 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining Anomalies: What If Anomalies Were Normal?
Feb 22, 2024Deep learning-based methods have achieved a breakthrough in image anomaly detection, but their complexity introduces a considerable challenge to understanding why an instance is predicted to be anomalous. We introduce a novel explanation method that generates multiple counterfactual examples for each anomaly, capturing diverse concepts of anomalousness. A counterfactual example is a modification of the anomaly that is perceived as normal by the anomaly detector. The method provides a high-level semantic explanation of the mechanism that triggered the anomaly detector, allowing users to explore "what-if scenarios." Qualitative and quantitative analyses across various image datasets show that the method applied to state-of-the-art anomaly detectors can achieve high-quality semantic explanations of detectors.
Wisdom of the Contexts: Active Ensemble Learning for Contextual Anomaly Detection
Jan 27, 2021
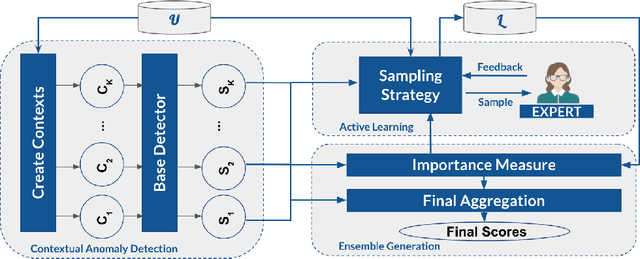
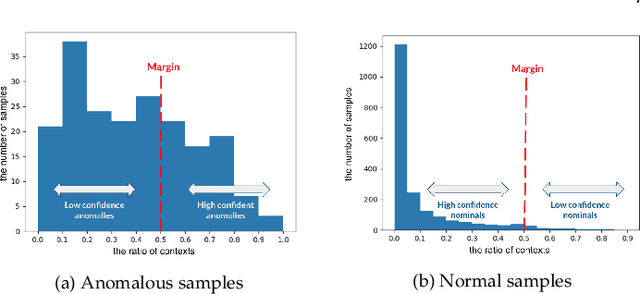
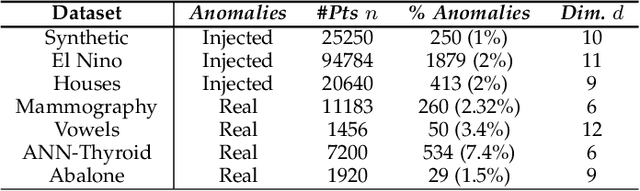
In contextual anomaly detection (CAD), an object is only considered anomalous within a specific context. Most existing methods for CAD use a single context based on a set of user-specified contextual features. However, identifying the right context can be very challenging in practice, especially in datasets, with a large number of attributes. Furthermore, in real-world systems, there might be multiple anomalies that occur in different contexts and, therefore, require a combination of several "useful" contexts to unveil them. In this work, we leverage active learning and ensembles to effectively detect complex contextual anomalies in situations where the true contextual and behavioral attributes are unknown. We propose a novel approach, called WisCon (Wisdom of the Contexts), that automatically creates contexts from the feature set. Our method constructs an ensemble of multiple contexts, with varying importance scores, based on the assumption that not all useful contexts are equally so. Experiments show that WisCon significantly outperforms existing baselines in different categories (i.e., active classifiers, unsupervised contextual and non-contextual anomaly detectors, and supervised classifiers) on seven datasets. Furthermore, the results support our initial hypothesis that there is no single perfect context that successfully uncovers all kinds of contextual anomalies, and leveraging the "wisdom" of multiple contexts is necessary.
No Free Lunch But A Cheaper Supper: A General Framework for Streaming Anomaly Detection
Sep 23, 2019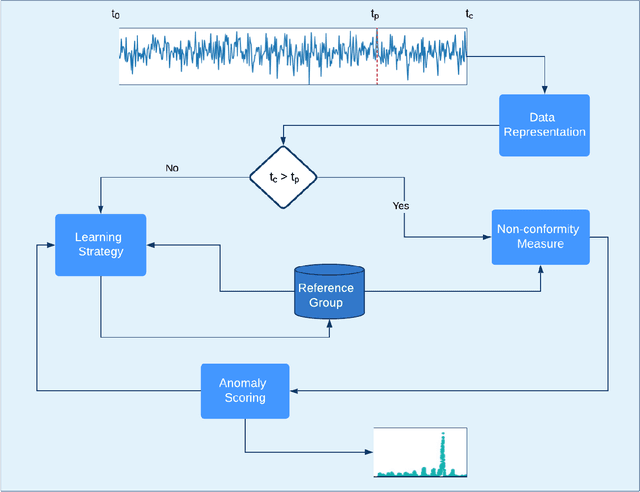
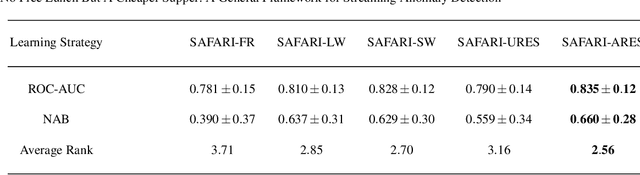
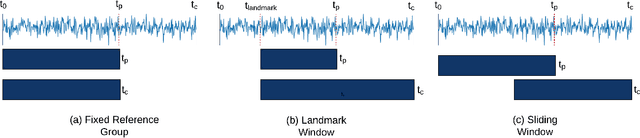
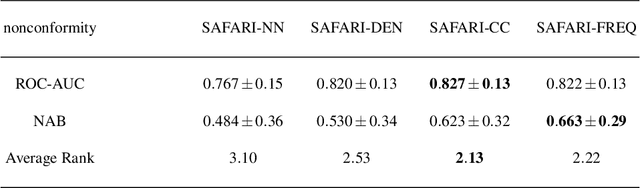
In recent years, there has been increased research interest in detecting anomalies in temporal streaming data. A variety of algorithms have been developed in the data mining community, which can be divided into two categories (i.e., general and ad hoc). In most cases, general approaches assume the one-size-fits-all solution model where a single anomaly detector can detect all anomalies in any domain. To date, there exists no single general method that has been shown to outperform the others across different anomaly types, use cases and datasets. On the other hand, ad hoc approaches that are designed for a specific application lack flexibility. Adapting an existing algorithm is not straightforward if the specific constraints or requirements for the existing task change. In this paper, we propose SAFARI, a general framework formulated by abstracting and unifying the fundamental tasks in streaming anomaly detection, which provides a flexible and extensible anomaly detection procedure. SAFARI helps to facilitate more elaborate algorithm comparisons by allowing us to isolate the effects of shared and unique characteristics of different algorithms on detection performance. Using SAFARI, we have implemented various anomaly detectors and identified a research gap that motivates us to propose a novel learning strategy in this work. We conducted an extensive evaluation study of 20 detectors that are composed using SAFARI and compared their performances using real-world benchmark datasets with different properties. The results indicate that there is no single superior detector that works well for every case, proving our hypothesis that "there is no free lunch" in the streaming anomaly detection world. Finally, we discuss the benefits and drawbacks of each method in-depth and draw a set of conclusions to guide future users of SAFARI.
A Data-Driven Approach for Discovery of Heat Load Patterns in District Heating
Jan 14, 2019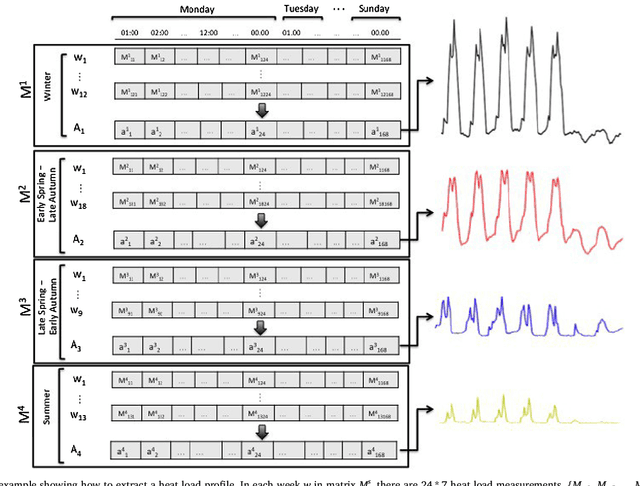
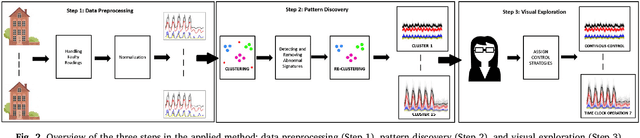
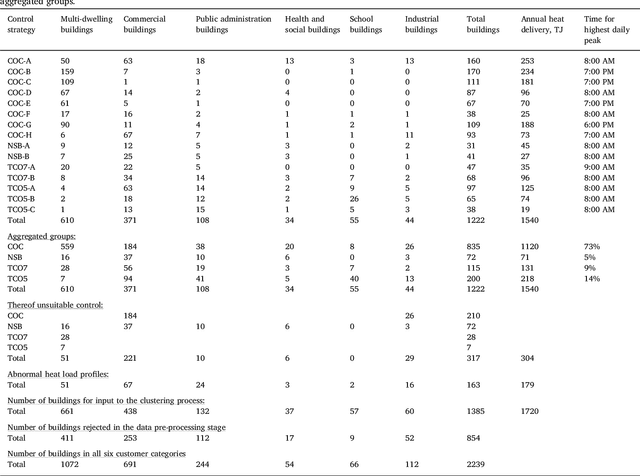
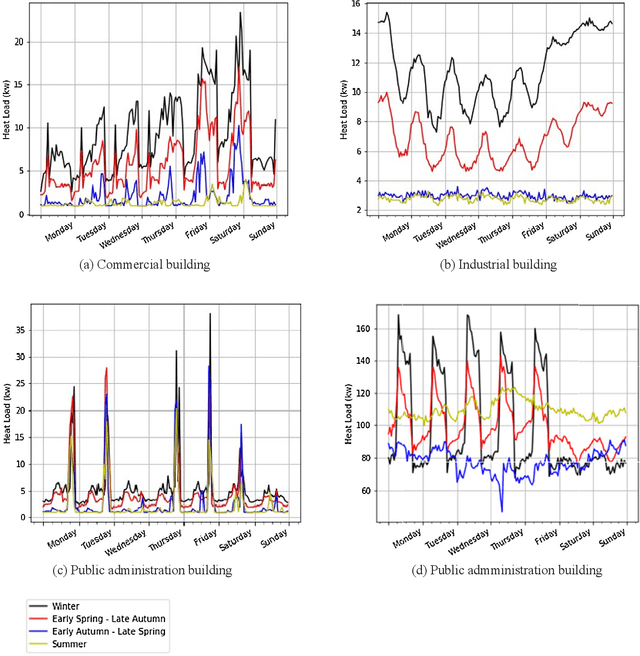
Understanding the heat use of customers is crucial for effective district heating (DH) operations and management. Unfortunately, existing knowledge about customers and their heat load behaviors is quite scarce and very few studies have been focusing on this aspect. The deployment of smart meters offers a unique opportunity for researchers and DH utilities to analyze large-scale data and discover both typical, as well as atypical, patterns in the network. Heat load pattern discovery is a challenging task in DH systems, since a comprehensive analysis needs to involve many customers. Most of the past studies have relied on analysis of a small number of buildings, which are not shown to be picked as the representative examples. Therefore, the knowledge discovered in such studies is not enough to generalize for the entire network. In this work, we propose a data-driven approach that enables automatic discovery of heat load patterns in a complete district heating network. Our method clusters the buildings into different groups based on the characteristics of their load profiles, extracts the representative patterns for each of them, and detects abnormal profiles, i.e., the ones deviating from the expected behavior. We present the first comprehensive analysis of the heat load patterns by conducting a case study on all the buildings, in six customer categories, connected to two district heating networks in the south of Sweden. Our method has captured fifteen typical patterns among the heat load profiles of all buildings in our dataset. It shows that control strategies are not enough to explain the variability in the heat load behaviors. In conclusion, we demonstrate that the proposed approach has a great potential to develop knowledge about customers and their heat use habits in practice by automatically analyzing their typical and atypical profiles in large-scale.