 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiWaves Reinforcement Learning Algorithm
Aug 27, 2024



The escalating prevalence of cannabis use poses a significant public health challenge globally. In the U.S., cannabis use is more prevalent among emerging adults (EAs) (ages 18-25) than any other age group, with legalization in the multiple states contributing to a public perception that cannabis is less risky than in prior decades. To address this growing concern, we developed MiWaves, a reinforcement learning (RL) algorithm designed to optimize the delivery of personalized intervention prompts to reduce cannabis use among EAs. MiWaves leverages domain expertise and prior data to tailor the likelihood of delivery of intervention messages. This paper presents a comprehensive overview of the algorithm's design, including key decisions and experimental outcomes. The finalized MiWaves RL algorithm was deployed in a clinical trial from March to May 2024.
reBandit: Random Effects based Online RL algorithm for Reducing Cannabis Use
Feb 27, 2024



The escalating prevalence of cannabis use, and associated cannabis-use disorder (CUD), poses a significant public health challenge globally. With a notably wide treatment gap, especially among emerging adults (EAs; ages 18-25), addressing cannabis use and CUD remains a pivotal objective within the 2030 United Nations Agenda for Sustainable Development Goals (SDG). In this work, we develop an online reinforcement learning (RL) algorithm called reBandit which will be utilized in a mobile health study to deliver personalized mobile health interventions aimed at reducing cannabis use among EAs. reBandit utilizes random effects and informative Bayesian priors to learn quickly and efficiently in noisy mobile health environments. Moreover, reBandit employs Empirical Bayes and optimization techniques to autonomously update its hyper-parameters online. To evaluate the performance of our algorithm, we construct a simulation testbed using data from a prior study, and compare against commonly used algorithms in mobile health studies. We show that reBandit performs equally well or better than all the baseline algorithms, and the performance gap widens as population heterogeneity increases in the simulation environment, proving its adeptness to adapt to diverse population of study participants.
Online Uniform Risk Times Sampling: First Approximation Algorithms, Learning Augmentation with Full Confidence Interval Integration
Feb 07, 2024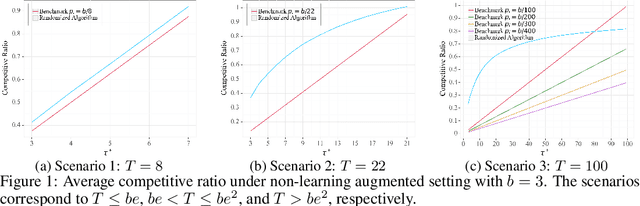
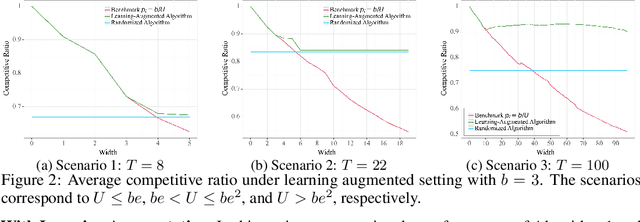
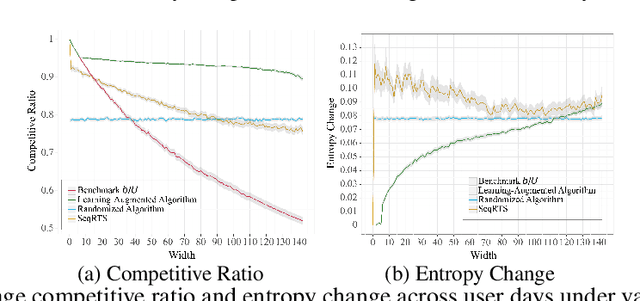
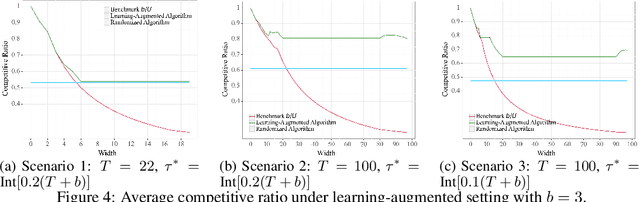
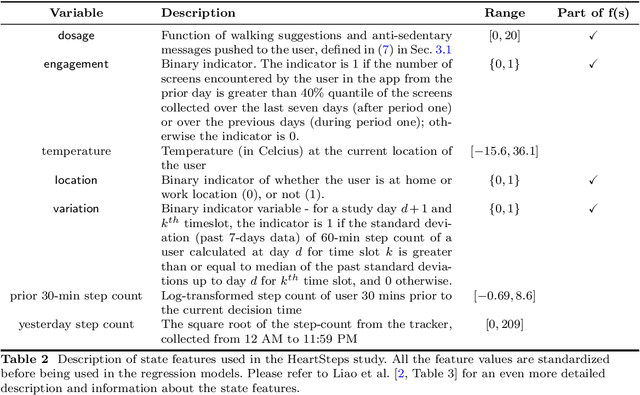
In digital health, the strategy of allocating a limited treatment budget across available risk times is crucial to reduce user fatigue. This strategy, however, encounters a significant obstacle due to the unknown actual number of risk times, a factor not adequately addressed by existing methods lacking theoretical guarantees. This paper introduces, for the first time, the online uniform risk times sampling problem within the approximation algorithm framework. We propose two online approximation algorithms for this problem, one with and one without learning augmentation, and provide rigorous theoretical performance guarantees for them using competitive ratio analysis. We assess the performance of our algorithms using both synthetic experiments and a real-world case study on HeartSteps mobile applications.
Reinforcement Learning Interventions on Boundedly Rational Human Agents in Frictionful Tasks
Jan 26, 2024Many important behavior changes are frictionful; they require individuals to expend effort over a long period with little immediate gratification. Here, an artificial intelligence (AI) agent can provide personalized interventions to help individuals stick to their goals. In these settings, the AI agent must personalize rapidly (before the individual disengages) and interpretably, to help us understand the behavioral interventions. In this paper, we introduce Behavior Model Reinforcement Learning (BMRL), a framework in which an AI agent intervenes on the parameters of a Markov Decision Process (MDP) belonging to a boundedly rational human agent. Our formulation of the human decision-maker as a planning agent allows us to attribute undesirable human policies (ones that do not lead to the goal) to their maladapted MDP parameters, such as an extremely low discount factor. Furthermore, we propose a class of tractable human models that captures fundamental behaviors in frictionful tasks. Introducing a notion of MDP equivalence specific to BMRL, we theoretically and empirically show that AI planning with our human models can lead to helpful policies on a wide range of more complex, ground-truth humans.
Dyadic Reinforcement Learning
Aug 27, 2023Mobile health aims to enhance health outcomes by delivering interventions to individuals as they go about their daily life. The involvement of care partners and social support networks often proves crucial in helping individuals managing burdensome medical conditions. This presents opportunities in mobile health to design interventions that target the dyadic relationship -- the relationship between a target person and their care partner -- with the aim of enhancing social support. In this paper, we develop dyadic RL, an online reinforcement learning algorithm designed to personalize intervention delivery based on contextual factors and past responses of a target person and their care partner. Here, multiple sets of interventions impact the dyad across multiple time intervals. The developed dyadic RL is Bayesian and hierarchical. We formally introduce the problem setup, develop dyadic RL and establish a regret bound. We demonstrate dyadic RL's empirical performance through simulation studies on both toy scenarios and on a realistic test bed constructed from data collected in a mobile health study.
Online learning in bandits with predicted context
Jul 26, 2023We consider the contextual bandit problem where at each time, the agent only has access to a noisy version of the context and the error variance (or an estimator of this variance). This setting is motivated by a wide range of applications where the true context for decision-making is unobserved, and only a prediction of the context by a potentially complex machine learning algorithm is available. When the context error is non-diminishing, classical bandit algorithms fail to achieve sublinear regret. We propose the first online algorithm in this setting with sublinear regret compared to the appropriate benchmark. The key idea is to extend the measurement error model in classical statistics to the online decision-making setting, which is nontrivial due to the policy being dependent on the noisy context observations.
Effect-Invariant Mechanisms for Policy Generalization
Jun 27, 2023Policy learning is an important component of many real-world learning systems. A major challenge in policy learning is how to adapt efficiently to unseen environments or tasks. Recently, it has been suggested to exploit invariant conditional distributions to learn models that generalize better to unseen environments. However, assuming invariance of entire conditional distributions (which we call full invariance) may be too strong of an assumption in practice. In this paper, we introduce a relaxation of full invariance called effect-invariance (e-invariance for short) and prove that it is sufficient, under suitable assumptions, for zero-shot policy generalization. We also discuss an extension that exploits e-invariance when we have a small sample from the test environment, enabling few-shot policy generalization. Our work does not assume an underlying causal graph or that the data are generated by a structural causal model; instead, we develop testing procedures to test e-invariance directly from data. We present empirical results using simulated data and a mobile health intervention dataset to demonstrate the effectiveness of our approach.
Contextual Bandits with Budgeted Information Reveal
May 29, 2023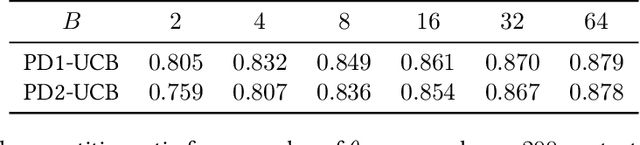
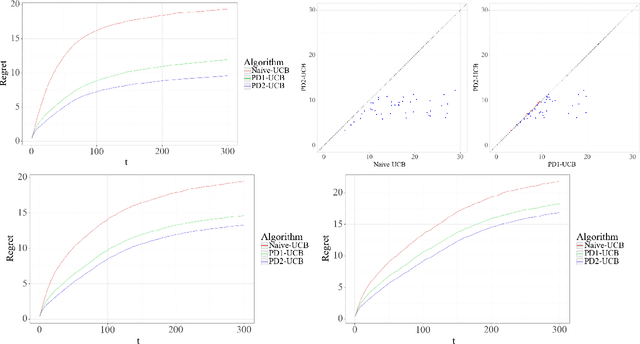
Contextual bandit algorithms are commonly used in digital health to recommend personalized treatments. However, to ensure the effectiveness of the treatments, patients are often requested to take actions that have no immediate benefit to them, which we refer to as pro-treatment actions. In practice, clinicians have a limited budget to encourage patients to take these actions and collect additional information. We introduce a novel optimization and learning algorithm to address this problem. This algorithm effectively combines the strengths of two algorithmic approaches in a seamless manner, including 1) an online primal-dual algorithm for deciding the optimal timing to reach out to patients, and 2) a contextual bandit learning algorithm to deliver personalized treatment to the patient. We prove that this algorithm admits a sub-linear regret bound. We illustrate the usefulness of this algorithm on both synthetic and real-world data.
Did we personalize? Assessing personalization by an online reinforcement learning algorithm using resampling
Apr 24, 2023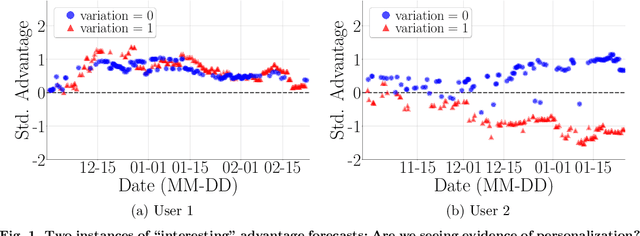
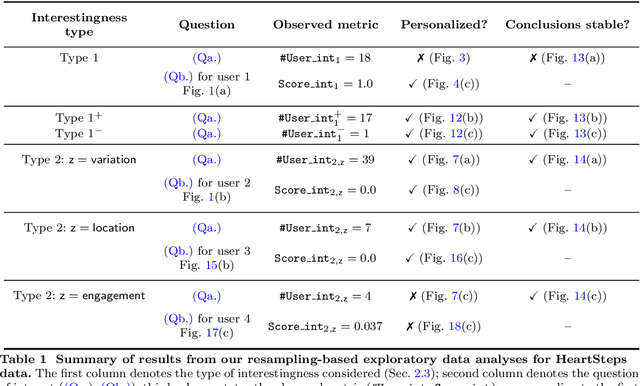
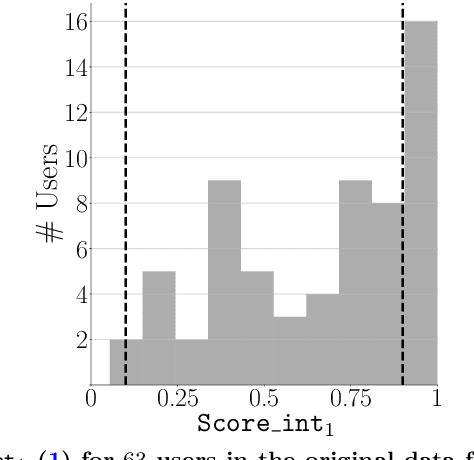
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user's context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user's historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an ``optimized'' intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
Modeling Mobile Health Users as Reinforcement Learning Agents
Dec 01, 2022



Mobile health (mHealth) technologies empower patients to adopt/maintain healthy behaviors in their daily lives, by providing interventions (e.g. push notifications) tailored to the user's needs. In these settings, without intervention, human decision making may be impaired (e.g. valuing near term pleasure over own long term goals). In this work, we formalize this relationship with a framework in which the user optimizes a (potentially impaired) Markov Decision Process (MDP) and the mHealth agent intervenes on the user's MDP parameters. We show that different types of impairments imply different types of optimal intervention. We also provide analytical and empirical explorations of these differences.