 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization, Generalization and Differential Privacy Bounds for Gradient Descent on Kolmogorov-Arnold Networks
Jan 29, 2026Kolmogorov--Arnold Networks (KANs) have recently emerged as a structured alternative to standard MLPs, yet a principled theory for their training dynamics, generalization, and privacy properties remains limited. In this paper, we analyze gradient descent (GD) for training two-layer KANs and derive general bounds that characterize their training dynamics, generalization, and utility under differential privacy (DP). As a concrete instantiation, we specialize our analysis to logistic loss under an NTK-separable assumption, where we show that polylogarithmic network width suffices for GD to achieve an optimization rate of order $1/T$ and a generalization rate of order $1/n$, with $T$ denoting the number of GD iterations and $n$ the sample size. In the private setting, we characterize the noise required for $(ε,δ)$-DP and obtain a utility bound of order $\sqrt{d}/(nε)$ (with $d$ the input dimension), matching the classical lower bound for general convex Lipschitz problems. Our results imply that polylogarithmic width is not only sufficient but also necessary under differential privacy, revealing a qualitative gap between non-private (sufficiency only) and private (necessity also emerges) training regimes. Experiments further illustrate how these theoretical insights can guide practical choices, including network width selection and early stopping.
AI-based Anomaly Detection for Clinical-Grade Histopathological Diagnostics
Jun 21, 2024



While previous studies have demonstrated the potential of AI to diagnose diseases in imaging data, clinical implementation is still lagging behind. This is partly because AI models require training with large numbers of examples only available for common diseases. In clinical reality, however, only few diseases are common, whereas the majority of diseases are less frequent (long-tail distribution). Current AI models overlook or misclassify these diseases. We propose a deep anomaly detection approach that only requires training data from common diseases to detect also all less frequent diseases. We collected two large real-world datasets of gastrointestinal biopsies, which are prototypical of the problem. Herein, the ten most common findings account for approximately 90% of cases, whereas the remaining 10% contained 56 disease entities, including many cancers. 17 million histological images from 5,423 cases were used for training and evaluation. Without any specific training for the diseases, our best-performing model reliably detected a broad spectrum of infrequent ("anomalous") pathologies with 95.0% (stomach) and 91.0% (colon) AUROC and generalized across scanners and hospitals. By design, the proposed anomaly detection can be expected to detect any pathological alteration in the diagnostic tail of gastrointestinal biopsies, including rare primary or metastatic cancers. This study establishes the first effective clinical application of AI-based anomaly detection in histopathology that can flag anomalous cases, facilitate case prioritization, reduce missed diagnoses and enhance the general safety of AI models, thereby driving AI adoption and automation in routine diagnostics and beyond.
Interpretable Tensor Fusion
May 07, 2024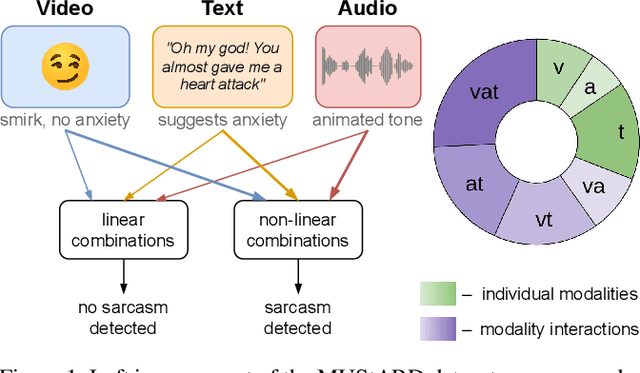
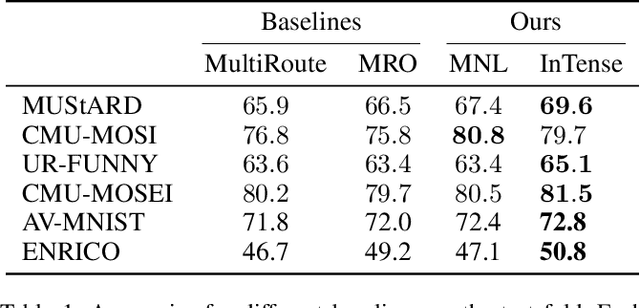
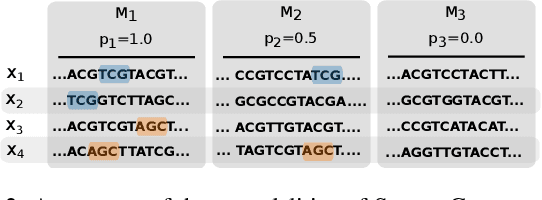
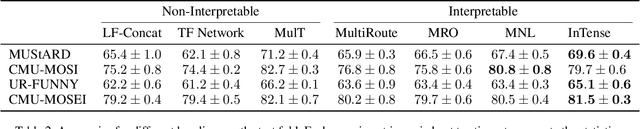
Conventional machine learning methods are predominantly designed to predict outcomes based on a single data type. However, practical applications may encompass data of diverse types, such as text, images, and audio. We introduce interpretable tensor fusion (InTense), a multimodal learning method for training neural networks to simultaneously learn multimodal data representations and their interpretable fusion. InTense can separately capture both linear combinations and multiplicative interactions of diverse data types, thereby disentangling higher-order interactions from the individual effects of each modality. InTense provides interpretability out of the box by assigning relevance scores to modalities and their associations. The approach is theoretically grounded and yields meaningful relevance scores on multiple synthetic and real-world datasets. Experiments on six real-world datasets show that InTense outperforms existing state-of-the-art multimodal interpretable approaches in terms of accuracy and interpretability.
Reimagining Anomalies: What If Anomalies Were Normal?
Feb 22, 2024Deep learning-based methods have achieved a breakthrough in image anomaly detection, but their complexity introduces a considerable challenge to understanding why an instance is predicted to be anomalous. We introduce a novel explanation method that generates multiple counterfactual examples for each anomaly, capturing diverse concepts of anomalousness. A counterfactual example is a modification of the anomaly that is perceived as normal by the anomaly detector. The method provides a high-level semantic explanation of the mechanism that triggered the anomaly detector, allowing users to explore "what-if scenarios." Qualitative and quantitative analyses across various image datasets show that the method applied to state-of-the-art anomaly detectors can achieve high-quality semantic explanations of detectors.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.
Exposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images
May 23, 2022

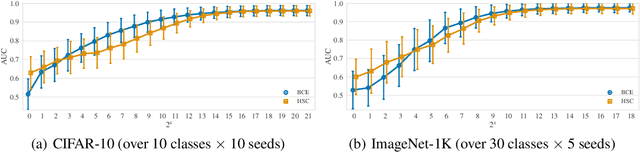
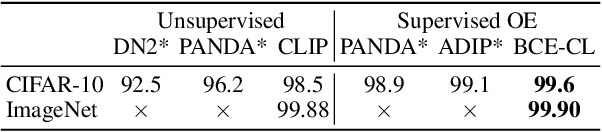
Traditionally anomaly detection (AD) is treated as an unsupervised problem utilizing only normal samples due to the intractability of characterizing everything that looks unlike the normal data. However, it has recently been found that unsupervised image anomaly detection can be drastically improved through the utilization of huge corpora of random images to represent anomalousness; a technique which is known as Outlier Exposure. In this paper we show that specialized AD learning methods seem actually superfluous and huge corpora of data expendable. For a common AD benchmark on ImageNet, standard classifiers and semi-supervised one-class methods trained to discern between normal samples and just a few random natural images are able to outperform the current state of the art in deep AD, and only one useful outlier sample is sufficient to perform competitively. We investigate this phenomenon and reveal that one-class methods are more robust towards the particular choice of training outliers. Furthermore, we find that a simple classifier based on representations from CLIP, a recent foundation model, achieves state-of-the-art results on CIFAR-10 and also outperforms all previous AD methods on ImageNet without any training samples (i.e., in a zero-shot setting).
Explainable Deep One-Class Classification
Jul 03, 2020

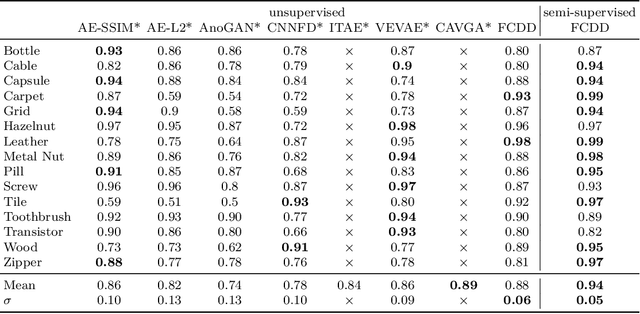
Deep one-class classification variants for anomaly detection learn a mapping that concentrates nominal samples in feature space causing anomalies to be mapped away. Because this transformation is highly non-linear, finding interpretations poses a significant challenge. In this paper we present an explainable deep one-class classification method, Fully Convolutional Data Description (FCDD), where the mapped samples are themselves also an explanation heatmap. FCDD yields competitive detection performance and provides reasonable explanations on common anomaly detection benchmarks with CIFAR-10 and ImageNet. On MVTec-AD, a recent manufacturing dataset offering ground-truth anomaly maps, FCDD meets the state of the art in an unsupervised setting, and outperforms its competitors in a semi-supervised setting. Finally, using FCDD's explanations we demonstrate the vulnerability of deep one-class classification models to spurious image features such as image watermarks.