 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Hyperparameters for Differentially Private Deep Transfer Learning
Oct 23, 2025Differentially private (DP) transfer learning, i.e., fine-tuning a pretrained model on private data, is the current state-of-the-art approach for training large models under privacy constraints. We focus on two key hyperparameters in this setting: the clipping bound $C$ and batch size $B$. We show a clear mismatch between the current theoretical understanding of how to choose an optimal $C$ (stronger privacy requires smaller $C$) and empirical outcomes (larger $C$ performs better under strong privacy), caused by changes in the gradient distributions. Assuming a limited compute budget (fixed epochs), we demonstrate that the existing heuristics for tuning $B$ do not work, while cumulative DP noise better explains whether smaller or larger batches perform better. We also highlight how the common practice of using a single $(C,B)$ setting across tasks can lead to suboptimal performance. We find that performance drops especially when moving between loose and tight privacy and between plentiful and limited compute, which we explain by analyzing clipping as a form of gradient re-weighting and examining cumulative DP noise.
On Joint Noise Scaling in Differentially Private Federated Learning with Multiple Local Steps
Jul 27, 2024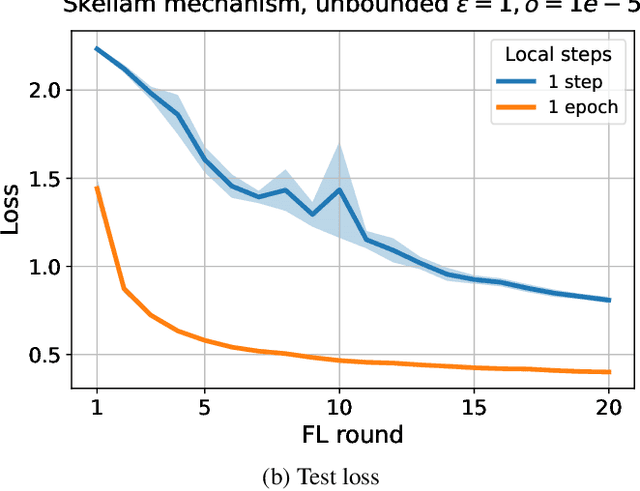
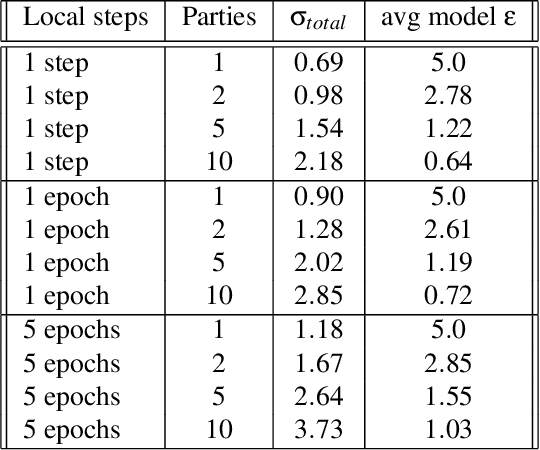


Federated learning is a distributed learning setting where the main aim is to train machine learning models without having to share raw data but only what is required for learning. To guarantee training data privacy and high-utility models, differential privacy and secure aggregation techniques are often combined with federated learning. However, with fine-grained protection granularities the currently existing techniques require the parties to communicate for each local optimisation step, if they want to fully benefit from the secure aggregation in terms of the resulting formal privacy guarantees. In this paper, we show how a simple new analysis allows the parties to perform multiple local optimisation steps while still benefiting from joint noise scaling when using secure aggregation. We show that our analysis enables higher utility models with guaranteed privacy protection under limited number of communication rounds.
Differentially private partitioned variational inference
Sep 23, 2022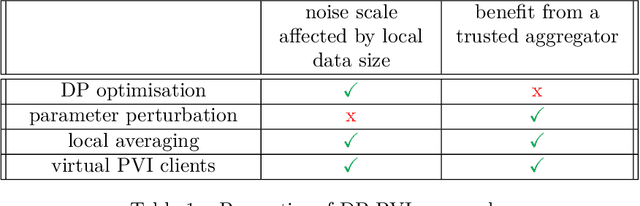
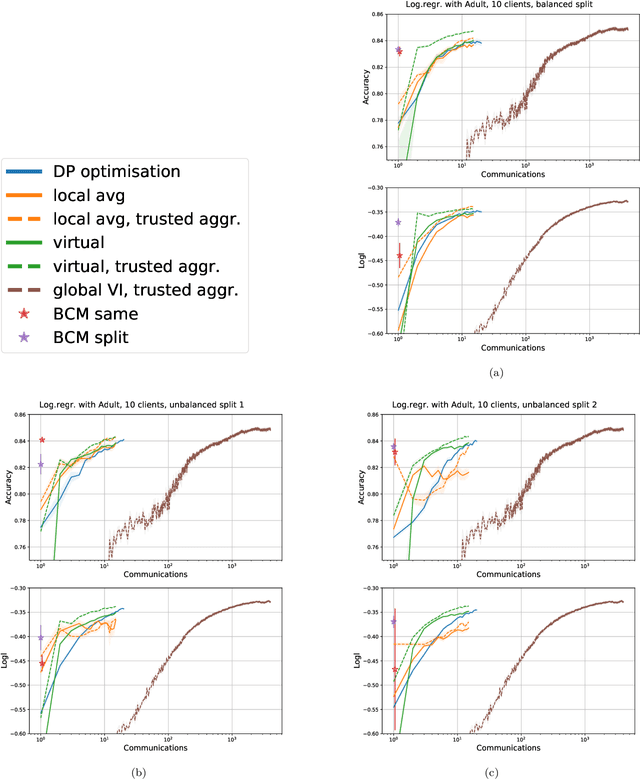
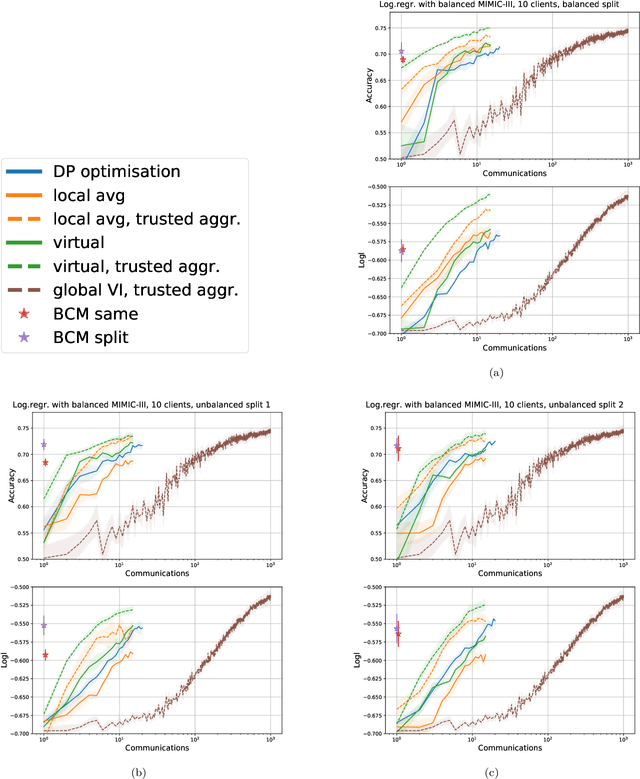

Learning a privacy-preserving model from distributed sensitive data is an increasingly important problem, often formulated in the federated learning context. Variational inference has recently been extended to the non-private federated learning setting via the partitioned variational inference algorithm. For privacy protection, the current gold standard is called differential privacy. Differential privacy guarantees privacy in a strong, mathematically clearly defined sense. In this paper, we present differentially private partitioned variational inference, the first general framework for learning a variational approximation to a Bayesian posterior distribution in the federated learning setting while minimising the number of communication rounds and providing differential privacy guarantees for data subjects. We propose three alternative implementations in the general framework, one based on perturbing local optimisation done by individual parties, and two based on perturbing global updates (one using a version of federated averaging, one adding virtual parties to the protocol), and compare their properties both theoretically and empirically. We show that perturbing the local optimisation works well with simple and complex models as long as each party has enough local data. However, the privacy is always guaranteed independently by each party. In contrast, perturbing the global updates works best with relatively simple models. Given access to suitable secure primitives, such as secure aggregation or secure shuffling, the performance can be improved by all parties guaranteeing privacy jointly.
Tight Accounting in the Shuffle Model of Differential Privacy
Jun 01, 2021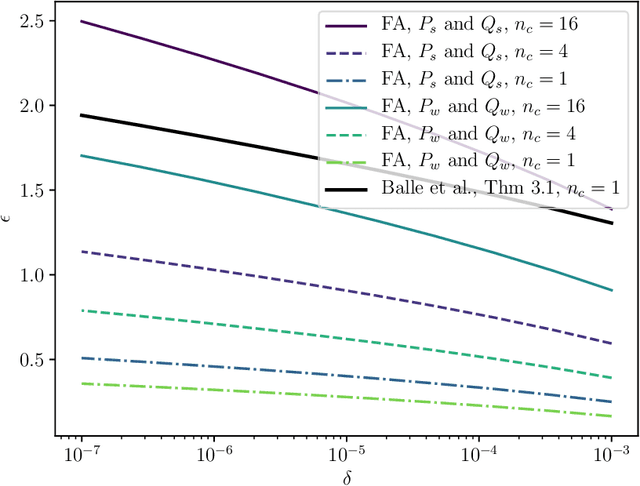
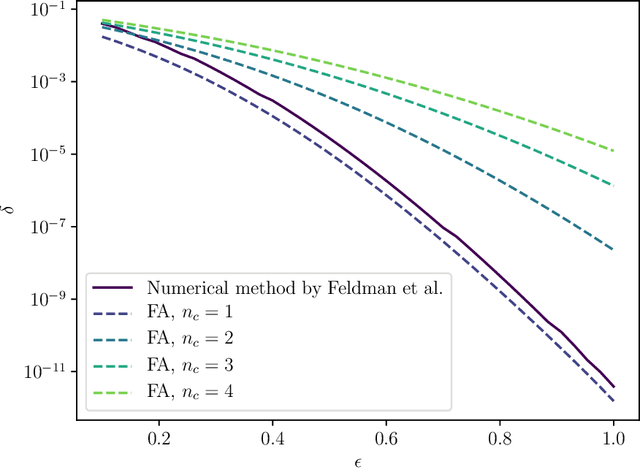
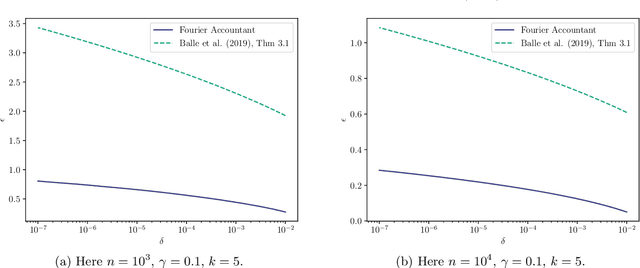
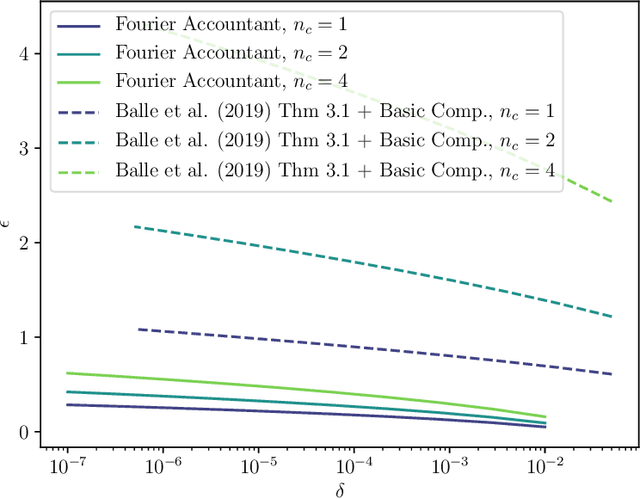
Shuffle model of differential privacy is a novel distributed privacy model based on a combination of local privacy mechanisms and a trusted shuffler. It has been shown that the additional randomisation provided by the shuffler improves privacy bounds compared to the purely local mechanisms. Accounting tight bounds, especially for multi-message protocols, is complicated by the complexity brought by the shuffler. The recently proposed Fourier Accountant for evaluating $(\varepsilon,\delta)$-differential privacy guarantees has been shown to give tighter bounds than commonly used methods for non-adaptive compositions of various complex mechanisms. In this paper we show how to compute tight privacy bounds using the Fourier Accountant for multi-message versions of several ubiquitous mechanisms in the shuffle model and demonstrate looseness of the existing bounds in the literature.
Differentially private cross-silo federated learning
Jul 10, 2020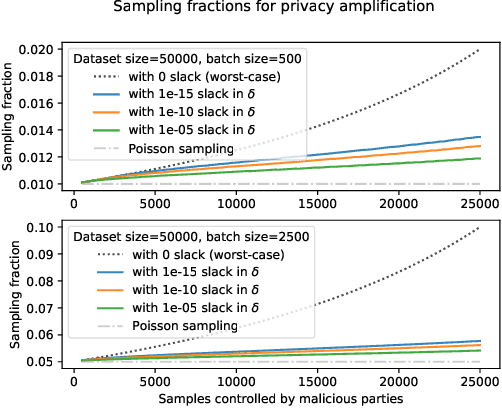
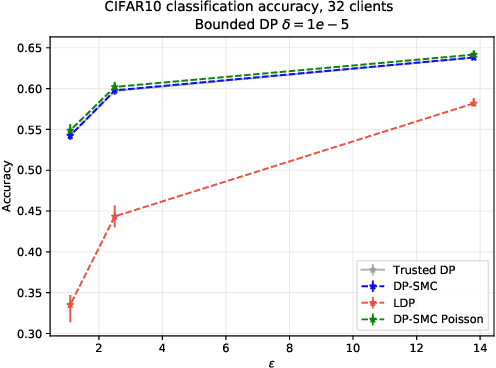
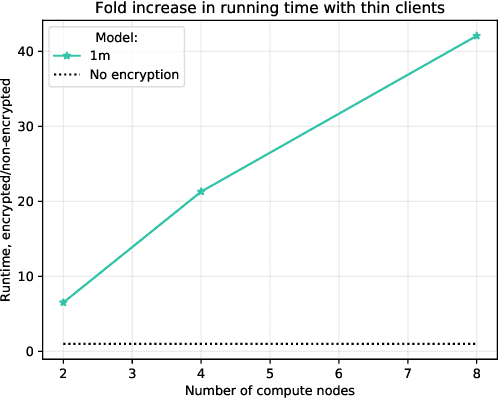
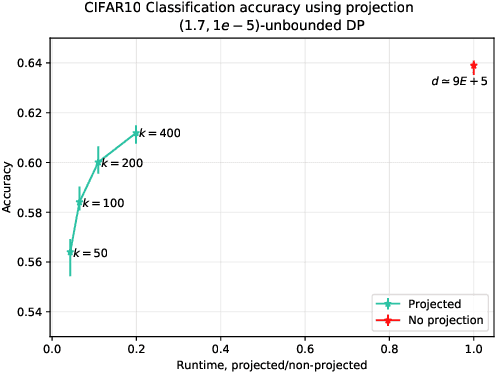
Strict privacy is of paramount importance in distributed machine learning. Federated learning, with the main idea of communicating only what is needed for learning, has been recently introduced as a general approach for distributed learning to enhance learning and improve security. However, federated learning by itself does not guarantee any privacy for data subjects. To quantify and control how much privacy is compromised in the worst-case, we can use differential privacy. In this paper we combine additively homomorphic secure summation protocols with differential privacy in the so-called cross-silo federated learning setting. The goal is to learn complex models like neural networks while guaranteeing strict privacy for the individual data subjects. We demonstrate that our proposed solutions give prediction accuracy that is comparable to the non-distributed setting, and are fast enough to enable learning models with millions of parameters in a reasonable time. To enable learning under strict privacy guarantees that need privacy amplification by subsampling, we present a general algorithm for oblivious distributed subsampling. However, we also argue that when malicious parties are present, a simple approach using distributed Poisson subsampling gives better privacy. Finally, we show that by leveraging random projections we can further scale-up our approach to larger models while suffering only a modest performance loss.
Differentially Private Markov Chain Monte Carlo
Jan 29, 2019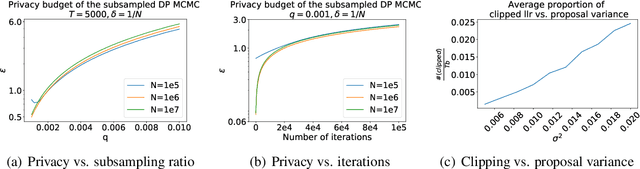

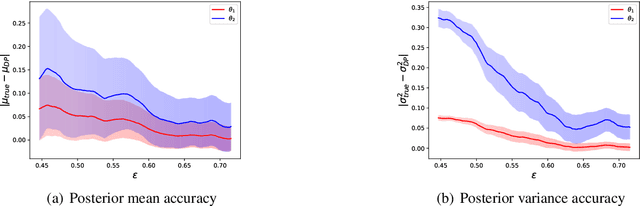
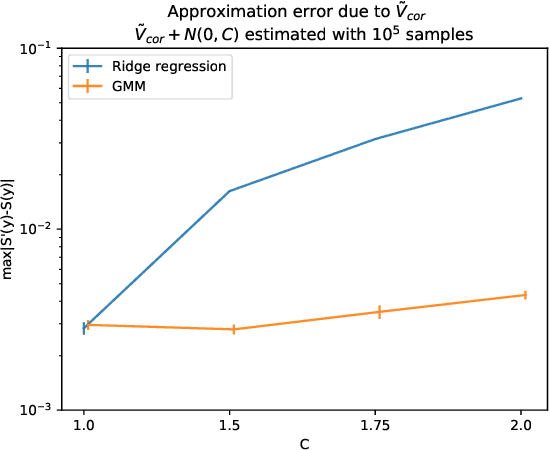
Recent developments in differentially private (DP) machine learning and DP Bayesian learning have enabled learning under strong privacy guarantees for the training data subjects. In this paper, we further extend the applicability of DP Bayesian learning by presenting the first general DP Markov chain Monte Carlo (MCMC) algorithm whose privacy-guarantees are not subject to unrealistic assumptions on Markov chain convergence and that is applicable to posterior inference in arbitrary models. Our algorithm is based on a decomposition of the Barker acceptance test that allows evaluating the R\'enyi DP privacy cost of the accept-reject choice. We further show how to improve the DP guarantee through data subsampling and approximate acceptance tests.