 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIBRA: Language Model Informed Bandit Recourse Algorithm for Personalized Treatment Planning
Jan 17, 2026We introduce a unified framework that seamlessly integrates algorithmic recourse, contextual bandits, and large language models (LLMs) to support sequential decision-making in high-stakes settings such as personalized medicine. We first introduce the recourse bandit problem, where a decision-maker must select both a treatment action and a feasible, minimal modification to mutable patient features. To address this problem, we develop the Generalized Linear Recourse Bandit (GLRB) algorithm. Building on this foundation, we propose LIBRA, a Language Model-Informed Bandit Recourse Algorithm that strategically combines domain knowledge from LLMs with the statistical rigor of bandit learning. LIBRA offers three key guarantees: (i) a warm-start guarantee, showing that LIBRA significantly reduces initial regret when LLM recommendations are near-optimal; (ii) an LLM-effort guarantee, proving that the algorithm consults the LLM only $O(\log^2 T)$ times, where $T$ is the time horizon, ensuring long-term autonomy; and (iii) a robustness guarantee, showing that LIBRA never performs worse than a pure bandit algorithm even when the LLM is unreliable. We further establish matching lower bounds that characterize the fundamental difficulty of the recourse bandit problem and demonstrate the near-optimality of our algorithms. Experiments on synthetic environments and a real hypertension-management case study confirm that GLRB and LIBRA improve regret, treatment quality, and sample efficiency compared with standard contextual bandits and LLM-only benchmarks. Our results highlight the promise of recourse-aware, LLM-assisted bandit algorithms for trustworthy LLM-bandits collaboration in personalized high-stakes decision-making.
Deconfounded Warm-Start Thompson Sampling with Applications to Precision Medicine
May 22, 2025Randomized clinical trials often require large patient cohorts before drawing definitive conclusions, yet abundant observational data from parallel studies remains underutilized due to confounding and hidden biases. To bridge this gap, we propose Deconfounded Warm-Start Thompson Sampling (DWTS), a practical approach that leverages a Doubly Debiased LASSO (DDL) procedure to identify a sparse set of reliable measured covariates and combines them with key hidden covariates to form a reduced context. By initializing Thompson Sampling (LinTS) priors with DDL-estimated means and variances on these measured features -- while keeping uninformative priors on hidden features -- DWTS effectively harnesses confounded observational data to kick-start adaptive clinical trials. Evaluated on both a purely synthetic environment and a virtual environment created using real cardiovascular risk dataset, DWTS consistently achieves lower cumulative regret than standard LinTS, showing how offline causal insights from observational data can improve trial efficiency and support more personalized treatment decisions.
HR-Bandit: Human-AI Collaborated Linear Recourse Bandit
Oct 18, 2024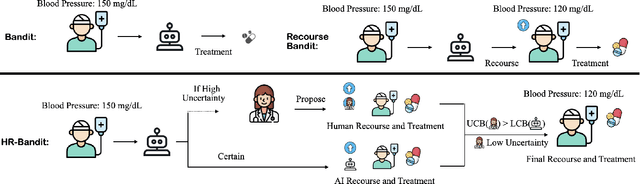
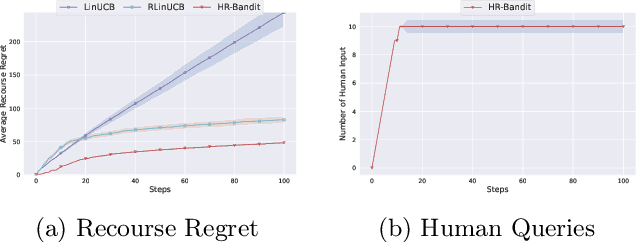
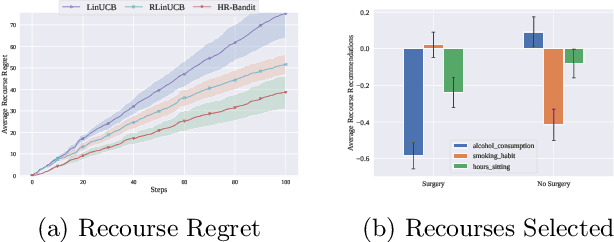
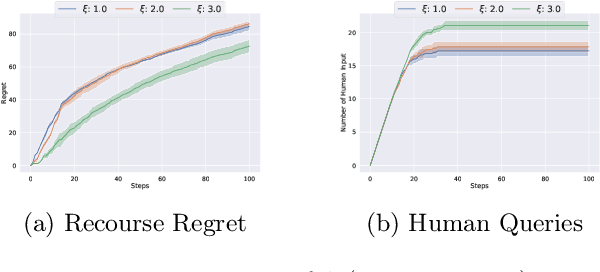
Human doctors frequently recommend actionable recourses that allow patients to modify their conditions to access more effective treatments. Inspired by such healthcare scenarios, we propose the Recourse Linear UCB ($\textsf{RLinUCB}$) algorithm, which optimizes both action selection and feature modifications by balancing exploration and exploitation. We further extend this to the Human-AI Linear Recourse Bandit ($\textsf{HR-Bandit}$), which integrates human expertise to enhance performance. $\textsf{HR-Bandit}$ offers three key guarantees: (i) a warm-start guarantee for improved initial performance, (ii) a human-effort guarantee to minimize required human interactions, and (iii) a robustness guarantee that ensures sublinear regret even when human decisions are suboptimal. Empirical results, including a healthcare case study, validate its superior performance against existing benchmarks.
Online Uniform Risk Times Sampling: First Approximation Algorithms, Learning Augmentation with Full Confidence Interval Integration
Feb 07, 2024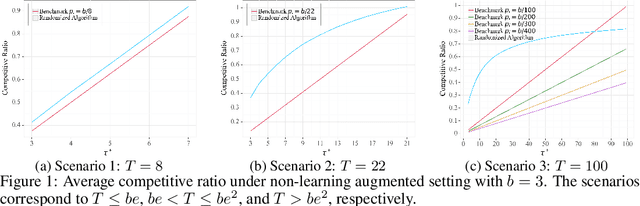
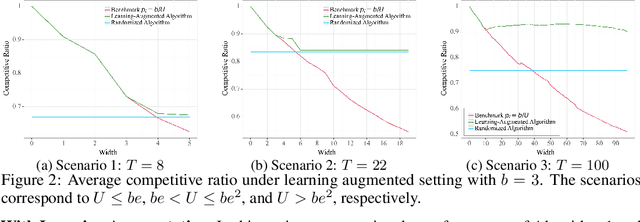
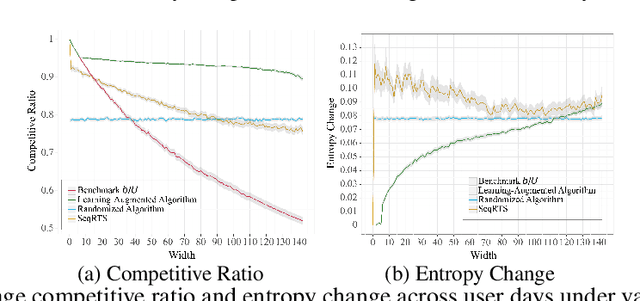
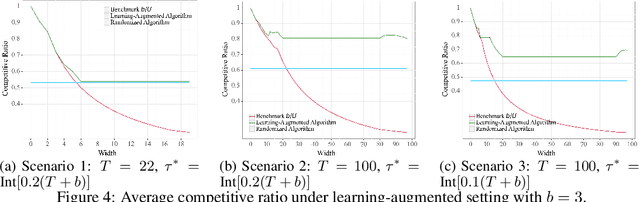
In digital health, the strategy of allocating a limited treatment budget across available risk times is crucial to reduce user fatigue. This strategy, however, encounters a significant obstacle due to the unknown actual number of risk times, a factor not adequately addressed by existing methods lacking theoretical guarantees. This paper introduces, for the first time, the online uniform risk times sampling problem within the approximation algorithm framework. We propose two online approximation algorithms for this problem, one with and one without learning augmentation, and provide rigorous theoretical performance guarantees for them using competitive ratio analysis. We assess the performance of our algorithms using both synthetic experiments and a real-world case study on HeartSteps mobile applications.
Contextual Bandits with Budgeted Information Reveal
May 29, 2023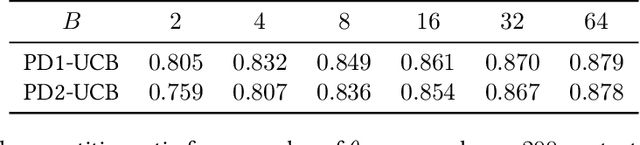
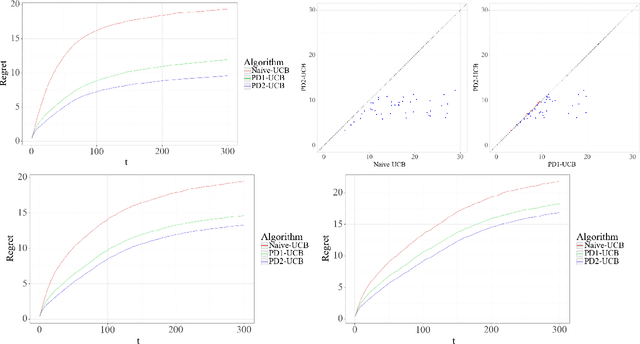
Contextual bandit algorithms are commonly used in digital health to recommend personalized treatments. However, to ensure the effectiveness of the treatments, patients are often requested to take actions that have no immediate benefit to them, which we refer to as pro-treatment actions. In practice, clinicians have a limited budget to encourage patients to take these actions and collect additional information. We introduce a novel optimization and learning algorithm to address this problem. This algorithm effectively combines the strengths of two algorithmic approaches in a seamless manner, including 1) an online primal-dual algorithm for deciding the optimal timing to reach out to patients, and 2) a contextual bandit learning algorithm to deliver personalized treatment to the patient. We prove that this algorithm admits a sub-linear regret bound. We illustrate the usefulness of this algorithm on both synthetic and real-world data.