 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Use or not to Use Muon: How Simplicity Bias in Optimizers Matters
Feb 28, 2026For a long period of time, Adam has served as the ubiquitous default choice for training deep neural networks. Recently, many new optimizers have been introduced, out of which Muon has perhaps gained the highest popularity due to its superior training speed. While many papers set out to validate the benefits of Muon, our paper investigates the potential downsides stemming from the mechanism driving this speedup. We explore the biases induced when optimizing with Muon, providing theoretical analysis and its consequences to the learning trajectories and solutions learned. While the theory does provide justification for the benefits Muon brings, it also guides our intuition when coming up with a couple of examples where Muon-optimized models have disadvantages. The core problem we emphasize is that Muon optimization removes a simplicity bias that is naturally preserved by older, more thoroughly studied methods like Stochastic Gradient Descent (SGD). We take first steps toward understanding consequences this may have: Muon might struggle to uncover common underlying structure across tasks, and be more prone to fitting spurious features. More broadly, this paper should serve as a reminder: when developing new optimizers, it is essential to consider the biases they introduce, as these biases can fundamentally change a model's behavior -- for better or for worse.
Attention and Compression is all you need for Controllably Efficient Language Models
Nov 07, 2025The quadratic cost of attention in transformers motivated the development of efficient approaches: namely sparse and sliding window attention, convolutions and linear attention. Although these approaches result in impressive reductions in compute and memory, they often trade-off with quality, specifically in-context recall performance. Moreover, apriori fixing this quality-compute tradeoff means being suboptimal from the get-go: some downstream applications require more memory for in-context recall, while others require lower latency and memory. Further, these approaches rely on heuristic choices that artificially restrict attention, or require handcrafted and complex recurrent state update rules, or they must be carefully composed with attention at specific layers to form a hybrid architecture that complicates the design process, especially at scale. To address above issues, we propose Compress & Attend Transformer (CAT), a conceptually simple architecture employing two simple ingredients only: dense attention and compression. CAT decodes chunks of tokens by attending to compressed chunks of the sequence so far. Compression results in decoding from a reduced sequence length that yields compute and memory savings, while choosing a particular chunk size trades-off quality for efficiency. Moreover, CAT can be trained with multiple chunk sizes at once, unlocking control of quality-compute trade-offs directly at test-time without any retraining, all in a single adaptive architecture. In exhaustive evaluations on common language modeling tasks, in-context recall, and long-context understanding, a single adaptive CAT model outperforms existing efficient baselines, including hybrid architectures, across different compute-memory budgets. Further, a single CAT matches dense transformer in language modeling across model scales while being 1.4-3x faster and requiring 2-9x lower total memory usage.
KL-Regularized Reinforcement Learning is Designed to Mode Collapse
Oct 23, 2025It is commonly believed that optimizing the reverse KL divergence results in "mode seeking", while optimizing forward KL results in "mass covering", with the latter being preferred if the goal is to sample from multiple diverse modes. We show -- mathematically and empirically -- that this intuition does not necessarily transfer well to doing reinforcement learning with reverse/forward KL regularization (e.g. as commonly used with language models). Instead, the choice of reverse/forward KL determines the family of optimal target distributions, parameterized by the regularization coefficient. Mode coverage depends primarily on other factors, such as regularization strength, and relative scales between rewards and reference probabilities. Further, we show commonly used settings such as low regularization strength and equal verifiable rewards tend to specify unimodal target distributions, meaning the optimization objective is, by construction, non-diverse. We leverage these insights to construct a simple, scalable, and theoretically justified algorithm. It makes minimal changes to reward magnitudes, yet optimizes for a target distribution which puts high probability over all high-quality sampling modes. In experiments, this simple modification works to post-train both Large Language Models and Chemical Language Models to have higher solution quality and diversity, without any external signals of diversity, and works with both forward and reverse KL when using either naively fails.
Time After Time: Deep-Q Effect Estimation for Interventions on When and What to do
Mar 20, 2025



Problems in fields such as healthcare, robotics, and finance requires reasoning about the value both of what decision or action to take and when to take it. The prevailing hope is that artificial intelligence will support such decisions by estimating the causal effect of policies such as how to treat patients or how to allocate resources over time. However, existing methods for estimating the effect of a policy struggle with \emph{irregular time}. They either discretize time, or disregard the effect of timing policies. We present a new deep-Q algorithm that estimates the effect of both when and what to do called Earliest Disagreement Q-Evaluation (EDQ). EDQ makes use of recursion for the Q-function that is compatible with flexible sequence models, such as transformers. EDQ provides accurate estimates under standard assumptions. We validate the approach through experiments on survival time and tumor growth tasks.
Black Box Causal Inference: Effect Estimation via Meta Prediction
Mar 07, 2025



Causal inference and the estimation of causal effects plays a central role in decision-making across many areas, including healthcare and economics. Estimating causal effects typically requires an estimator that is tailored to each problem of interest. But developing estimators can take significant effort for even a single causal inference setting. For example, algorithms for regression-based estimators, propensity score methods, and doubly robust methods were designed across several decades to handle causal estimation with observed confounders. Similarly, several estimators have been developed to exploit instrumental variables (IVs), including two-stage least-squares (TSLS), control functions, and the method-of-moments. In this work, we instead frame causal inference as a dataset-level prediction problem, offloading algorithm design to the learning process. The approach we introduce, called black box causal inference (BBCI), builds estimators in a black-box manner by learning to predict causal effects from sampled dataset-effect pairs. We demonstrate accurate estimation of average treatment effects (ATEs) and conditional average treatment effects (CATEs) with BBCI across several causal inference problems with known identification, including problems with less developed estimators.
A General Framework for Inference-time Scaling and Steering of Diffusion Models
Jan 16, 2025



Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
Explanations that reveal all through the definition of encoding
Nov 04, 2024



Feature attributions attempt to highlight what inputs drive predictive power. Good attributions or explanations are thus those that produce inputs that retain this predictive power; accordingly, evaluations of explanations score their quality of prediction. However, evaluations produce scores better than what appears possible from the values in the explanation for a class of explanations, called encoding explanations. Probing for encoding remains a challenge because there is no general characterization of what gives the extra predictive power. We develop a definition of encoding that identifies this extra predictive power via conditional dependence and show that the definition fits existing examples of encoding. This definition implies, in contrast to encoding explanations, that non-encoding explanations contain all the informative inputs used to produce the explanation, giving them a "what you see is what you get" property, which makes them transparent and simple to use. Next, we prove that existing scores (ROAR, FRESH, EVAL-X) do not rank non-encoding explanations above encoding ones, and develop STRIPE-X which ranks them correctly. After empirically demonstrating the theoretical insights, we use STRIPE-X to uncover encoding in LLM-generated explanations for predicting the sentiment in movie reviews.
* 35 pages, 7 figures, 6 tables, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Contrasting with Symile: Simple Model-Agnostic Representation Learning for Unlimited Modalities
Nov 01, 2024



Contrastive learning methods, such as CLIP, leverage naturally paired data-for example, images and their corresponding text captions-to learn general representations that transfer efficiently to downstream tasks. While such approaches are generally applied to two modalities, domains such as robotics, healthcare, and video need to support many types of data at once. We show that the pairwise application of CLIP fails to capture joint information between modalities, thereby limiting the quality of the learned representations. To address this issue, we present Symile, a simple contrastive learning approach that captures higher-order information between any number of modalities. Symile provides a flexible, architecture-agnostic objective for learning modality-specific representations. To develop Symile's objective, we derive a lower bound on total correlation, and show that Symile representations for any set of modalities form a sufficient statistic for predicting the remaining modalities. Symile outperforms pairwise CLIP, even with modalities missing in the data, on cross-modal classification and retrieval across several experiments including on an original multilingual dataset of 33M image, text and audio samples and a clinical dataset of chest X-rays, electrocardiograms, and laboratory measurements. All datasets and code used in this work are publicly available at https://github.com/rajesh-lab/symile.
What's the score? Automated Denoising Score Matching for Nonlinear Diffusions
Jul 10, 2024

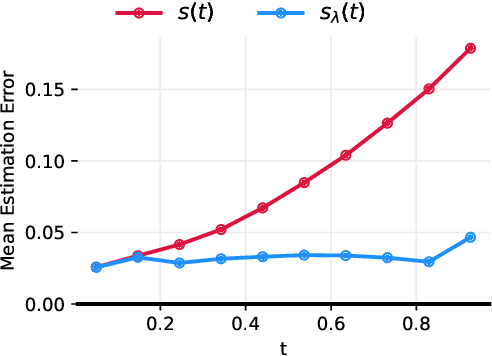
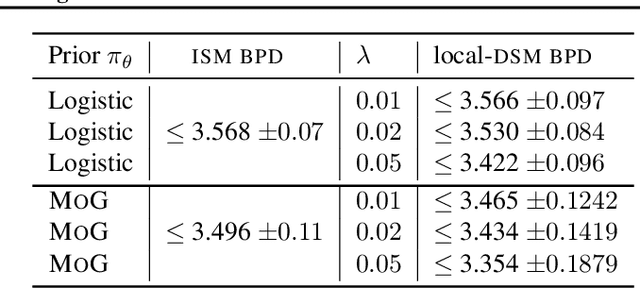
Reversing a diffusion process by learning its score forms the heart of diffusion-based generative modeling and for estimating properties of scientific systems. The diffusion processes that are tractable center on linear processes with a Gaussian stationary distribution. This limits the kinds of models that can be built to those that target a Gaussian prior or more generally limits the kinds of problems that can be generically solved to those that have conditionally linear score functions. In this work, we introduce a family of tractable denoising score matching objectives, called local-DSM, built using local increments of the diffusion process. We show how local-DSM melded with Taylor expansions enables automated training and score estimation with nonlinear diffusion processes. To demonstrate these ideas, we use automated-DSM to train generative models using non-Gaussian priors on challenging low dimensional distributions and the CIFAR10 image dataset. Additionally, we use the automated-DSM to learn the scores for nonlinear processes studied in statistical physics.
Towards Minimal Targeted Updates of Language Models with Targeted Negative Training
Jun 19, 2024
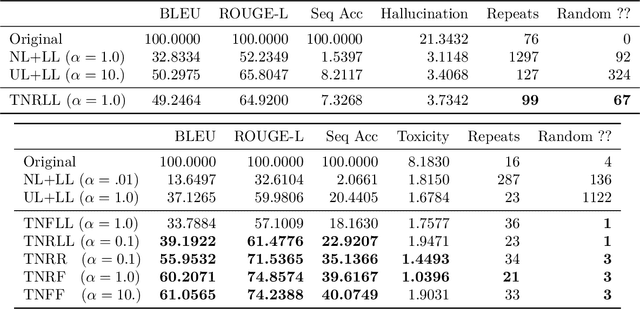
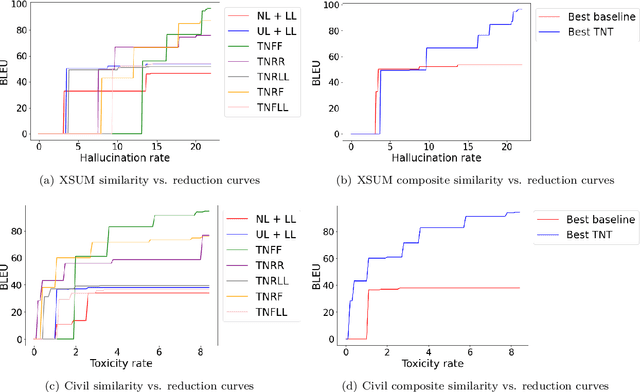
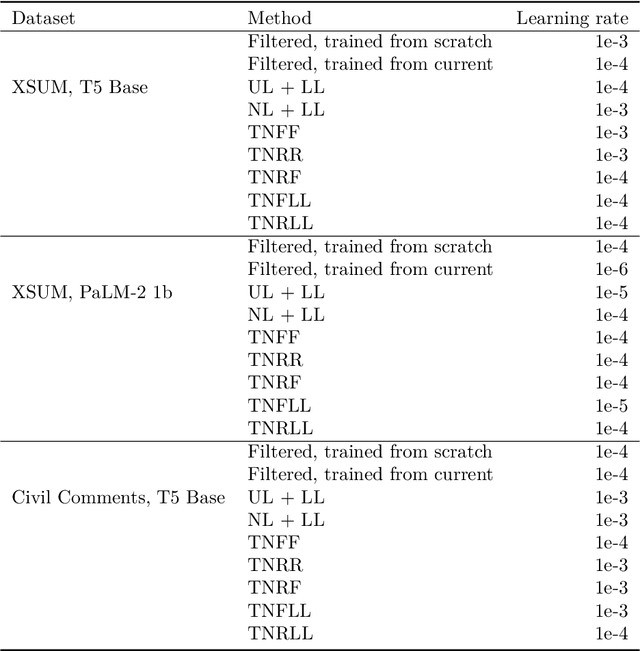
Generative models of language exhibit impressive capabilities but still place non-negligible probability mass over undesirable outputs. In this work, we address the task of updating a model to avoid unwanted outputs while minimally changing model behavior otherwise, a challenge we refer to as a minimal targeted update. We first formalize the notion of a minimal targeted update and propose a method to achieve such updates using negative examples from a model's generations. Our proposed Targeted Negative Training (TNT) results in updates that keep the new distribution close to the original, unlike existing losses for negative signal which push down probability but do not control what the updated distribution will be. In experiments, we demonstrate that TNT yields a better trade-off between reducing unwanted behavior and maintaining model generation behavior than baselines, paving the way towards a modeling paradigm based on iterative training updates that constrain models from generating undesirable outputs while preserving their impressive capabilities.