 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Controlled Scheduling for LLM Inference with Provable Stability Guarantees
Apr 13, 2026Large language models (LLMs) have been widely adopted due to their great performance across a wide range of applications. ChatGPT and Gemini now serve hundreds of millions of active users and handle billions of user requests per day, which puts optimizing LLM inference into the spotlight. A key challenge in LLM inference is that decode lengths are unknown. The memory usage for each request grows with generated tokens, which may lead to overflow and cause system instability. To address this concern, we propose a simple flow-control framework that controls the rate at which prompts join the active set. We derive a necessary condition that any stable system must satisfy and establish sufficient conditions under which our algorithm provably achieves stability. Experiments show that, compared to commonly used strategies in practice, our approach achieves higher token and request throughput, lower average and tail latency, and more stable KV cache utilization.
Adaptive Combinatorial Experimental Design: Pareto Optimality for Decision-Making and Inference
Feb 27, 2026In this paper, we provide the first investigation into adaptive combinatorial experimental design, focusing on the trade-off between regret minimization and statistical power in combinatorial multi-armed bandits (CMAB). While minimizing regret requires repeated exploitation of high-reward arms, accurate inference on reward gaps requires sufficient exploration of suboptimal actions. We formalize this trade-off through the concept of Pareto optimality and establish equivalent conditions for Pareto-efficient learning in CMAB. We consider two relevant cases under different information structures, i.e., full-bandit feedback and semi-bandit feedback, and propose two algorithms MixCombKL and MixCombUCB respectively for these two cases. We provide theoretical guarantees showing that both algorithms are Pareto optimal, achieving finite-time guarantees on both regret and estimation error of arm gaps. Our results further reveal that richer feedback significantly tightens the attainable Pareto frontier, with the primary gains arising from improved estimation accuracy under our proposed methods. Taken together, these findings establish a principled framework for adaptive combinatorial experimentation in multi-objective decision-making.
LIBRA: Language Model Informed Bandit Recourse Algorithm for Personalized Treatment Planning
Jan 17, 2026We introduce a unified framework that seamlessly integrates algorithmic recourse, contextual bandits, and large language models (LLMs) to support sequential decision-making in high-stakes settings such as personalized medicine. We first introduce the recourse bandit problem, where a decision-maker must select both a treatment action and a feasible, minimal modification to mutable patient features. To address this problem, we develop the Generalized Linear Recourse Bandit (GLRB) algorithm. Building on this foundation, we propose LIBRA, a Language Model-Informed Bandit Recourse Algorithm that strategically combines domain knowledge from LLMs with the statistical rigor of bandit learning. LIBRA offers three key guarantees: (i) a warm-start guarantee, showing that LIBRA significantly reduces initial regret when LLM recommendations are near-optimal; (ii) an LLM-effort guarantee, proving that the algorithm consults the LLM only $O(\log^2 T)$ times, where $T$ is the time horizon, ensuring long-term autonomy; and (iii) a robustness guarantee, showing that LIBRA never performs worse than a pure bandit algorithm even when the LLM is unreliable. We further establish matching lower bounds that characterize the fundamental difficulty of the recourse bandit problem and demonstrate the near-optimality of our algorithms. Experiments on synthetic environments and a real hypertension-management case study confirm that GLRB and LIBRA improve regret, treatment quality, and sample efficiency compared with standard contextual bandits and LLM-only benchmarks. Our results highlight the promise of recourse-aware, LLM-assisted bandit algorithms for trustworthy LLM-bandits collaboration in personalized high-stakes decision-making.
Deconfounded Warm-Start Thompson Sampling with Applications to Precision Medicine
May 22, 2025Randomized clinical trials often require large patient cohorts before drawing definitive conclusions, yet abundant observational data from parallel studies remains underutilized due to confounding and hidden biases. To bridge this gap, we propose Deconfounded Warm-Start Thompson Sampling (DWTS), a practical approach that leverages a Doubly Debiased LASSO (DDL) procedure to identify a sparse set of reliable measured covariates and combines them with key hidden covariates to form a reduced context. By initializing Thompson Sampling (LinTS) priors with DDL-estimated means and variances on these measured features -- while keeping uninformative priors on hidden features -- DWTS effectively harnesses confounded observational data to kick-start adaptive clinical trials. Evaluated on both a purely synthetic environment and a virtual environment created using real cardiovascular risk dataset, DWTS consistently achieves lower cumulative regret than standard LinTS, showing how offline causal insights from observational data can improve trial efficiency and support more personalized treatment decisions.
LiteWebAgent: The Open-Source Suite for VLM-Based Web-Agent Applications
Mar 04, 2025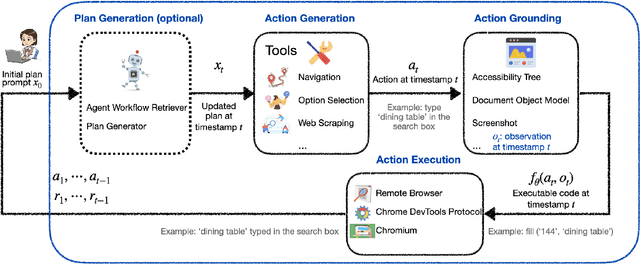



We introduce LiteWebAgent, an open-source suite for VLM-based web agent applications. Our framework addresses a critical gap in the web agent ecosystem with a production-ready solution that combines minimal serverless backend configuration, intuitive user and browser interfaces, and extensible research capabilities in agent planning, memory, and tree search. For the core LiteWebAgent agent framework, we implemented a simple yet effective baseline using recursive function calling, providing with decoupled action generation and action grounding. In addition, we integrate advanced research components such as agent planning, agent workflow memory, and tree search in a modular and extensible manner. We then integrate the LiteWebAgent agent framework with frontend and backend as deployed systems in two formats: (1) a production Vercel-based web application, which provides users with an agent-controlled remote browser, (2) a Chrome extension leveraging LiteWebAgent's API to control an existing Chrome browser via CDP (Chrome DevTools Protocol). The LiteWebAgent framework is available at https://github.com/PathOnAI/LiteWebAgent, with deployed frontend at https://lite-web-agent.vercel.app/.
A Conformal Approach to Feature-based Newsvendor under Model Misspecification
Dec 17, 2024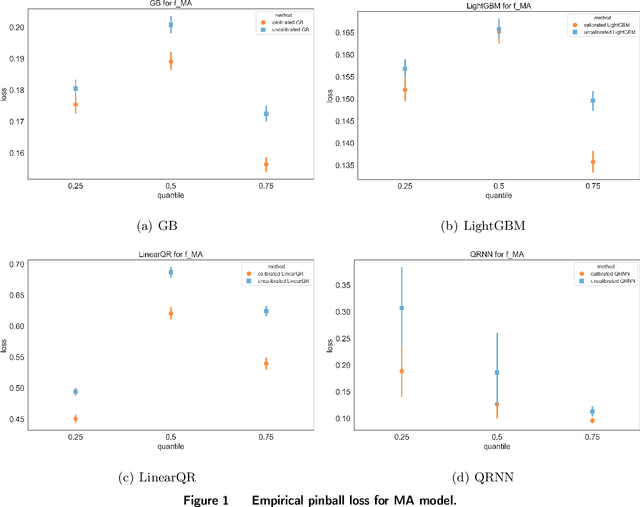
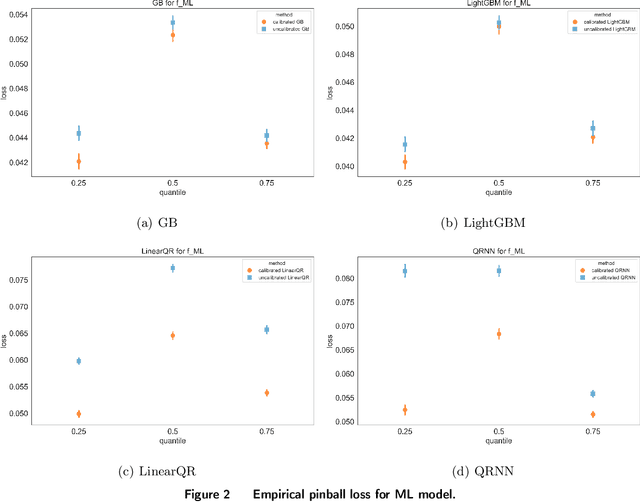
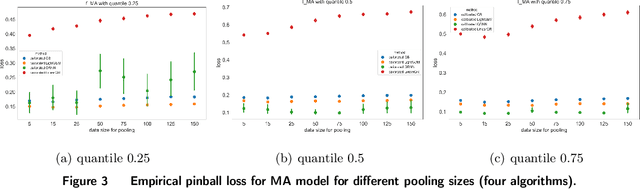
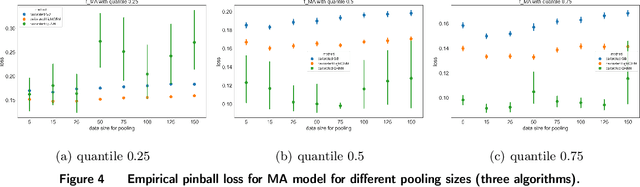
In many data-driven decision-making problems, performance guarantees often depend heavily on the correctness of model assumptions, which may frequently fail in practice. We address this issue in the context of a feature-based newsvendor problem, where demand is influenced by observed features such as demographics and seasonality. To mitigate the impact of model misspecification, we propose a model-free and distribution-free framework inspired by conformal prediction. Our approach consists of two phases: a training phase, which can utilize any type of prediction method, and a calibration phase that conformalizes the model bias. To enhance predictive performance, we explore the balance between data quality and quantity, recognizing the inherent trade-off: more selective training data improves quality but reduces quantity. Importantly, we provide statistical guarantees for the conformalized critical quantile, independent of the correctness of the underlying model. Moreover, we quantify the confidence interval of the critical quantile, with its width decreasing as data quality and quantity improve. We validate our framework using both simulated data and a real-world dataset from the Capital Bikeshare program in Washington, D.C. Across these experiments, our proposed method consistently outperforms benchmark algorithms, reducing newsvendor loss by up to 40% on the simulated data and 25% on the real-world dataset.
HR-Bandit: Human-AI Collaborated Linear Recourse Bandit
Oct 18, 2024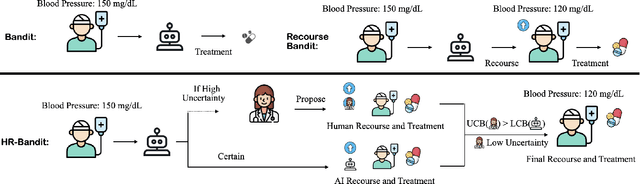
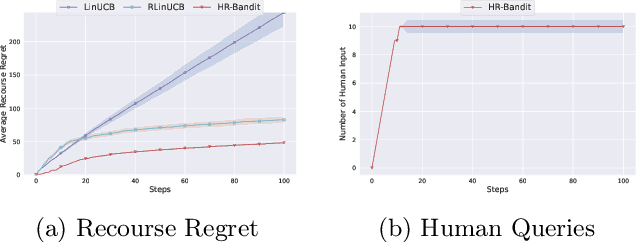
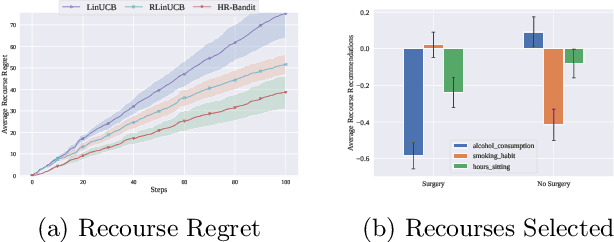
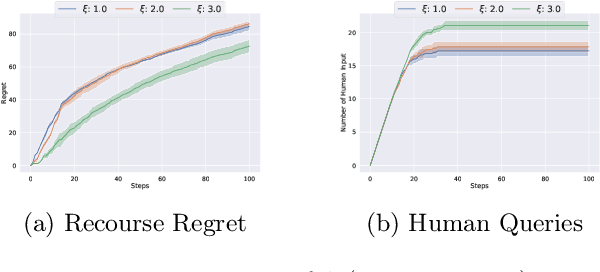
Human doctors frequently recommend actionable recourses that allow patients to modify their conditions to access more effective treatments. Inspired by such healthcare scenarios, we propose the Recourse Linear UCB ($\textsf{RLinUCB}$) algorithm, which optimizes both action selection and feature modifications by balancing exploration and exploitation. We further extend this to the Human-AI Linear Recourse Bandit ($\textsf{HR-Bandit}$), which integrates human expertise to enhance performance. $\textsf{HR-Bandit}$ offers three key guarantees: (i) a warm-start guarantee for improved initial performance, (ii) a human-effort guarantee to minimize required human interactions, and (iii) a robustness guarantee that ensures sublinear regret even when human decisions are suboptimal. Empirical results, including a healthcare case study, validate its superior performance against existing benchmarks.
A Probabilistic Approach for Alignment with Human Comparisons
Mar 16, 2024

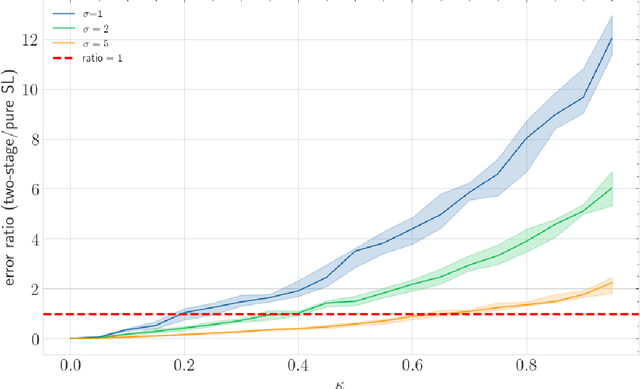
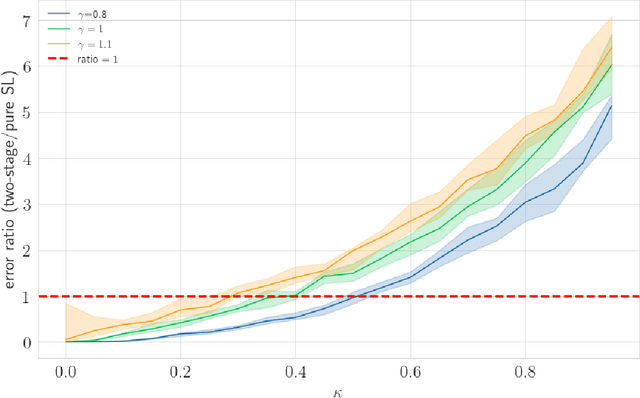
A growing trend involves integrating human knowledge into learning frameworks, leveraging subtle human feedback to refine AI models. Despite these advances, no comprehensive theoretical framework describing the specific conditions under which human comparisons improve the traditional supervised fine-tuning process has been developed. To bridge this gap, this paper studies the effective use of human comparisons to address limitations arising from noisy data and high-dimensional models. We propose a two-stage "Supervised Fine Tuning+Human Comparison" (SFT+HC) framework connecting machine learning with human feedback through a probabilistic bisection approach. The two-stage framework first learns low-dimensional representations from noisy-labeled data via an SFT procedure, and then uses human comparisons to improve the model alignment. To examine the efficacy of the alignment phase, we introduce a novel concept termed the "label-noise-to-comparison-accuracy" (LNCA) ratio. This paper theoretically identifies the conditions under which the "SFT+HC" framework outperforms pure SFT approach, leveraging this ratio to highlight the advantage of incorporating human evaluators in reducing sample complexity. We validate that the proposed conditions for the LNCA ratio are met in a case study conducted via an Amazon Mechanical Turk experiment.
Speed Up the Cold-Start Learning in Two-Sided Bandits with Many Arms
Oct 01, 2022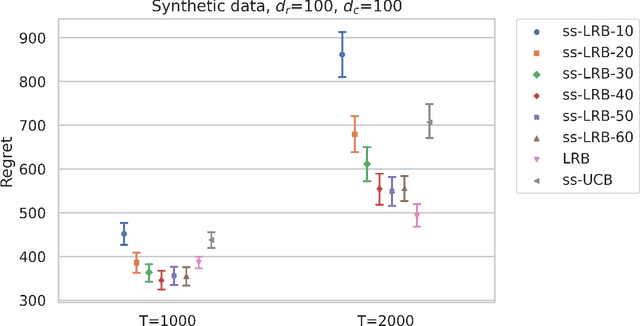
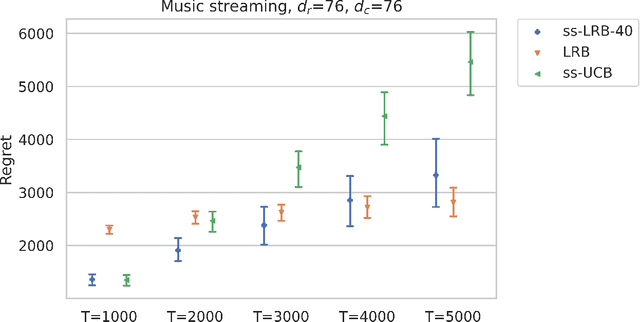
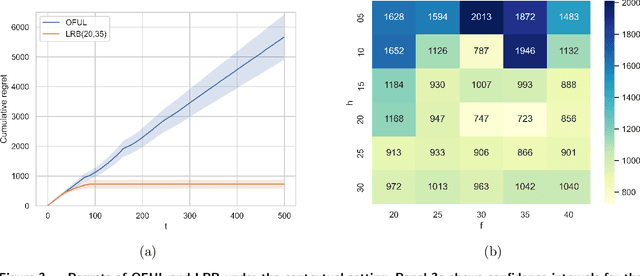
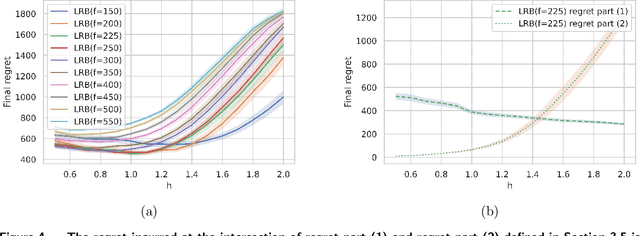
Multi-armed bandit (MAB) algorithms are efficient approaches to reduce the opportunity cost of online experimentation and are used by companies to find the best product from periodically refreshed product catalogs. However, these algorithms face the so-called cold-start at the onset of the experiment due to a lack of knowledge of customer preferences for new products, requiring an initial data collection phase known as the burning period. During this period, MAB algorithms operate like randomized experiments, incurring large burning costs which scale with the large number of products. We attempt to reduce the burning by identifying that many products can be cast into two-sided products, and then naturally model the rewards of the products with a matrix, whose rows and columns represent the two sides respectively. Next, we design two-phase bandit algorithms that first use subsampling and low-rank matrix estimation to obtain a substantially smaller targeted set of products and then apply a UCB procedure on the target products to find the best one. We theoretically show that the proposed algorithms lower costs and expedite the experiment in cases when there is limited experimentation time along with a large product set. Our analysis also reveals three regimes of long, short, and ultra-short horizon experiments, depending on dimensions of the matrix. Empirical evidence from both synthetic data and a real-world dataset on music streaming services validates this superior performance.
Fatigue-aware Bandits for Dependent Click Models
Aug 22, 2020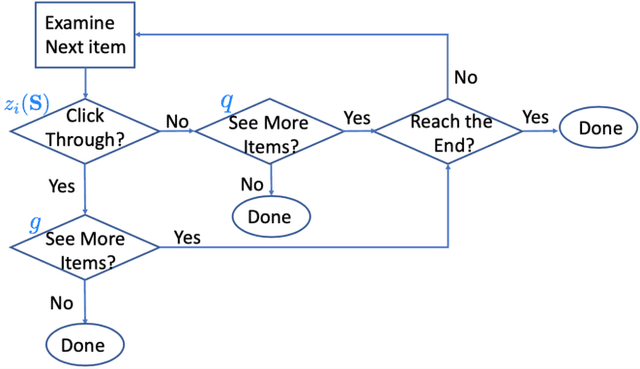
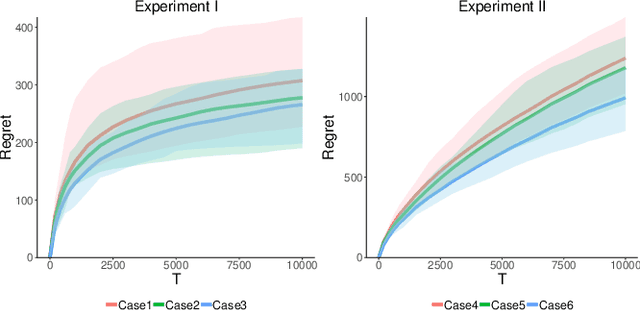
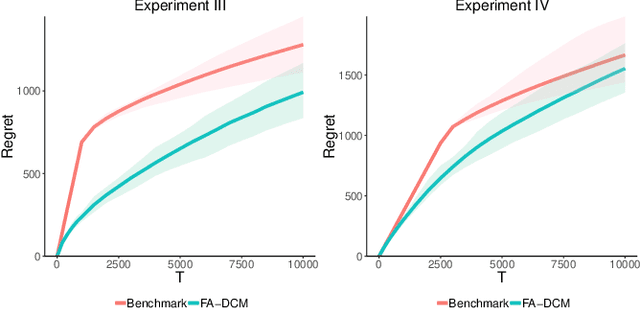
As recommender systems send a massive amount of content to keep users engaged, users may experience fatigue which is contributed by 1) an overexposure to irrelevant content, 2) boredom from seeing too many similar recommendations. To address this problem, we consider an online learning setting where a platform learns a policy to recommend content that takes user fatigue into account. We propose an extension of the Dependent Click Model (DCM) to describe users' behavior. We stipulate that for each piece of content, its attractiveness to a user depends on its intrinsic relevance and a discount factor which measures how many similar contents have been shown. Users view the recommended content sequentially and click on the ones that they find attractive. Users may leave the platform at any time, and the probability of exiting is higher when they do not like the content. Based on user's feedback, the platform learns the relevance of the underlying content as well as the discounting effect due to content fatigue. We refer to this learning task as "fatigue-aware DCM Bandit" problem. We consider two learning scenarios depending on whether the discounting effect is known. For each scenario, we propose a learning algorithm which simultaneously explores and exploits, and characterize its regret bound.