and networking motivations at an international conference. Recording such a dataset is challenging due to the delicate trade-off between participant privacy and fidelity of the data, and the technical and logistic challenges involved. We improve upon prior datasets in the fidelity of most of our modalities: 8-camera overhead setup, personal wearable sensors recording body motion (9-axis IMU), Bluetooth-based proximity, and low-frequency audio. Additionally, we use a state-of-the-art hardware synchronization solution and time-efficient continuous technique for annotating body keypoints and actions at high frequencies. We argue that our improvements are essential for a deeper study of interaction dynamics at finer time scales. Our research tasks showcase some of the open challenges related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton based no-audio speaker detection, and F-formation detection. With the ConfLab dataset, we aim to bridge the gap between traditional computer vision tasks and in-the-wild ecologically valid socially-motivated tasks.
Social Processes: Self-Supervised Forecasting of Nonverbal Cues in Social Conversations
Jul 28, 2021
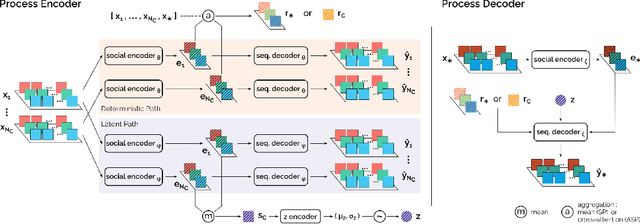
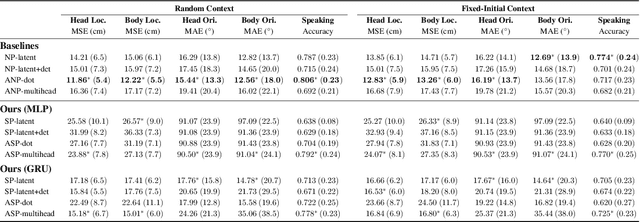
The default paradigm for the forecasting of human behavior in social conversations is characterized by top-down approaches. These involve identifying predictive relationships between low level nonverbal cues and future semantic events of interest (e.g. turn changes, group leaving). A common hurdle however, is the limited availability of labeled data for supervised learning. In this work, we take the first step in the direction of a bottom-up self-supervised approach in the domain. We formulate the task of Social Cue Forecasting to leverage the larger amount of unlabeled low-level behavior cues, and characterize the modeling challenges involved. To address these, we take a meta-learning approach and propose the Social Process (SP) models--socially aware sequence-to-sequence (Seq2Seq) models within the Neural Process (NP) family. SP models learn extractable representations of non-semantic future cues for each participant, while capturing global uncertainty by jointly reasoning about the future for all members of the group. Evaluation on synthesized and real-world behavior data shows that our SP models achieve higher log-likelihood than the NP baselines, and also highlights important considerations for applying such techniques within the domain of social human interactions.
ReproducedPapers.org: Openly teaching and structuring machine learning reproducibility
Dec 01, 2020

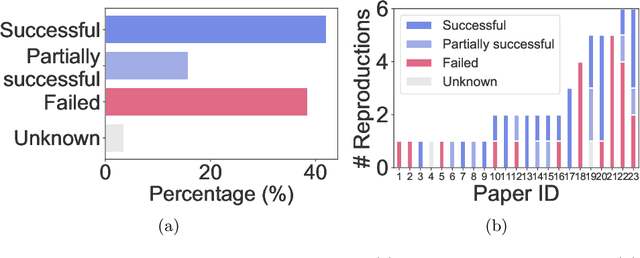
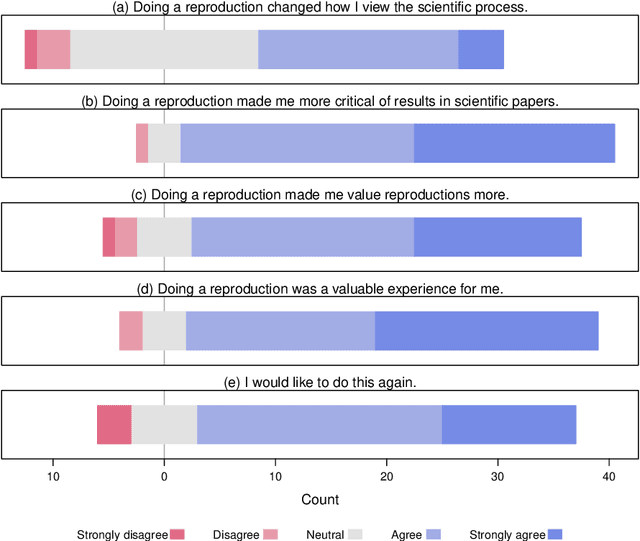
We present ReproducedPapers.org: an open online repository for teaching and structuring machine learning reproducibility. We evaluate doing a reproduction project among students and the added value of an online reproduction repository among AI researchers. We use anonymous self-assessment surveys and obtained 144 responses. Results suggest that students who do a reproduction project place more value on scientific reproductions and become more critical thinkers. Students and AI researchers agree that our online reproduction repository is valuable.
A Blast From the Past: Personalizing Predictions of Video-Induced Emotions using Personal Memories as Context
Aug 27, 2020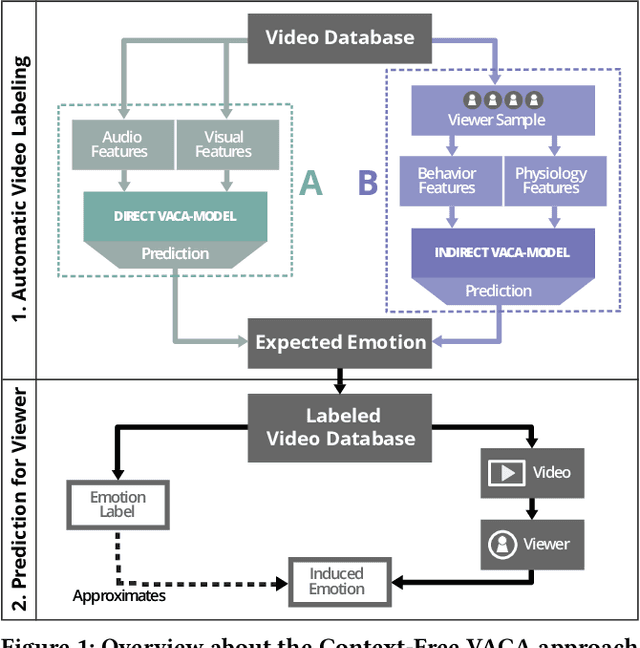
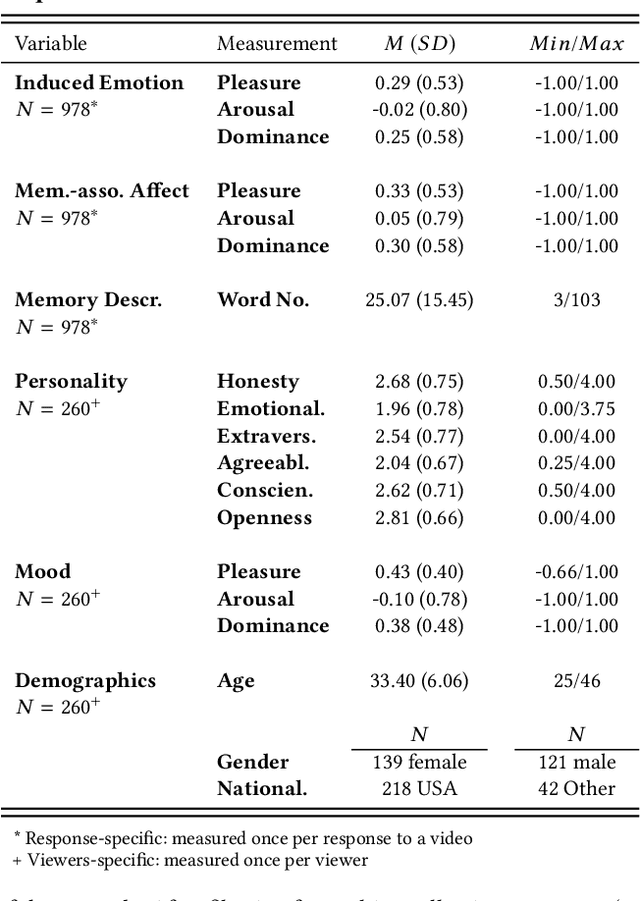
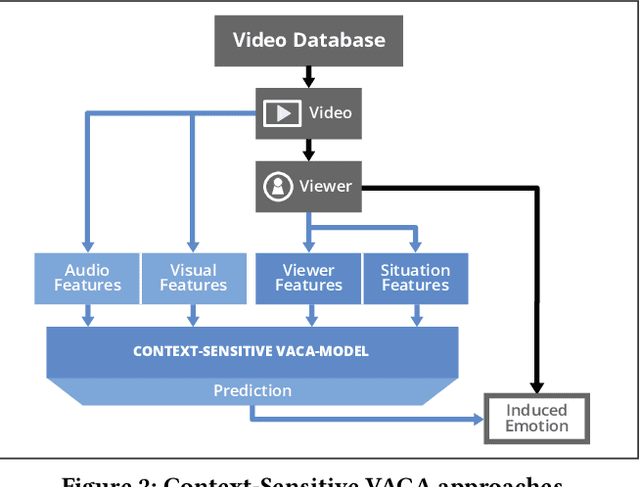

A key challenge in the accurate prediction of viewers' emotional responses to video stimuli in real-world applications is accounting for person- and situation-specific variation. An important contextual influence shaping individuals' subjective experience of a video is the personal memories that it triggers in them. Prior research has found that this memory influence explains more variation in video-induced emotions than other contextual variables commonly used for personalizing predictions, such as viewers' demographics or personality. In this article, we show that (1) automatic analysis of text describing their video-triggered memories can account for variation in viewers' emotional responses, and (2) that combining such an analysis with that of a video's audiovisual content enhances the accuracy of automatic predictions. We discuss the relevance of these findings for improving on state of the art approaches to automated affective video analysis in personalized contexts.