 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn without Forgetting using Attention
Aug 06, 2024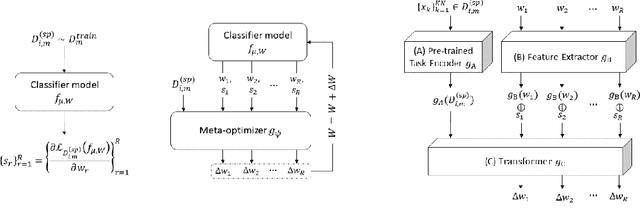

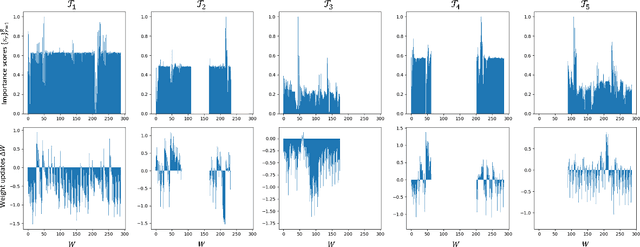
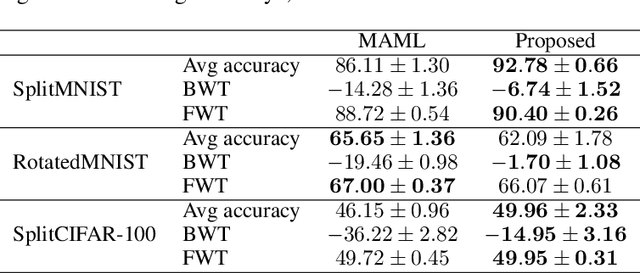
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Personalized Federated Learning with Contextual Modulation and Meta-Learning
Dec 23, 2023Federated learning has emerged as a promising approach for training machine learning models on decentralized data sources while preserving data privacy. However, challenges such as communication bottlenecks, heterogeneity of client devices, and non-i.i.d. data distribution pose significant obstacles to achieving optimal model performance. We propose a novel framework that combines federated learning with meta-learning techniques to enhance both efficiency and generalization capabilities. Our approach introduces a federated modulator that learns contextual information from data batches and uses this knowledge to generate modulation parameters. These parameters dynamically adjust the activations of a base model, which operates using a MAML-based approach for model personalization. Experimental results across diverse datasets highlight the improvements in convergence speed and model performance compared to existing federated learning approaches. These findings highlight the potential of incorporating contextual information and meta-learning techniques into federated learning, paving the way for advancements in distributed machine learning paradigms.
Advances and Challenges in Meta-Learning: A Technical Review
Jul 10, 2023Meta-learning empowers learning systems with the ability to acquire knowledge from multiple tasks, enabling faster adaptation and generalization to new tasks. This review provides a comprehensive technical overview of meta-learning, emphasizing its importance in real-world applications where data may be scarce or expensive to obtain. The paper covers the state-of-the-art meta-learning approaches and explores the relationship between meta-learning and multi-task learning, transfer learning, domain adaptation and generalization, self-supervised learning, personalized federated learning, and continual learning. By highlighting the synergies between these topics and the field of meta-learning, the paper demonstrates how advancements in one area can benefit the field as a whole, while avoiding unnecessary duplication of efforts. Additionally, the paper delves into advanced meta-learning topics such as learning from complex multi-modal task distributions, unsupervised meta-learning, learning to efficiently adapt to data distribution shifts, and continual meta-learning. Lastly, the paper highlights open problems and challenges for future research in the field. By synthesizing the latest research developments, this paper provides a thorough understanding of meta-learning and its potential impact on various machine learning applications. We believe that this technical overview will contribute to the advancement of meta-learning and its practical implications in addressing real-world problems.
Wisdom of the Contexts: Active Ensemble Learning for Contextual Anomaly Detection
Jan 27, 2021
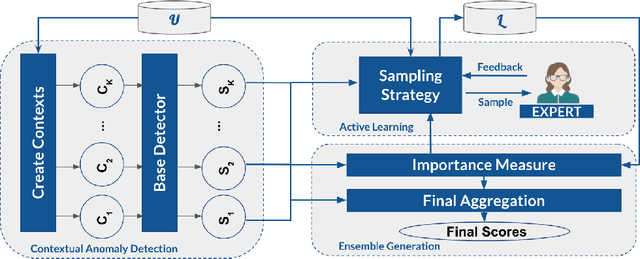
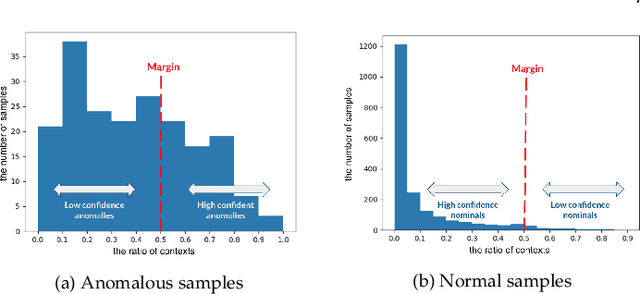
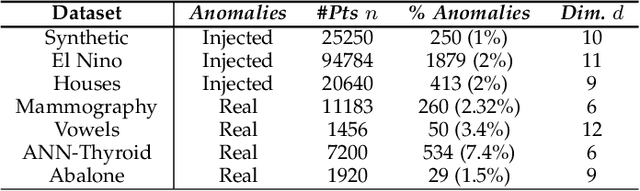
In contextual anomaly detection (CAD), an object is only considered anomalous within a specific context. Most existing methods for CAD use a single context based on a set of user-specified contextual features. However, identifying the right context can be very challenging in practice, especially in datasets, with a large number of attributes. Furthermore, in real-world systems, there might be multiple anomalies that occur in different contexts and, therefore, require a combination of several "useful" contexts to unveil them. In this work, we leverage active learning and ensembles to effectively detect complex contextual anomalies in situations where the true contextual and behavioral attributes are unknown. We propose a novel approach, called WisCon (Wisdom of the Contexts), that automatically creates contexts from the feature set. Our method constructs an ensemble of multiple contexts, with varying importance scores, based on the assumption that not all useful contexts are equally so. Experiments show that WisCon significantly outperforms existing baselines in different categories (i.e., active classifiers, unsupervised contextual and non-contextual anomaly detectors, and supervised classifiers) on seven datasets. Furthermore, the results support our initial hypothesis that there is no single perfect context that successfully uncovers all kinds of contextual anomalies, and leveraging the "wisdom" of multiple contexts is necessary.