 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated ADMM from Bayesian Duality
Jun 16, 2025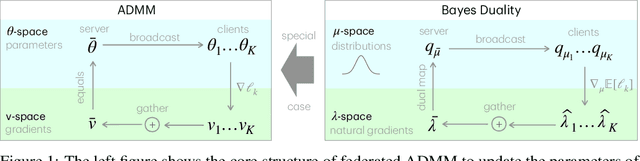
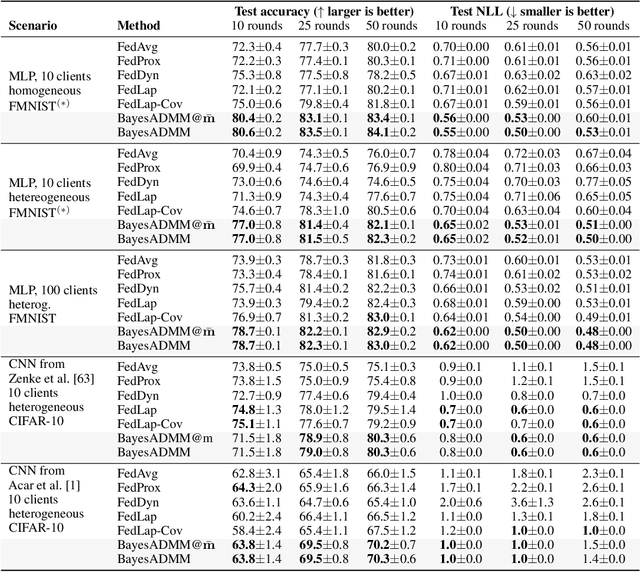

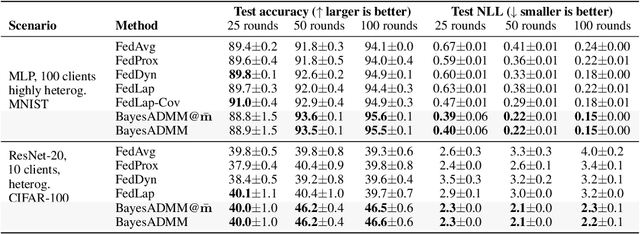
ADMM is a popular method for federated deep learning which originated in the 1970s and, even though many new variants of it have been proposed since then, its core algorithmic structure has remained unchanged. Here, we take a major departure from the old structure and present a fundamentally new way to derive and extend federated ADMM. We propose to use a structure called Bayesian Duality which exploits a duality of the posterior distributions obtained by solving a variational-Bayesian reformulation of the original problem. We show that this naturally recovers the original ADMM when isotropic Gaussian posteriors are used, and yields non-trivial extensions for other posterior forms. For instance, full-covariance Gaussians lead to Newton-like variants of ADMM, while diagonal covariances result in a cheap Adam-like variant. This is especially useful to handle heterogeneity in federated deep learning, giving up to 7% accuracy improvements over recent baselines. Our work opens a new Bayesian path to improve primal-dual methods.
Connecting Federated ADMM to Bayes
Jan 28, 2025We provide new connections between two distinct federated learning approaches based on (i) ADMM and (ii) Variational Bayes (VB), and propose new variants by combining their complementary strengths. Specifically, we show that the dual variables in ADMM naturally emerge through the 'site' parameters used in VB with isotropic Gaussian covariances. Using this, we derive two versions of ADMM from VB that use flexible covariances and functional regularisation, respectively. Through numerical experiments, we validate the improvements obtained in performance. The work shows connection between two fields that are believed to be fundamentally different and combines them to improve federated learning.
Contrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills
Oct 05, 2024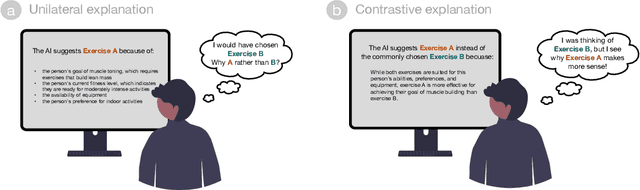
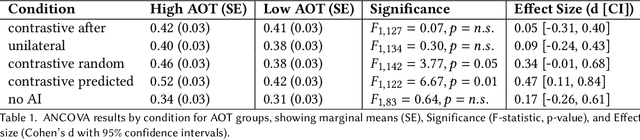


People's decision-making abilities often fail to improve or may even erode when they rely on AI for decision-support, even when the AI provides informative explanations. We argue this is partly because people intuitively seek contrastive explanations, which clarify the difference between the AI's decision and their own reasoning, while most AI systems offer "unilateral" explanations that justify the AI's decision but do not account for users' thinking. To align human-AI knowledge on decision tasks, we introduce a framework for generating human-centered contrastive explanations that explain the difference between AI's choice and a predicted, likely human choice about the same task. Results from a large-scale experiment (N = 628) demonstrate that contrastive explanations significantly enhance users' independent decision-making skills compared to unilateral explanations, without sacrificing decision accuracy. Amid rising deskilling concerns, our research demonstrates that incorporating human reasoning into AI design can foster human skill development.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024



As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.
Reinforcement Learning Interventions on Boundedly Rational Human Agents in Frictionful Tasks
Jan 26, 2024Many important behavior changes are frictionful; they require individuals to expend effort over a long period with little immediate gratification. Here, an artificial intelligence (AI) agent can provide personalized interventions to help individuals stick to their goals. In these settings, the AI agent must personalize rapidly (before the individual disengages) and interpretably, to help us understand the behavioral interventions. In this paper, we introduce Behavior Model Reinforcement Learning (BMRL), a framework in which an AI agent intervenes on the parameters of a Markov Decision Process (MDP) belonging to a boundedly rational human agent. Our formulation of the human decision-maker as a planning agent allows us to attribute undesirable human policies (ones that do not lead to the goal) to their maladapted MDP parameters, such as an extremely low discount factor. Furthermore, we propose a class of tractable human models that captures fundamental behaviors in frictionful tasks. Introducing a notion of MDP equivalence specific to BMRL, we theoretically and empirically show that AI planning with our human models can lead to helpful policies on a wide range of more complex, ground-truth humans.
Adaptive interventions for both accuracy and time in AI-assisted human decision making
Jun 12, 2023



In settings where users are both time-pressured and need high accuracy, such as doctors working in Emergency Rooms, we want to provide AI assistance that both increases accuracy and reduces time. However, different types of AI assistance have different benefits: some reduce time taken while increasing overreliance on AI, while others do the opposite. We therefore want to adapt what AI assistance we show depending on various properties (of the question and of the user) in order to best tradeoff our two objectives. We introduce a study where users have to prescribe medicines to aliens, and use it to explore the potential for adapting AI assistance. We find evidence that it is beneficial to adapt our AI assistance depending on the question, leading to good tradeoffs between time taken and accuracy. Future work would consider machine-learning algorithms (such as reinforcement learning) to automatically adapt quickly.
Modeling Mobile Health Users as Reinforcement Learning Agents
Dec 01, 2022



Mobile health (mHealth) technologies empower patients to adopt/maintain healthy behaviors in their daily lives, by providing interventions (e.g. push notifications) tailored to the user's needs. In these settings, without intervention, human decision making may be impaired (e.g. valuing near term pleasure over own long term goals). In this work, we formalize this relationship with a framework in which the user optimizes a (potentially impaired) Markov Decision Process (MDP) and the mHealth agent intervenes on the user's MDP parameters. We show that different types of impairments imply different types of optimal intervention. We also provide analytical and empirical explorations of these differences.
Differentially private partitioned variational inference
Sep 23, 2022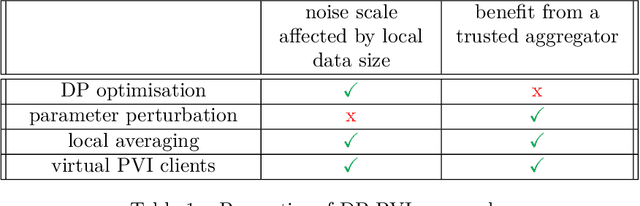
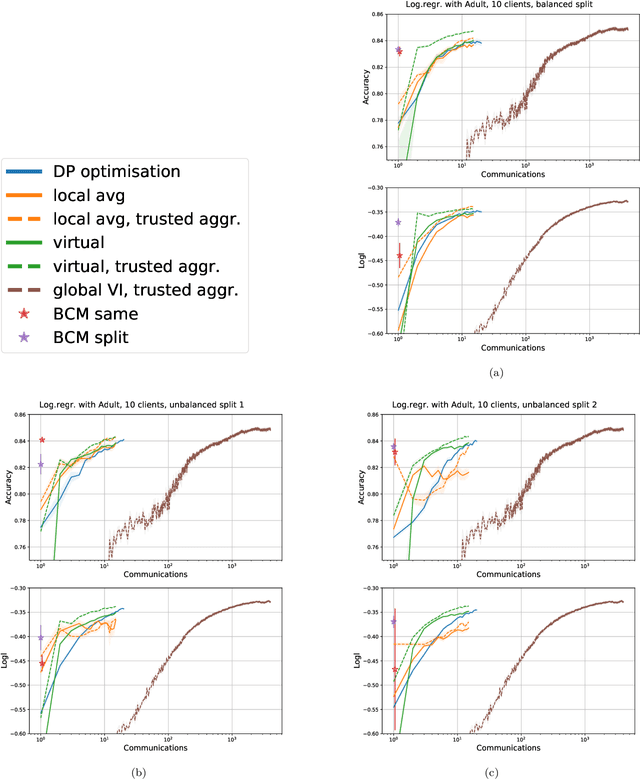
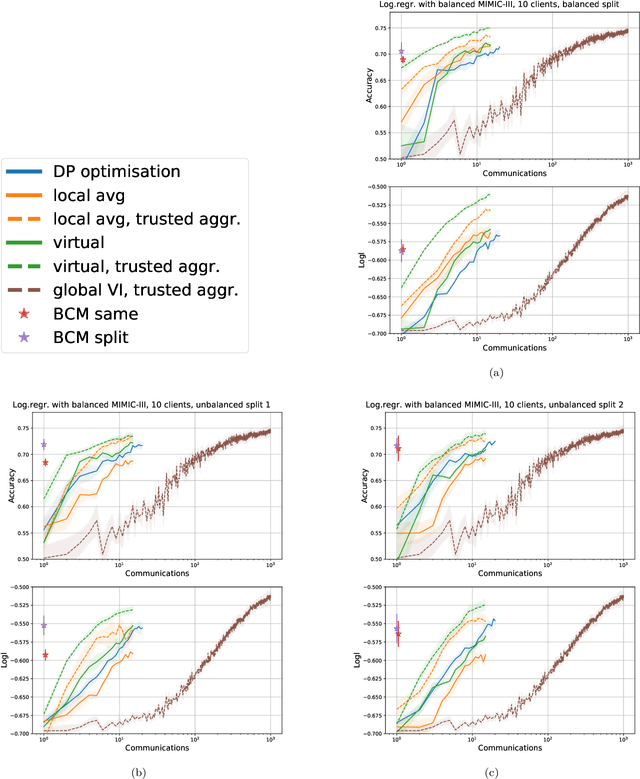

Learning a privacy-preserving model from distributed sensitive data is an increasingly important problem, often formulated in the federated learning context. Variational inference has recently been extended to the non-private federated learning setting via the partitioned variational inference algorithm. For privacy protection, the current gold standard is called differential privacy. Differential privacy guarantees privacy in a strong, mathematically clearly defined sense. In this paper, we present differentially private partitioned variational inference, the first general framework for learning a variational approximation to a Bayesian posterior distribution in the federated learning setting while minimising the number of communication rounds and providing differential privacy guarantees for data subjects. We propose three alternative implementations in the general framework, one based on perturbing local optimisation done by individual parties, and two based on perturbing global updates (one using a version of federated averaging, one adding virtual parties to the protocol), and compare their properties both theoretically and empirically. We show that perturbing the local optimisation works well with simple and complex models as long as each party has enough local data. However, the privacy is always guaranteed independently by each party. In contrast, perturbing the global updates works best with relatively simple models. Given access to suitable secure primitives, such as secure aggregation or secure shuffling, the performance can be improved by all parties guaranteeing privacy jointly.
Partitioned Variational Inference: A Framework for Probabilistic Federated Learning
Feb 28, 2022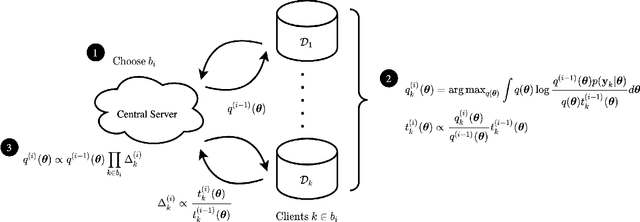
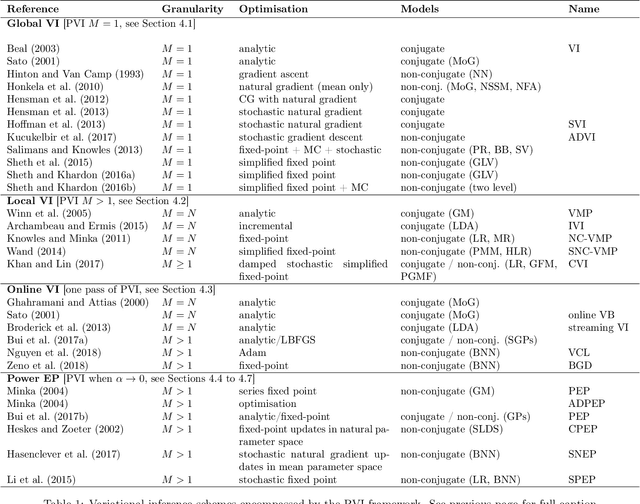
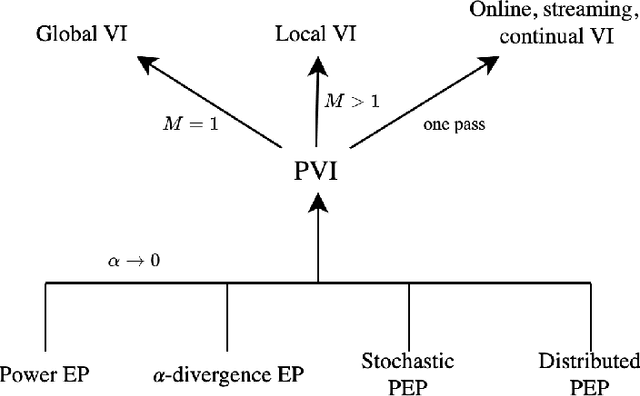
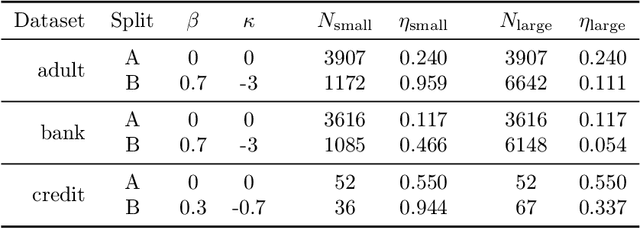
The proliferation of computing devices has brought about an opportunity to deploy machine learning models on new problem domains using previously inaccessible data. Traditional algorithms for training such models often require data to be stored on a single machine with compute performed by a single node, making them unsuitable for decentralised training on multiple devices. This deficiency has motivated the development of federated learning algorithms, which allow multiple data owners to train collaboratively and use a shared model whilst keeping local data private. However, many of these algorithms focus on obtaining point estimates of model parameters, rather than probabilistic estimates capable of capturing model uncertainty, which is essential in many applications. Variational inference (VI) has become the method of choice for fitting many modern probabilistic models. In this paper we introduce partitioned variational inference (PVI), a general framework for performing VI in the federated setting. We develop new supporting theory for PVI, demonstrating a number of properties that make it an attractive choice for practitioners; use PVI to unify a wealth of fragmented, yet related literature; and provide empirical results that showcase the effectiveness of PVI in a variety of federated settings.
Knowledge-Adaptation Priors
Jun 16, 2021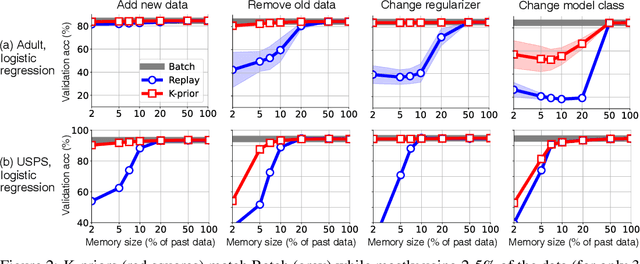
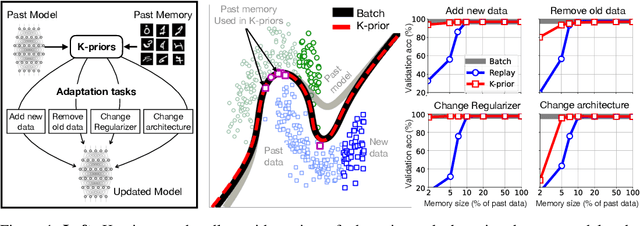
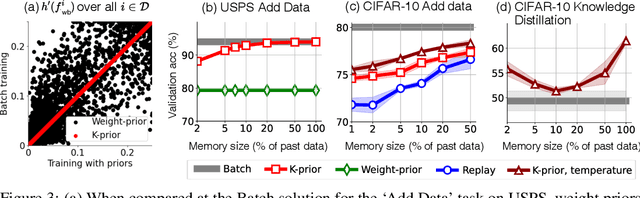
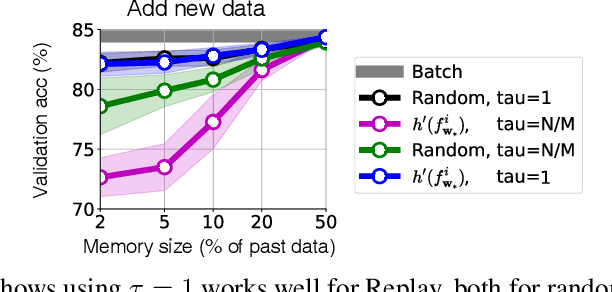
Humans and animals have a natural ability to quickly adapt to their surroundings, but machine-learning models, when subjected to changes, often require a complete retraining from scratch. We present Knowledge-adaptation priors (K-priors) to reduce the cost of retraining by enabling quick and accurate adaptation for a wide-variety of tasks and models. This is made possible by a combination of weight and function-space priors to reconstruct the gradients of the past, which recovers and generalizes many existing, but seemingly-unrelated, adaptation strategies. Training with simple first-order gradient methods can often recover the exact retrained model to an arbitrary accuracy by choosing a sufficiently large memory of the past data. Empirical results confirm that the adaptation can be cheap and accurate, and a promising alternative to retraining.