 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom of the Contexts: Active Ensemble Learning for Contextual Anomaly Detection
Jan 27, 2021
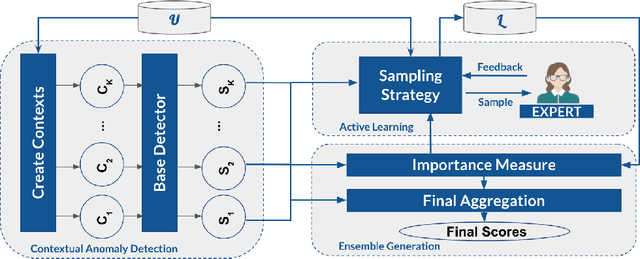
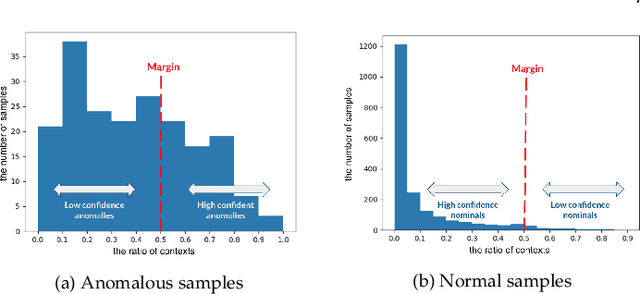
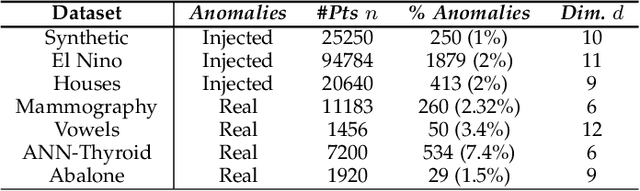
In contextual anomaly detection (CAD), an object is only considered anomalous within a specific context. Most existing methods for CAD use a single context based on a set of user-specified contextual features. However, identifying the right context can be very challenging in practice, especially in datasets, with a large number of attributes. Furthermore, in real-world systems, there might be multiple anomalies that occur in different contexts and, therefore, require a combination of several "useful" contexts to unveil them. In this work, we leverage active learning and ensembles to effectively detect complex contextual anomalies in situations where the true contextual and behavioral attributes are unknown. We propose a novel approach, called WisCon (Wisdom of the Contexts), that automatically creates contexts from the feature set. Our method constructs an ensemble of multiple contexts, with varying importance scores, based on the assumption that not all useful contexts are equally so. Experiments show that WisCon significantly outperforms existing baselines in different categories (i.e., active classifiers, unsupervised contextual and non-contextual anomaly detectors, and supervised classifiers) on seven datasets. Furthermore, the results support our initial hypothesis that there is no single perfect context that successfully uncovers all kinds of contextual anomalies, and leveraging the "wisdom" of multiple contexts is necessary.
No Free Lunch But A Cheaper Supper: A General Framework for Streaming Anomaly Detection
Sep 23, 2019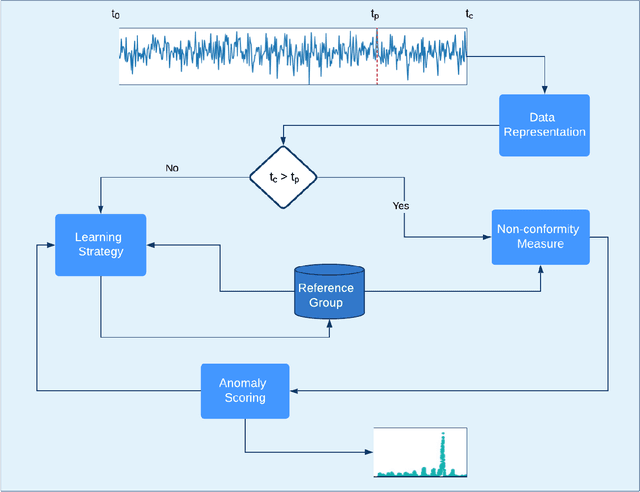
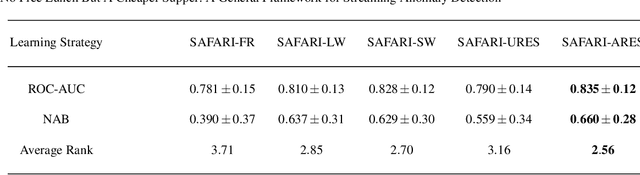
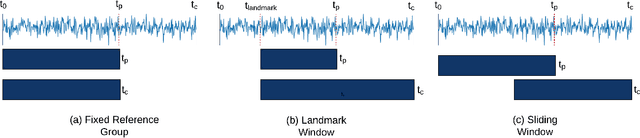
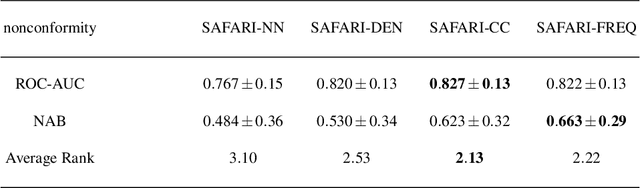
In recent years, there has been increased research interest in detecting anomalies in temporal streaming data. A variety of algorithms have been developed in the data mining community, which can be divided into two categories (i.e., general and ad hoc). In most cases, general approaches assume the one-size-fits-all solution model where a single anomaly detector can detect all anomalies in any domain. To date, there exists no single general method that has been shown to outperform the others across different anomaly types, use cases and datasets. On the other hand, ad hoc approaches that are designed for a specific application lack flexibility. Adapting an existing algorithm is not straightforward if the specific constraints or requirements for the existing task change. In this paper, we propose SAFARI, a general framework formulated by abstracting and unifying the fundamental tasks in streaming anomaly detection, which provides a flexible and extensible anomaly detection procedure. SAFARI helps to facilitate more elaborate algorithm comparisons by allowing us to isolate the effects of shared and unique characteristics of different algorithms on detection performance. Using SAFARI, we have implemented various anomaly detectors and identified a research gap that motivates us to propose a novel learning strategy in this work. We conducted an extensive evaluation study of 20 detectors that are composed using SAFARI and compared their performances using real-world benchmark datasets with different properties. The results indicate that there is no single superior detector that works well for every case, proving our hypothesis that "there is no free lunch" in the streaming anomaly detection world. Finally, we discuss the benefits and drawbacks of each method in-depth and draw a set of conclusions to guide future users of SAFARI.
Differentially Private Markov Chain Monte Carlo
Jan 29, 2019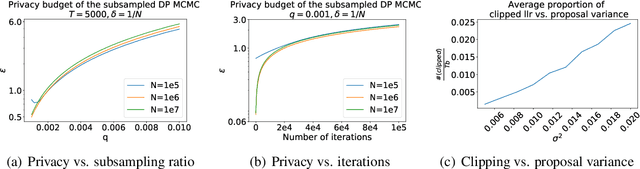

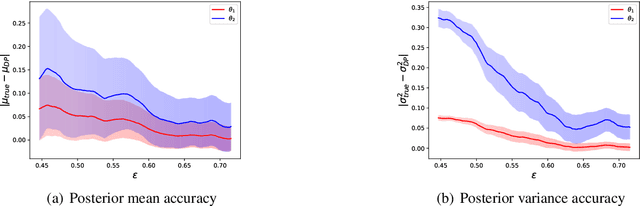
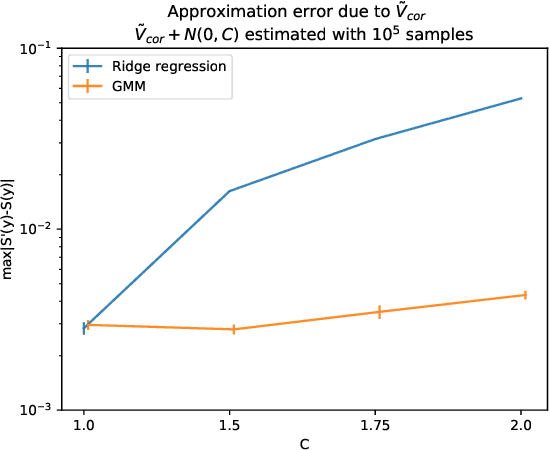
Recent developments in differentially private (DP) machine learning and DP Bayesian learning have enabled learning under strong privacy guarantees for the training data subjects. In this paper, we further extend the applicability of DP Bayesian learning by presenting the first general DP Markov chain Monte Carlo (MCMC) algorithm whose privacy-guarantees are not subject to unrealistic assumptions on Markov chain convergence and that is applicable to posterior inference in arbitrary models. Our algorithm is based on a decomposition of the Barker acceptance test that allows evaluating the R\'enyi DP privacy cost of the accept-reject choice. We further show how to improve the DP guarantee through data subsampling and approximate acceptance tests.
Efficient differentially private learning improves drug sensitivity prediction
Jul 05, 2017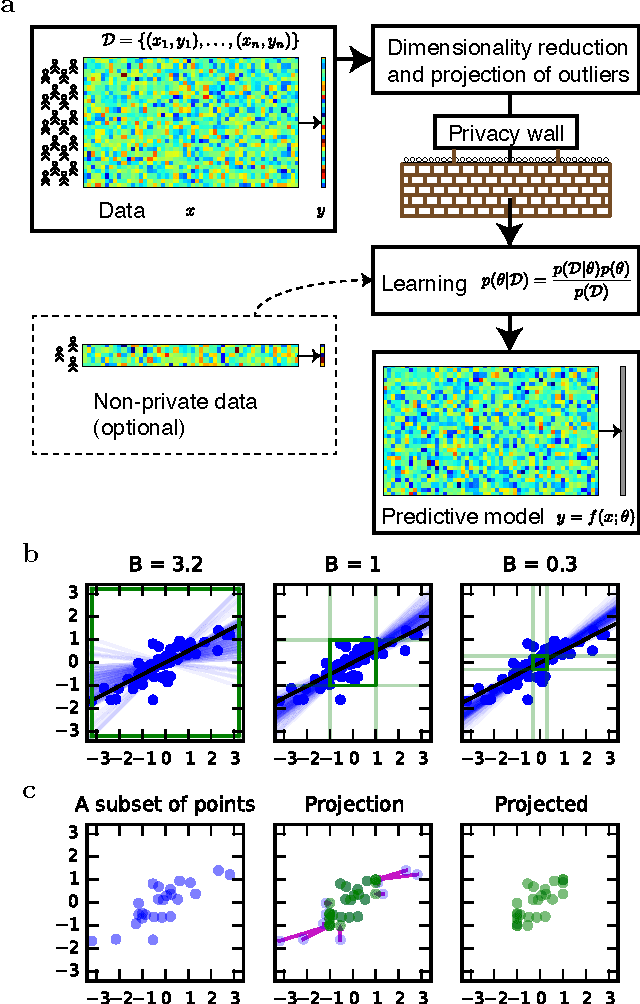
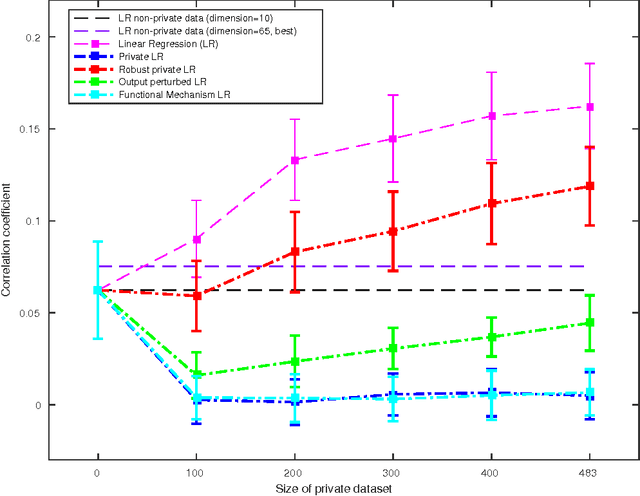
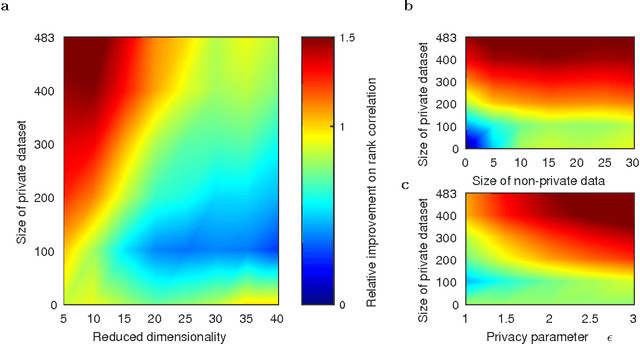
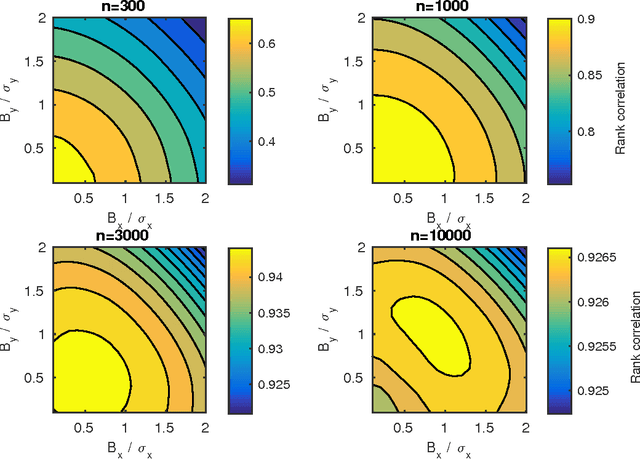
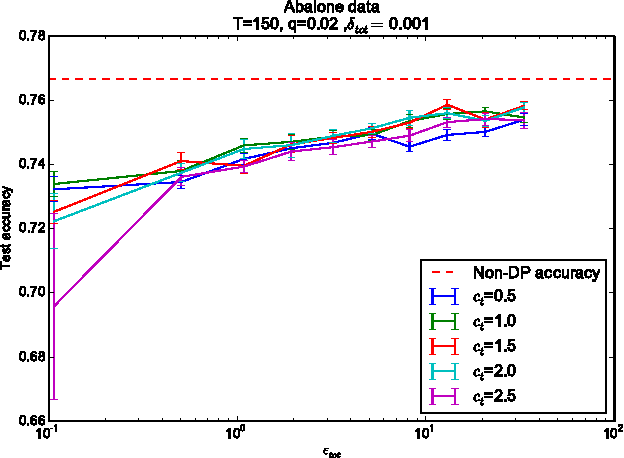
Users of a personalised recommendation system face a dilemma: recommendations can be improved by learning from data, but only if the other users are willing to share their private information. Good personalised predictions are vitally important in precision medicine, but genomic information on which the predictions are based is also particularly sensitive, as it directly identifies the patients and hence cannot easily be anonymised. Differential privacy has emerged as a potentially promising solution: privacy is considered sufficient if presence of individual patients cannot be distinguished. However, differentially private learning with current methods does not improve predictions with feasible data sizes and dimensionalities. Here we show that useful predictors can be learned under powerful differential privacy guarantees, and even from moderately-sized data sets, by demonstrating significant improvements with a new robust private regression method in the accuracy of private drug sensitivity prediction. The method combines two key properties not present even in recent proposals, which can be generalised to other predictors: we prove it is asymptotically consistently and efficiently private, and demonstrate that it performs well on finite data. Good finite data performance is achieved by limiting the sharing of private information by decreasing the dimensionality and by projecting outliers to fit tighter bounds, therefore needing to add less noise for equal privacy. As already the simple-to-implement method shows promise on the challenging genomic data, we anticipate rapid progress towards practical applications in many fields, such as mobile sensing and social media, in addition to the badly needed precision medicine solutions.
* 14 pages + 13 pages supplementary information, 3 + 3 figures
Differentially Private Variational Inference for Non-conjugate Models
Apr 10, 2017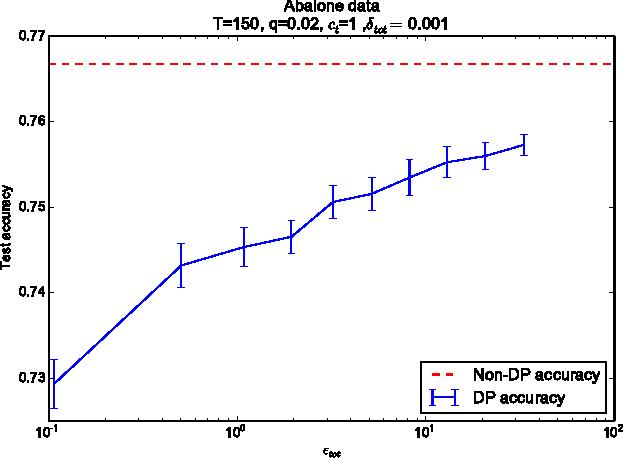
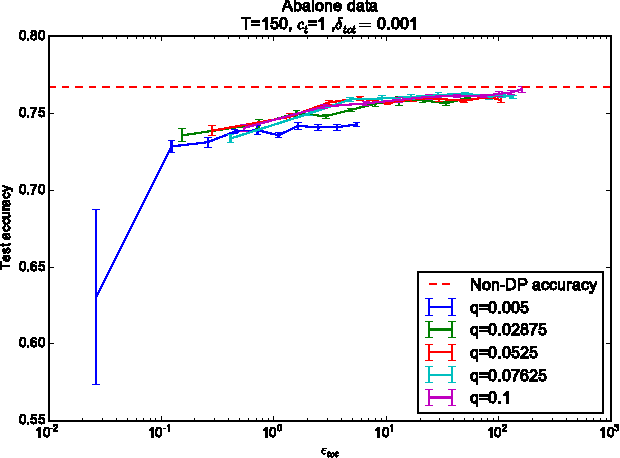
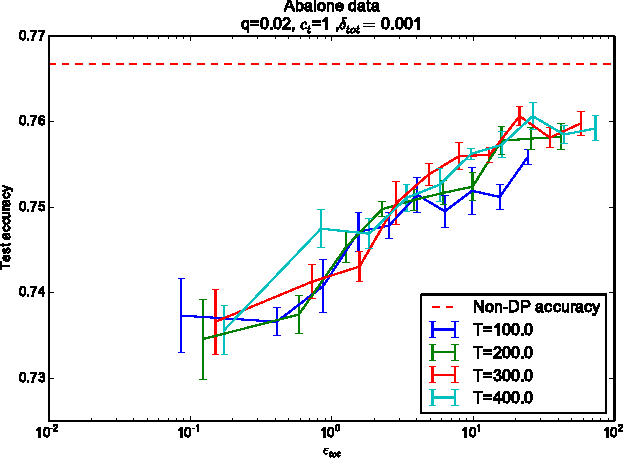
Many machine learning applications are based on data collected from people, such as their tastes and behaviour as well as biological traits and genetic data. Regardless of how important the application might be, one has to make sure individuals' identities or the privacy of the data are not compromised in the analysis. Differential privacy constitutes a powerful framework that prevents breaching of data subject privacy from the output of a computation. Differentially private versions of many important Bayesian inference methods have been proposed, but there is a lack of an efficient unified approach applicable to arbitrary models. In this contribution, we propose a differentially private variational inference method with a very wide applicability. It is built on top of doubly stochastic variational inference, a recent advance which provides a variational solution to a large class of models. We add differential privacy into doubly stochastic variational inference by clipping and perturbing the gradients. The algorithm is made more efficient through privacy amplification from subsampling. We demonstrate the method can reach an accuracy close to non-private level under reasonably strong privacy guarantees, clearly improving over previous sampling-based alternatives especially in the strong privacy regime.
Learning Mixtures of Ising Models using Pseudolikelihood
Jun 08, 2015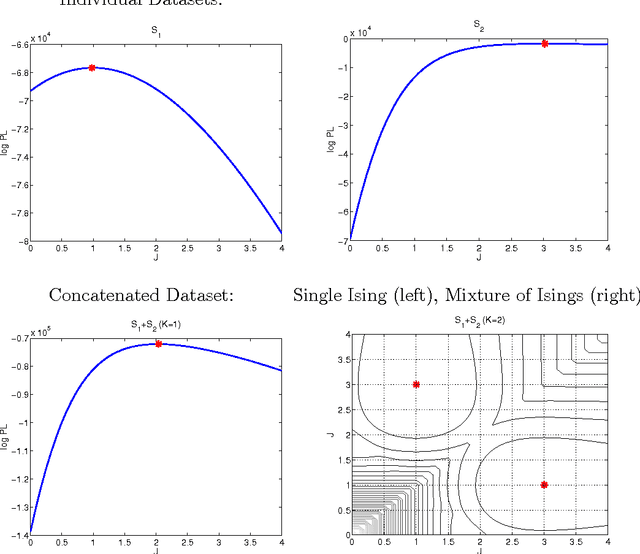
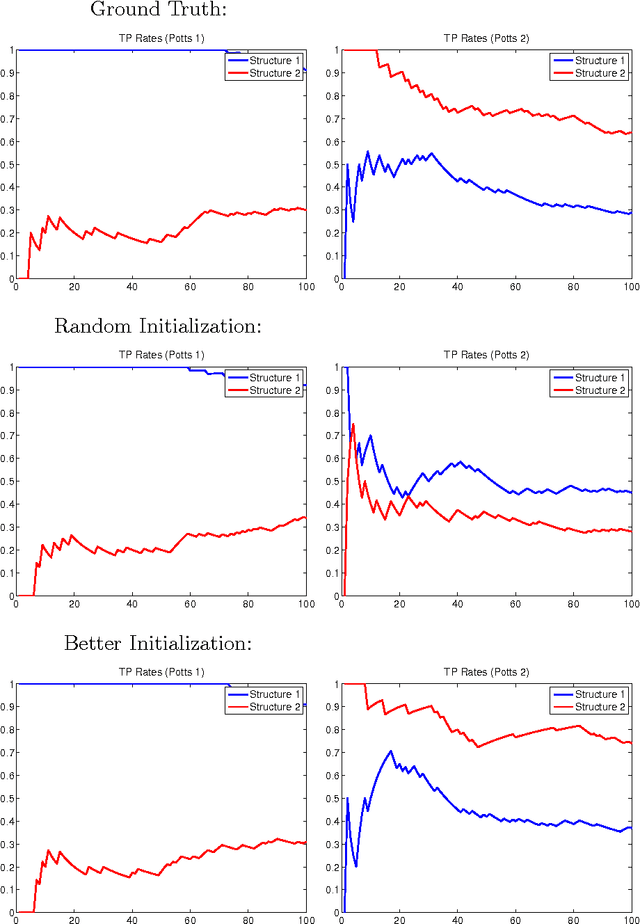
Maximum pseudolikelihood method has been among the most important methods for learning parameters of statistical physics models, such as Ising models. In this paper, we study how pseudolikelihood can be derived for learning parameters of a mixture of Ising models. The performance of the proposed approach is demonstrated for Ising and Potts models on both synthetic and real data.
Learning the Information Divergence
Jun 05, 2014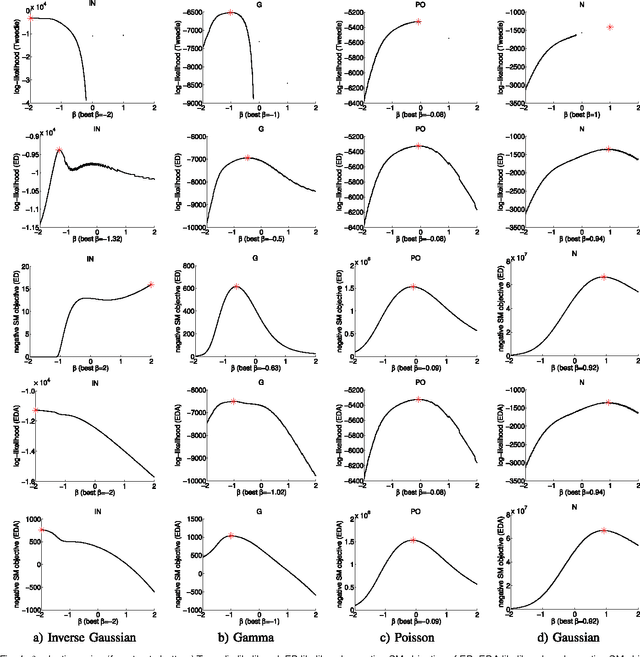
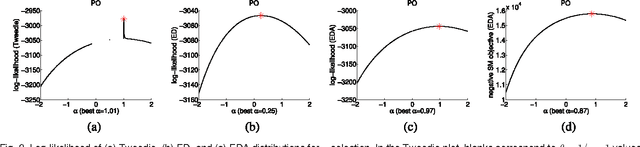
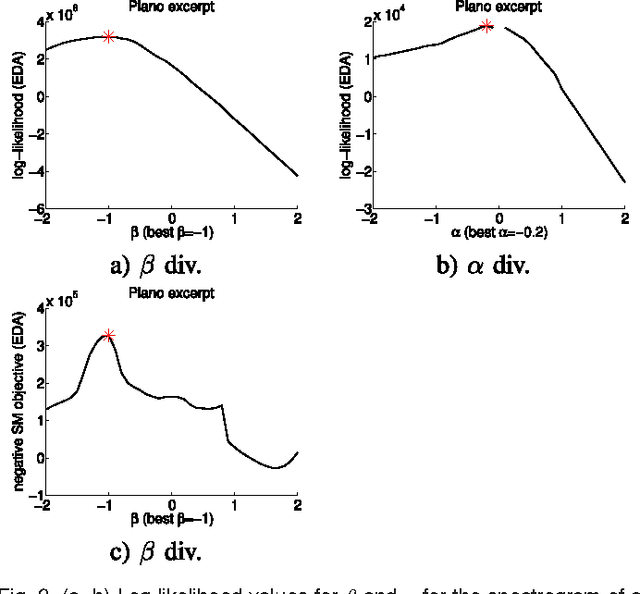
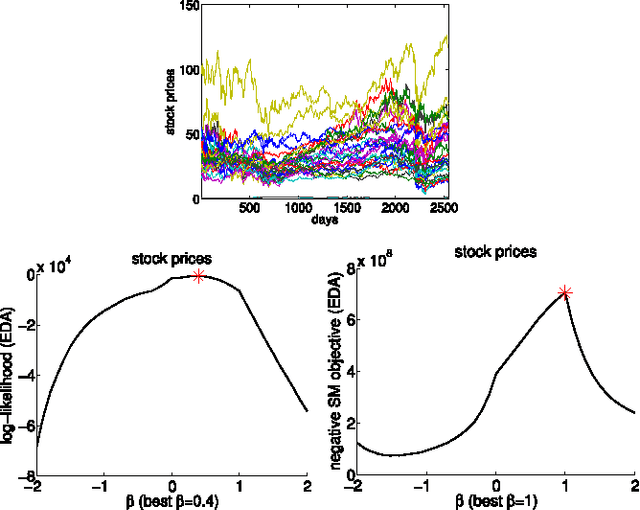
Information divergence that measures the difference between two nonnegative matrices or tensors has found its use in a variety of machine learning problems. Examples are Nonnegative Matrix/Tensor Factorization, Stochastic Neighbor Embedding, topic models, and Bayesian network optimization. The success of such a learning task depends heavily on a suitable divergence. A large variety of divergences have been suggested and analyzed, but very few results are available for an objective choice of the optimal divergence for a given task. Here we present a framework that facilitates automatic selection of the best divergence among a given family, based on standard maximum likelihood estimation. We first propose an approximated Tweedie distribution for the beta-divergence family. Selecting the best beta then becomes a machine learning problem solved by maximum likelihood. Next, we reformulate alpha-divergence in terms of beta-divergence, which enables automatic selection of alpha by maximum likelihood with reuse of the learning principle for beta-divergence. Furthermore, we show the connections between gamma and beta-divergences as well as R\'enyi and alpha-divergences, such that our automatic selection framework is extended to non-separable divergences. Experiments on both synthetic and real-world data demonstrate that our method can quite accurately select information divergence across different learning problems and various divergence families.