 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Scaling Techniques in Theoretical Physics -- A Comparison of Methods on the TPBench Dataset
Jun 25, 2025Large language models (LLMs) have shown strong capabilities in complex reasoning, and test-time scaling techniques can enhance their performance with comparably low cost. Many of these methods have been developed and evaluated on mathematical reasoning benchmarks such as AIME. This paper investigates whether the lessons learned from these benchmarks generalize to the domain of advanced theoretical physics. We evaluate a range of common test-time scaling methods on the TPBench physics dataset and compare their effectiveness with results on AIME. To better leverage the structure of physics problems, we develop a novel, symbolic weak-verifier framework to improve parallel scaling results. Our empirical results demonstrate that this method significantly outperforms existing test-time scaling approaches on TPBench. We also evaluate our method on AIME, confirming its effectiveness in solving advanced mathematical problems. Our findings highlight the power of step-wise symbolic verification for tackling complex scientific problems.
Theoretical Physics Benchmark (TPBench) -- a Dataset and Study of AI Reasoning Capabilities in Theoretical Physics
Feb 19, 2025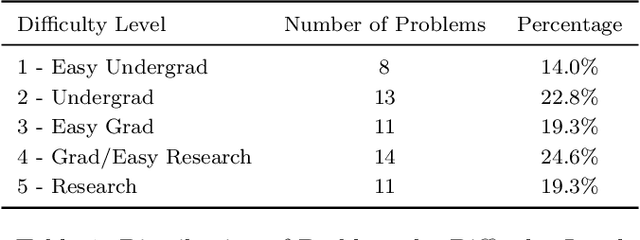
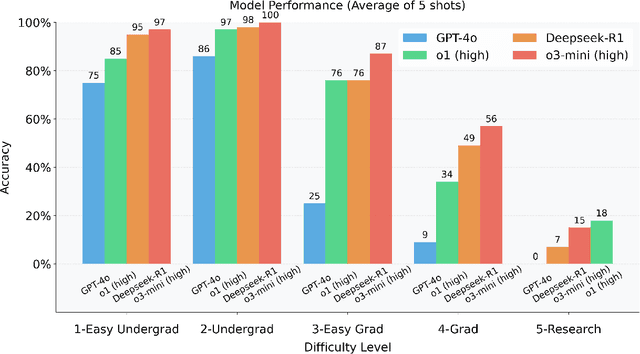
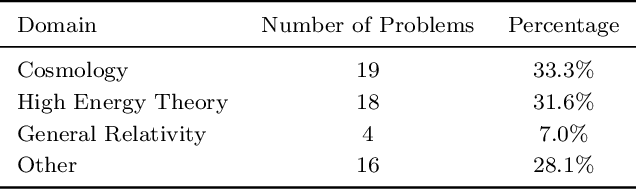
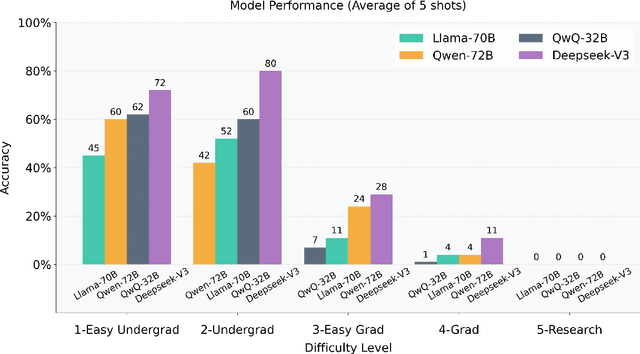
We introduce a benchmark to evaluate the capability of AI to solve problems in theoretical physics, focusing on high-energy theory and cosmology. The first iteration of our benchmark consists of 57 problems of varying difficulty, from undergraduate to research level. These problems are novel in the sense that they do not come from public problem collections. We evaluate our data set on various open and closed language models, including o3-mini, o1, DeepSeek-R1, GPT-4o and versions of Llama and Qwen. While we find impressive progress in model performance with the most recent models, our research-level difficulty problems are mostly unsolved. We address challenges of auto-verifiability and grading, and discuss common failure modes. While currently state-of-the art models are still of limited use for researchers, our results show that AI assisted theoretical physics research may become possible in the near future. We discuss the main obstacles towards this goal and possible strategies to overcome them. The public problems and solutions, results for various models, and updates to the data set and score distribution, are available on the website of the dataset tpbench.org.
Anomaly Detection of Tabular Data Using LLMs
Jun 24, 2024Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Uncertainty-aware Evaluation of Auxiliary Anomalies with the Expected Anomaly Posterior
May 22, 2024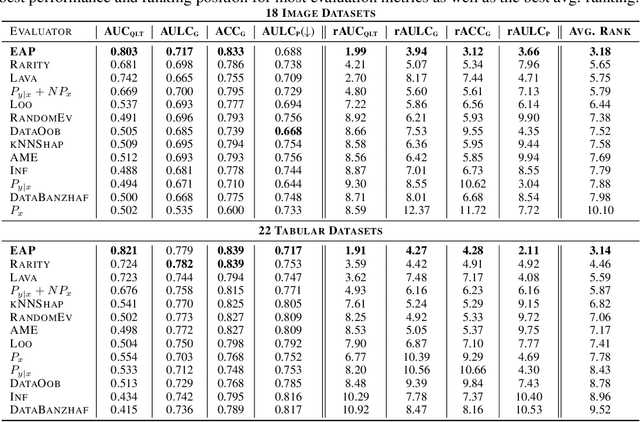
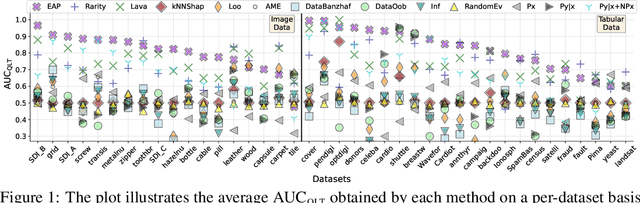
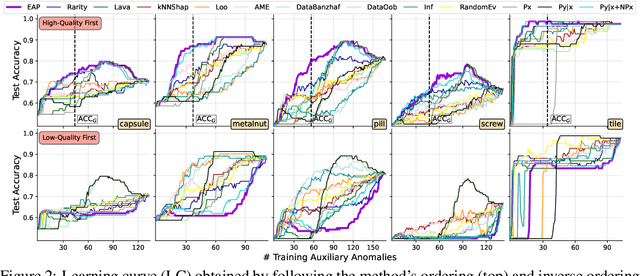
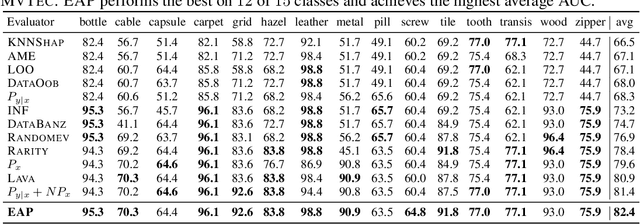
Anomaly detection is the task of identifying examples that do not behave as expected. Because anomalies are rare and unexpected events, collecting real anomalous examples is often challenging in several applications. In addition, learning an anomaly detector with limited (or no) anomalies often yields poor prediction performance. One option is to employ auxiliary synthetic anomalies to improve the model training. However, synthetic anomalies may be of poor quality: anomalies that are unrealistic or indistinguishable from normal samples may deteriorate the detector's performance. Unfortunately, no existing methods quantify the quality of auxiliary anomalies. We fill in this gap and propose the expected anomaly posterior (EAP), an uncertainty-based score function that measures the quality of auxiliary anomalies by quantifying the total uncertainty of an anomaly detector. Experimentally on 40 benchmark datasets of images and tabular data, we show that EAP outperforms 12 adapted data quality estimators in the majority of cases.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Towards Fast Stochastic Sampling in Diffusion Generative Models
Feb 13, 2024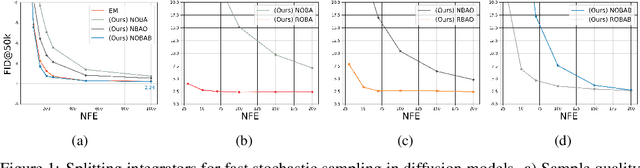



Diffusion models suffer from slow sample generation at inference time. Despite recent efforts, improving the sampling efficiency of stochastic samplers for diffusion models remains a promising direction. We propose Splitting Integrators for fast stochastic sampling in pre-trained diffusion models in augmented spaces. Commonly used in molecular dynamics, splitting-based integrators attempt to improve sampling efficiency by cleverly alternating between numerical updates involving the data, auxiliary, or noise variables. However, we show that a naive application of splitting integrators is sub-optimal for fast sampling. Consequently, we propose several principled modifications to naive splitting samplers for improving sampling efficiency and denote the resulting samplers as Reduced Splitting Integrators. In the context of Phase Space Langevin Diffusion (PSLD) [Pandey \& Mandt, 2023] on CIFAR-10, our stochastic sampler achieves an FID score of 2.36 in only 100 network function evaluations (NFE) as compared to 2.63 for the best baselines.
Hybrid Modeling Design Patterns
Dec 29, 2023Design patterns provide a systematic way to convey solutions to recurring modeling challenges. This paper introduces design patterns for hybrid modeling, an approach that combines modeling based on first principles with data-driven modeling techniques. While both approaches have complementary advantages there are often multiple ways to combine them into a hybrid model, and the appropriate solution will depend on the problem at hand. In this paper, we provide four base patterns that can serve as blueprints for combining data-driven components with domain knowledge into a hybrid approach. In addition, we also present two composition patterns that govern the combination of the base patterns into more complex hybrid models. Each design pattern is illustrated by typical use cases from application areas such as climate modeling, engineering, and physics.
Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data
Oct 16, 2023



Anomaly detection requires detecting abnormal samples in large unlabeled datasets. While progress in deep learning and the advent of foundation models has produced powerful unsupervised anomaly detection methods, their deployment in practice is often hindered by the lack of labeled data -- without it, the detection accuracy of an anomaly detector cannot be evaluated reliably. In this work, we propose a general-purpose framework for evaluating image-based anomaly detectors with synthetically generated validation data. Our method assumes access to a small support set of normal images which are processed with a pre-trained diffusion model (our proposed method requires no training or fine-tuning) to produce synthetic anomalies. When mixed with normal samples from the support set, the synthetic anomalies create detection tasks that compose a validation framework for anomaly detection evaluation and model selection. In an extensive empirical study, ranging from natural images to industrial applications, we find that our synthetic validation framework selects the same models and hyper-parameters as selection with a ground-truth validation set. In addition, we find that prompts selected by our method for CLIP-based anomaly detection outperforms all other prompt selection strategies, and leads to the overall best detection accuracy, even on the challenging MVTec-AD dataset.
Efficient Integrators for Diffusion Generative Models
Oct 11, 2023



Diffusion models suffer from slow sample generation at inference time. Therefore, developing a principled framework for fast deterministic/stochastic sampling for a broader class of diffusion models is a promising direction. We propose two complementary frameworks for accelerating sample generation in pre-trained models: Conjugate Integrators and Splitting Integrators. Conjugate integrators generalize DDIM, mapping the reverse diffusion dynamics to a more amenable space for sampling. In contrast, splitting-based integrators, commonly used in molecular dynamics, reduce the numerical simulation error by cleverly alternating between numerical updates involving the data and auxiliary variables. After extensively studying these methods empirically and theoretically, we present a hybrid method that leads to the best-reported performance for diffusion models in augmented spaces. Applied to Phase Space Langevin Diffusion [Pandey & Mandt, 2023] on CIFAR-10, our deterministic and stochastic samplers achieve FID scores of 2.11 and 2.36 in only 100 network function evaluations (NFE) as compared to 2.57 and 2.63 for the best-performing baselines, respectively. Our code and model checkpoints will be made publicly available at \url{https://github.com/mandt-lab/PSLD}.
LoRA ensembles for large language model fine-tuning
Oct 04, 2023



Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.