 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQini curve estimation under clustered network interference
Feb 27, 2025



Qini curves are a widely used tool for assessing treatment policies under allocation constraints as they visualize the incremental gain of a new treatment policy versus the cost of its implementation. Standard Qini curve estimation assumes no interference between units: that is, that treating one unit does not influence the outcome of any other unit. In many real-life applications such as public policy or marketing, however, the presence of interference is common. Ignoring interference in these scenarios can lead to systematically biased Qini curves that over- or under-estimate a treatment policy's cost-effectiveness. In this paper, we address the problem of Qini curve estimation under clustered network interference, where interfering units form independent clusters. We propose a formal description of the problem setting with an experimental study design under which we can account for clustered network interference. Within this framework, we introduce three different estimation strategies suited for different conditions. Moreover, we introduce a marketplace simulator that emulates clustered network interference in a typical e-commerce setting. From both theoretical and empirical insights, we provide recommendations in choosing the best estimation strategy by identifying an inherent bias-variance trade-off among the estimation strategies.
Falsification of Unconfoundedness by Testing Independence of Causal Mechanisms
Feb 10, 2025A major challenge in estimating treatment effects in observational studies is the reliance on untestable conditions such as the assumption of no unmeasured confounding. In this work, we propose an algorithm that can falsify the assumption of no unmeasured confounding in a setting with observational data from multiple heterogeneous sources, which we refer to as environments. Our proposed falsification strategy leverages a key observation that unmeasured confounding can cause observed causal mechanisms to appear dependent. Building on this observation, we develop a novel two-stage procedure that detects these dependencies with high statistical power while controlling false positives. The algorithm does not require access to randomized data and, in contrast to other falsification approaches, functions even under transportability violations when the environment has a direct effect on the outcome of interest. To showcase the practical relevance of our approach, we show that our method is able to efficiently detect confounding on both simulated and real-world data.
When accurate prediction models yield harmful self-fulfilling prophecies
Dec 06, 2023


Prediction models are popular in medical research and practice. By predicting an outcome of interest for specific patients, these models may help inform difficult treatment decisions, and are often hailed as the poster children for personalized, data-driven healthcare. We show however, that using prediction models for decision making can lead to harmful decisions, even when the predictions exhibit good discrimination after deployment. These models are harmful self-fulfilling prophecies: their deployment harms a group of patients but the worse outcome of these patients does not invalidate the predictive power of the model. Our main result is a formal characterization of a set of such prediction models. Next we show that models that are well calibrated before and after deployment are useless for decision making as they made no change in the data distribution. These results point to the need to revise standard practices for validation, deployment and evaluation of prediction models that are used in medical decisions.
Combining observational datasets from multiple environments to detect hidden confounding
May 27, 2022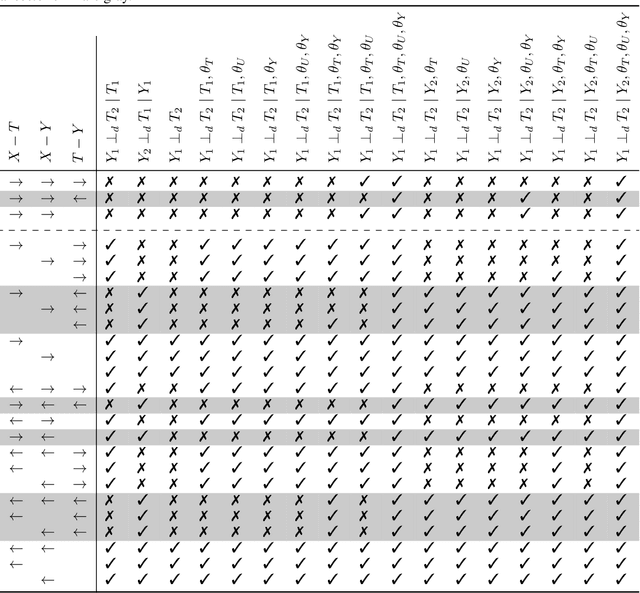
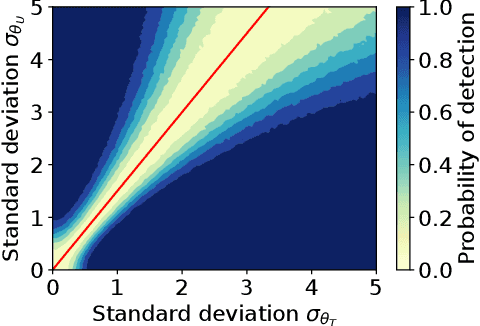
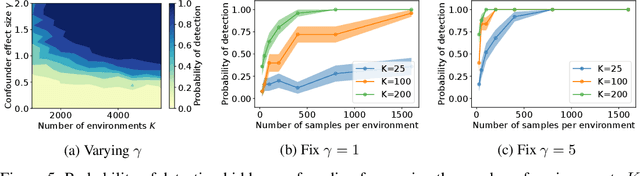
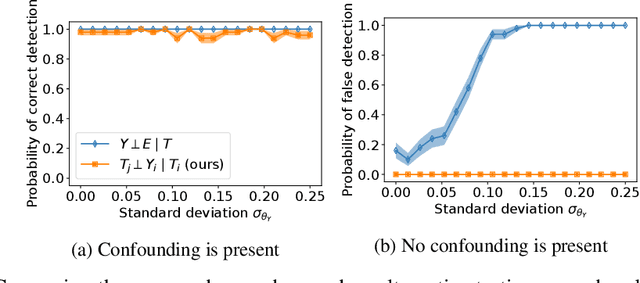
A common assumption in causal inference from observational data is the assumption of no hidden confounding. Yet it is, in general, impossible to verify the presence of hidden confounding factors from a single dataset. However, under the assumption of independent causal mechanisms underlying the data generative process, we demonstrate a way to detect unobserved confounders when having multiple observational datasets coming from different environments. We present a theory for testable conditional independencies that are only violated during hidden confounding and examine cases where we break its assumptions: degenerate & dependent mechanisms, and faithfulness violations. Additionally, we propose a procedure to test these independencies and study its empirical finite-sample behavior using simulation studies.
ReproducedPapers.org: Openly teaching and structuring machine learning reproducibility
Dec 01, 2020

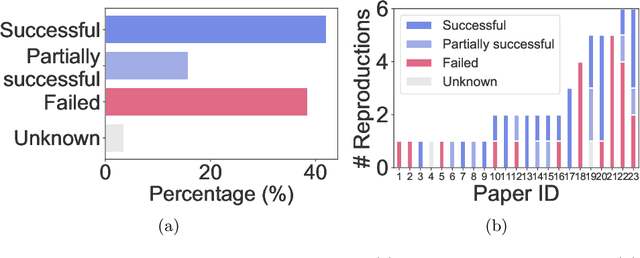
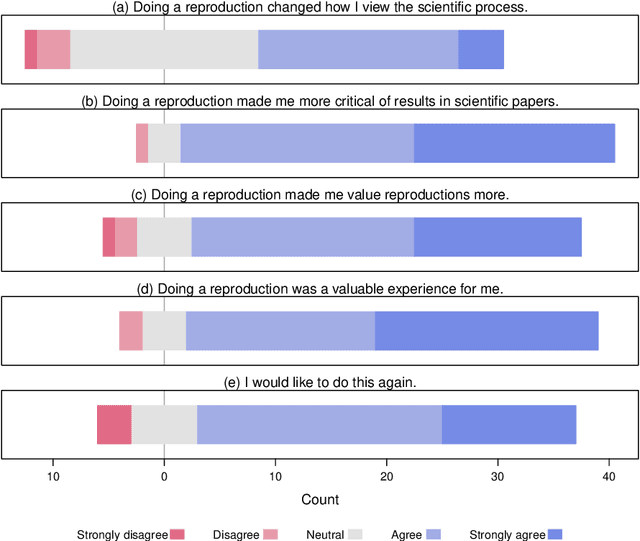
We present ReproducedPapers.org: an open online repository for teaching and structuring machine learning reproducibility. We evaluate doing a reproduction project among students and the added value of an online reproduction repository among AI researchers. We use anonymous self-assessment surveys and obtained 144 responses. Results suggest that students who do a reproduction project place more value on scientific reproductions and become more critical thinkers. Students and AI researchers agree that our online reproduction repository is valuable.
A Brief Prehistory of Double Descent
Apr 07, 2020In their thought-provoking paper [1], Belkin et al. illustrate and discuss the shape of risk curves in the context of modern high-complexity learners. Given a fixed training sample size $n$, such curves show the risk of a learner as a function of some (approximate) measure of its complexity $N$. With $N$ the number of features, these curves are also referred to as feature curves. A salient observation in [1] is that these curves can display, what they call, double descent: with increasing $N$, the risk initially decreases, attains a minimum, and then increases until $N$ equals $n$, where the training data is fitted perfectly. Increasing $N$ even further, the risk decreases a second and final time, creating a peak at $N=n$. This twofold descent may come as a surprise, but as opposed to what [1] reports, it has not been overlooked historically. Our letter draws attention to some original, earlier findings, of interest to contemporary machine learning.
The Pessimistic Limits and Possibilities of Margin-based Losses in Semi-supervised Learning
Oct 29, 2018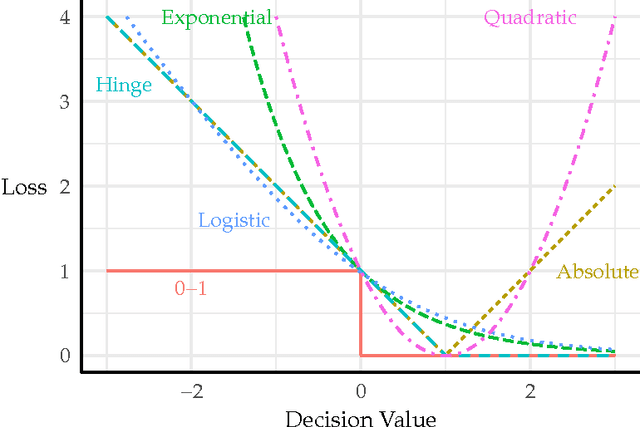

Consider a classification problem where we have both labeled and unlabeled data available. We show that for linear classifiers defined by convex margin-based surrogate losses that are decreasing, it is impossible to construct any semi-supervised approach that is able to guarantee an improvement over the supervised classifier measured by this surrogate loss on the labeled and unlabeled data. For convex margin-based loss functions that also increase, we demonstrate safe improvements are possible.
On Measuring and Quantifying Performance: Error Rates, Surrogate Loss, and an Example in SSL
Jul 13, 2017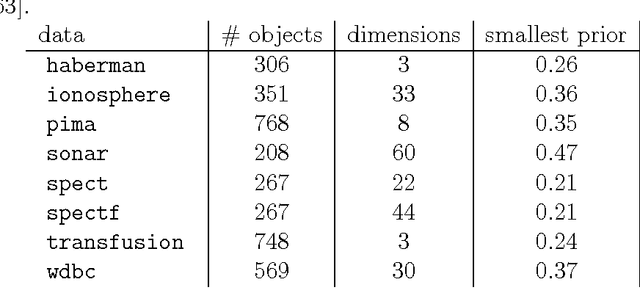


In various approaches to learning, notably in domain adaptation, active learning, learning under covariate shift, semi-supervised learning, learning with concept drift, and the like, one often wants to compare a baseline classifier to one or more advanced (or at least different) strategies. In this chapter, we basically argue that if such classifiers, in their respective training phases, optimize a so-called surrogate loss that it may also be valuable to compare the behavior of this loss on the test set, next to the regular classification error rate. It can provide us with an additional view on the classifiers' relative performances that error rates cannot capture. As an example, limited but convincing empirical results demonstrates that we may be able to find semi-supervised learning strategies that can guarantee performance improvements with increasing numbers of unlabeled data in terms of log-likelihood. In contrast, the latter may be impossible to guarantee for the classification error rate.
Nuclear Discrepancy for Active Learning
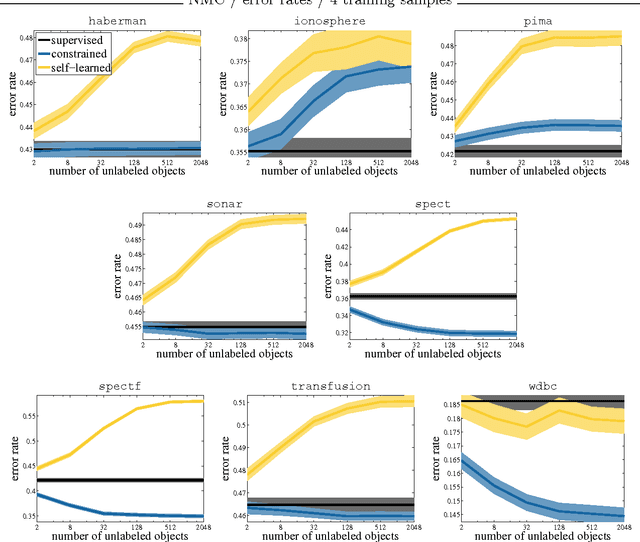
Jun 08, 2017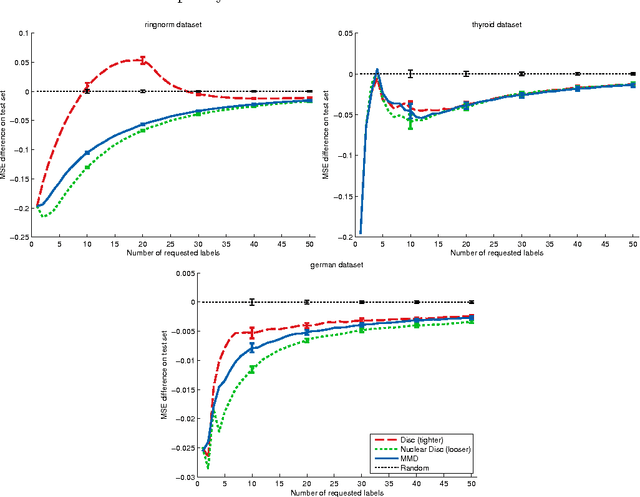
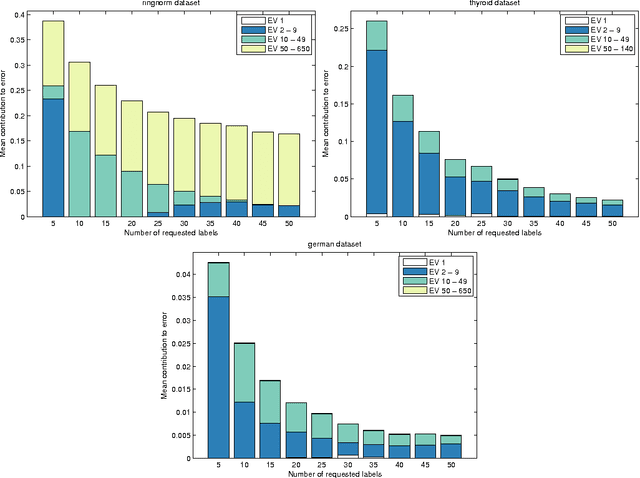
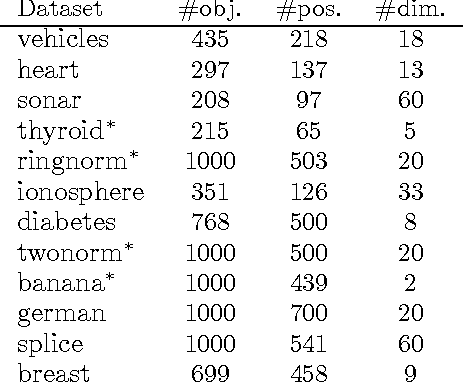

Active learning algorithms propose which unlabeled objects should be queried for their labels to improve a predictive model the most. We study active learners that minimize generalization bounds and uncover relationships between these bounds that lead to an improved approach to active learning. In particular we show the relation between the bound of the state-of-the-art Maximum Mean Discrepancy (MMD) active learner, the bound of the Discrepancy, and a new and looser bound that we refer to as the Nuclear Discrepancy bound. We motivate this bound by a probabilistic argument: we show it considers situations which are more likely to occur. Our experiments indicate that active learning using the tightest Discrepancy bound performs the worst in terms of the squared loss. Overall, our proposed loosest Nuclear Discrepancy generalization bound performs the best. We confirm our probabilistic argument empirically: the other bounds focus on more pessimistic scenarios that are rarer in practice. We conclude that tightness of bounds is not always of main importance and that active learning methods should concentrate on realistic scenarios in order to improve performance.
Robust Semi-supervised Least Squares Classification by Implicit Constraints
Jan 27, 2017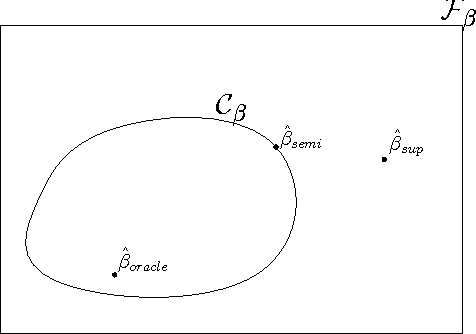
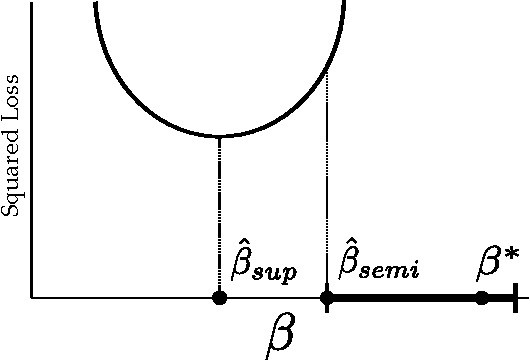

We introduce the implicitly constrained least squares (ICLS) classifier, a novel semi-supervised version of the least squares classifier. This classifier minimizes the squared loss on the labeled data among the set of parameters implied by all possible labelings of the unlabeled data. Unlike other discriminative semi-supervised methods, this approach does not introduce explicit additional assumptions into the objective function, but leverages implicit assumptions already present in the choice of the supervised least squares classifier. This method can be formulated as a quadratic programming problem and its solution can be found using a simple gradient descent procedure. We prove that, in a limited 1-dimensional setting, this approach never leads to performance worse than the supervised classifier. Experimental results show that also in the general multidimensional case performance improvements can be expected, both in terms of the squared loss that is intrinsic to the classifier, as well as in terms of the expected classification error.
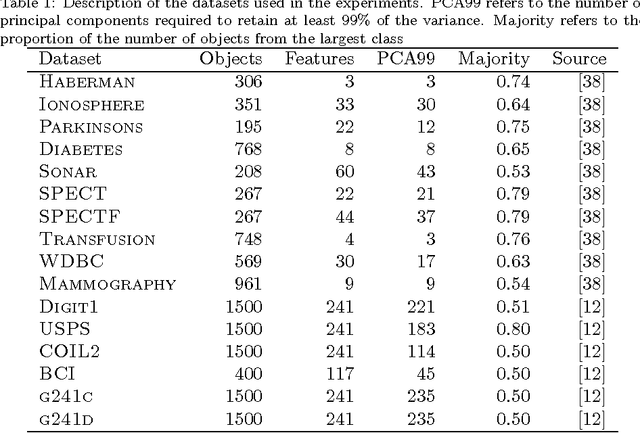
* Appeared as Pattern Recognition Volume 63, March 2017, Pages 115-126. This version of the manuscript fixes some typos in the equations on page 9 that are incorrect in the published version