 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Control for Guidance in Diffusion Models
Feb 06, 2025



Diffusion models exhibit excellent sample quality, but existing guidance methods often require additional model training or are limited to specific tasks. We revisit guidance in diffusion models from the perspective of variational inference and control, introducing Diffusion Trajectory Matching (DTM) that enables guiding pretrained diffusion trajectories to satisfy a terminal cost. DTM unifies a broad class of guidance methods and enables novel instantiations. We introduce a new method within this framework that achieves state-of-the-art results on several linear and (blind) non-linear inverse problems without requiring additional model training or modifications. For instance, in ImageNet non-linear deblurring, our model achieves an FID score of 34.31, significantly improving over the best pretrained-method baseline (FID 78.07). We will make the code available in a future update.
Heavy-Tailed Diffusion Models
Oct 18, 2024Diffusion models achieve state-of-the-art generation quality across many applications, but their ability to capture rare or extreme events in heavy-tailed distributions remains unclear. In this work, we show that traditional diffusion and flow-matching models with standard Gaussian priors fail to capture heavy-tailed behavior. We address this by repurposing the diffusion framework for heavy-tail estimation using multivariate Student-t distributions. We develop a tailored perturbation kernel and derive the denoising posterior based on the conditional Student-t distribution for the backward process. Inspired by $\gamma$-divergence for heavy-tailed distributions, we derive a training objective for heavy-tailed denoisers. The resulting framework introduces controllable tail generation using only a single scalar hyperparameter, making it easily tunable for diverse real-world distributions. As specific instantiations of our framework, we introduce t-EDM and t-Flow, extensions of existing diffusion and flow models that employ a Student-t prior. Remarkably, our approach is readily compatible with standard Gaussian diffusion models and requires only minimal code changes. Empirically, we show that our t-EDM and t-Flow outperform standard diffusion models in heavy-tail estimation on high-resolution weather datasets in which generating rare and extreme events is crucial.
Fast Samplers for Inverse Problems in Iterative Refinement Models
May 27, 2024

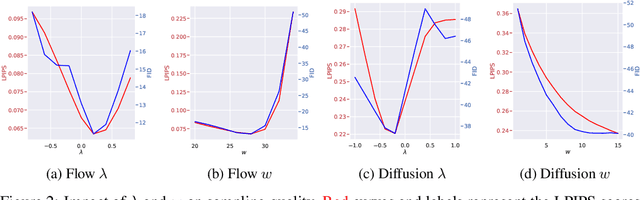
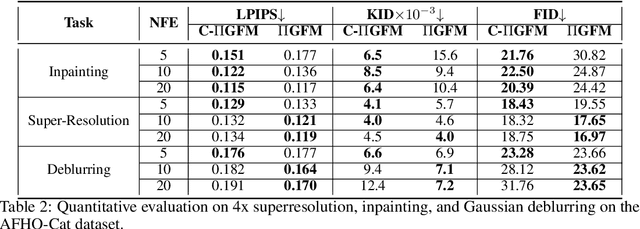
Constructing fast samplers for unconditional diffusion and flow-matching models has received much attention recently; however, existing methods for solving inverse problems, such as super-resolution, inpainting, or deblurring, still require hundreds to thousands of iterative steps to obtain high-quality results. We propose a plug-and-play framework for constructing efficient samplers for inverse problems, requiring only pre-trained diffusion or flow-matching models. We present Conditional Conjugate Integrators, which leverage the specific form of the inverse problem to project the respective conditional diffusion/flow dynamics into a more amenable space for sampling. Our method complements popular posterior approximation methods for solving inverse problems using diffusion/flow models. We evaluate the proposed method's performance on various linear image restoration tasks across multiple datasets, employing diffusion and flow-matching models. Notably, on challenging inverse problems like 4$\times$ super-resolution on the ImageNet dataset, our method can generate high-quality samples in as few as 5 conditional sampling steps and outperforms competing baselines requiring 20-1000 steps. Our code and models will be publicly available at https://github.com/mandt-lab/CI2RM.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Towards Fast Stochastic Sampling in Diffusion Generative Models
Feb 13, 2024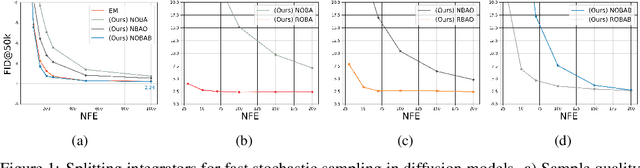



Diffusion models suffer from slow sample generation at inference time. Despite recent efforts, improving the sampling efficiency of stochastic samplers for diffusion models remains a promising direction. We propose Splitting Integrators for fast stochastic sampling in pre-trained diffusion models in augmented spaces. Commonly used in molecular dynamics, splitting-based integrators attempt to improve sampling efficiency by cleverly alternating between numerical updates involving the data, auxiliary, or noise variables. However, we show that a naive application of splitting integrators is sub-optimal for fast sampling. Consequently, we propose several principled modifications to naive splitting samplers for improving sampling efficiency and denote the resulting samplers as Reduced Splitting Integrators. In the context of Phase Space Langevin Diffusion (PSLD) [Pandey \& Mandt, 2023] on CIFAR-10, our stochastic sampler achieves an FID score of 2.36 in only 100 network function evaluations (NFE) as compared to 2.63 for the best baselines.
Efficient Integrators for Diffusion Generative Models
Oct 11, 2023



Diffusion models suffer from slow sample generation at inference time. Therefore, developing a principled framework for fast deterministic/stochastic sampling for a broader class of diffusion models is a promising direction. We propose two complementary frameworks for accelerating sample generation in pre-trained models: Conjugate Integrators and Splitting Integrators. Conjugate integrators generalize DDIM, mapping the reverse diffusion dynamics to a more amenable space for sampling. In contrast, splitting-based integrators, commonly used in molecular dynamics, reduce the numerical simulation error by cleverly alternating between numerical updates involving the data and auxiliary variables. After extensively studying these methods empirically and theoretically, we present a hybrid method that leads to the best-reported performance for diffusion models in augmented spaces. Applied to Phase Space Langevin Diffusion [Pandey & Mandt, 2023] on CIFAR-10, our deterministic and stochastic samplers achieve FID scores of 2.11 and 2.36 in only 100 network function evaluations (NFE) as compared to 2.57 and 2.63 for the best-performing baselines, respectively. Our code and model checkpoints will be made publicly available at \url{https://github.com/mandt-lab/PSLD}.
Generative Diffusions in Augmented Spaces: A Complete Recipe
Mar 03, 2023



Score-based Generative Models (SGMs) have achieved state-of-the-art synthesis results on diverse tasks. However, the current design space of the forward diffusion process is largely unexplored and often relies on physical intuition or simplifying assumptions. Leveraging results from the design of scalable Bayesian posterior samplers, we present a complete recipe for constructing forward processes in SGMs, all of which are guaranteed to converge to the target distribution of interest. We show that several existing SGMs can be cast as specific instantiations of this parameterization. Furthermore, building on this recipe, we construct a novel SGM: Phase Space Langevin Diffusion (PSLD), which performs score-based modeling in a space augmented with auxiliary variables akin to a physical phase space. We show that PSLD outperforms competing baselines in terms of sample quality and the speed-vs-quality tradeoff across different samplers on various standard image synthesis benchmarks. Moreover, we show that PSLD achieves sample quality comparable to state-of-the-art SGMs (FID: 2.10 on unconditional CIFAR-10 generation), providing an attractive alternative as an SGM backbone for further development. We will publish our code and model checkpoints for reproducibility at https://github.com/mandt-lab/PSLD.
DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
Jan 02, 2022

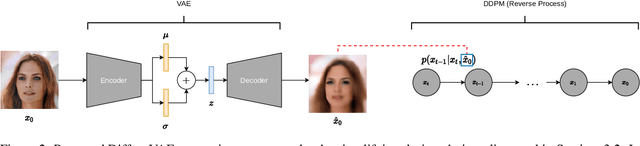
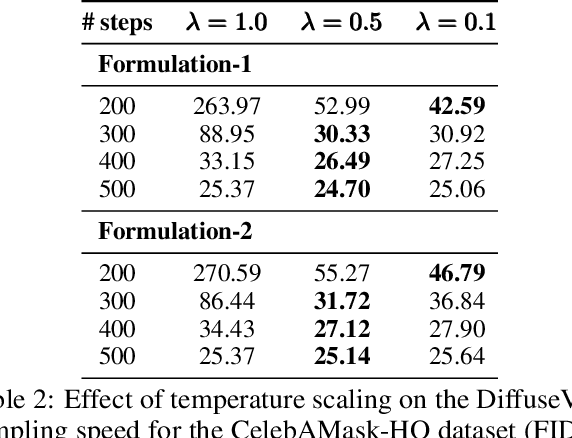
Diffusion Probabilistic models have been shown to generate state-of-the-art results on several competitive image synthesis benchmarks but lack a low-dimensional, interpretable latent space, and are slow at generation. On the other hand, Variational Autoencoders (VAEs) typically have access to a low-dimensional latent space but exhibit poor sample quality. Despite recent advances, VAEs usually require high-dimensional hierarchies of the latent codes to generate high-quality samples. We present DiffuseVAE, a novel generative framework that integrates VAE within a diffusion model framework, and leverage this to design a novel conditional parameterization for diffusion models. We show that the resulting model can improve upon the unconditional diffusion model in terms of sampling efficiency while also equipping diffusion models with the low-dimensional VAE inferred latent code. Furthermore, we show that the proposed model can generate high-resolution samples and exhibits synthesis quality comparable to state-of-the-art models on standard benchmarks. Lastly, we show that the proposed method can be used for controllable image synthesis and also exhibits out-of-the-box capabilities for downstream tasks like image super-resolution and denoising. For reproducibility, our source code is publicly available at \url{https://github.com/kpandey008/DiffuseVAE}.